深度学习中的经典基础网络结构总结
转载自:深度学习中的经典基础网络结构(backbone)总结
文章目录
- 一、深度学习中的经典基础网络结构总结
-
- 1. 深度学习发展历史回顾
- 2. 深度学习中的经典基础网络结构概览
- 3.经典backbone解读
-
- 3.1 AlexNet
- 3.2 VGG-16/19
- 3.3 GoogLeNet/Inception
- 3.4 ResNet
- 3.5 SqueezeNet
- 3.6 MobileNet V1
- 3.7 ShuffleNet V1
- 二、结语
一、深度学习中的经典基础网络结构总结
这篇文章从大的发展趋势介绍了下主干网络的发展,而在 CV 经典主干网络 (Backbone) 系列: 开篇 中主要是对一些比较经典的主干网络进行简单梳理。
1. 深度学习发展历史回顾

在开始正式内容之前,首先回顾下深度学习发展史,这将使整体内容更为连贯。
上图主要展示了深度学习的 “史前文明”(这里仅仅是开玩笑的说法)。从图中可以看到整个历史始于1943年,有三个发展繁荣期和两个低谷。
-
- 1943年,心理学家麦卡洛克和数学逻辑学家皮兹发表论文《神经活动中内在思想的逻辑演算》,提出了MP模型。
-
- 1960年,Henry J. Kelley 提出 BP(Back propagation),但是还仅仅应用有控制理论中。
-
- 1965年,Alexey Grigoryevich Ivakhnenko(开发了数据处理的分组方法)和Valentin Grigor_evich Lapa(控制论和预测技术的作者)在开发深度学习算法方面做出了最早的努力。
-
- 经过第一个高潮的发展,大家对深度学习充满了期待,但是结果却远远未达到预期,所以各国政府削减资助,投资人也减少投资, 上世纪70年代,第一个 AI 寒冬到来了,AI 的研究也进入了低谷期。第一次寒冬主要是从理论到数据到算力都不能满足要求。
-
- 1979年,Kunihiko Fukushima 开始将 CNN 应用于神经网络中。由于一些人的坚持,深度学习又开始有了巨大发展。
-
- 1985年,Rumelhart, Williams, 和 Hinton 证明 BP 在神经网络的作用,由此 BP 才开启了它的神经网络之旅。历史总是惊人的相似,在外界对 AI 抱有巨大希望的时候,泡沫再次破裂了, 第二次 AI 寒冬到来。第二次寒冬主要是受限于数据和算力。
-
- 1989年,第一个用于解决实际问题的网络(LeCun1989)由 Yann LeCun 于贝尔实验室提出,用于识别手写数字,当然这个还不是我们所熟知的 LeNet5, 后者是1998年才提出的。
-
- 1995年,Dana Cortes 和 Vladimir Vapnik 提出了 SVM 。1997年,Sepp Hochreiter 和 Juergen Schmidhuber 提出了 LSTM。
-
- 1999年,当时计算机处理数据的速度开始加快,gpu(图形处理单元)也得到了发展。通过GPU处理图片,在10年的时间里,计算速度提高了1000倍。这为 AI 的第三次繁荣奠定了基础。
当然现在有一个说法是 AI 已经处在第三次寒冬,理由是深度学习的潜力已经见顶,这个我们且不讨论。
2. 深度学习中的经典基础网络结构概览
上面已经讲到2000年左右,随着理论的完善和算力的巨大发展, 深度学习进入了第三次繁荣,而我们将介绍的经典网络结构也都产生于这一时期。
下面以 AlexNet 作为起点,梳理了一些经典基础网络结构,需要注意的是,这里并不包含那些具有特殊功能的网络,比如专门用于检测的 SSD, 专门用于分割的 FCN 等等之类的网络。这里所指的网络是可以作为 backbone 的基础网络结构。
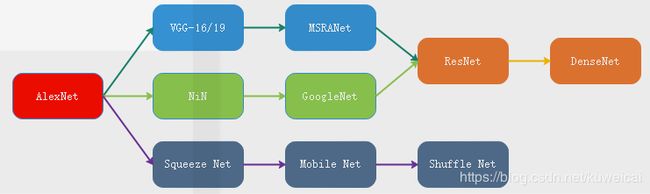
上面这幅图是以三种不同的发展思路来进行分类的。如下所示。
-
- 第一行是按着如何使网络结构更深的发展思路来进行推进的。
-
- 第二行是在玩 module 的概念,当然我们看到第一行和第二行后面是被结合到一起了的。
-
- 第三条是按着如何使网络更快,结构更轻量化来进行发展的。这里仅仅只是列出了一些比较经典的网络,而且每种网络都有多个版本。下图是轻量化网络更详细的发展情况。

如果我们以 ImageNet 的成绩作为线索进行排列,如下图所示。

- 第三条是按着如何使网络更快,结构更轻量化来进行发展的。这里仅仅只是列出了一些比较经典的网络,而且每种网络都有多个版本。下图是轻量化网络更详细的发展情况。
从上图我们可以发现,从2011年到2016,经历了几次里程碑式的发展。
-
- 2012年,AlexNet 的成绩有质的飞跃,这主要是因为和前面的相比,CNN 的引入带来的巨大进步。
-
- 2014年,VGGNet 将错误率降到10以下,网络的层数也是突破了个位数,达到16-19层。
-
- 2015年,ResNet 首次将错误率降到比人类还低的水平。
下面我们就一些比较重要的网络进行具体的讨论。
3.经典backbone解读
3.1 AlexNet
在 Dropout 和 Relu 被提出之后,2012年 AlexNet 诞生了。AlexNet的论文被认为是 CV 界最有影响力的论文之一,截至2019年,已经被引约47000次,其影响力可见一斑。AlexNet 是第一个真正意义上影响了后面 CNN 发展的一个经典网络。
AlexNet 的突破点主要有
-
- 网络更大更深,LeNet5(具体可以参考动图详细讲解 LeNet-5 网络结构) 有 2 层卷积 + 3 层全连接层,有大概6万个参数,而AlexNet 有 5 层卷积 + 3 层全连接,有6000万个参数和65000个神经元。
-
- 使用 ReLU 作为激活函数, LeNet5 用的是 Sigmoid,虽然 ReLU 并不是 Alex 提出来的,但是正是这次机会让 ReLU C位出道,一炮而红。关于激活函数请参考我的另一篇博客 深度神经网络中常用的激活函数的优缺点分析。AlexNet 可以采用更深的网络和使用 ReLU 是息息相关的。
-
- 使用 数据增强 和 dropout 来解决过拟合问题。在数据增强部分使用了现在已经家喻户晓的技术,比如 crop,PCA,加高斯噪声等。而 dropout 也被证明是非常有效的防止过拟合的手段。
-
- 用最大池化取代平均池化,避免平均池化的模糊化效果, 并且在池化的时候让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
-
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
3.2 VGG-16/19
VGGNet 由 Karen Simonyan 等于2014年 在 Very Deep Convolutional Networks for Large-Scale Image Recognition中提出。这个模型在当年的 ImageNet 挑战赛上分别取得了检测和分类任务的第一和第二名。第二名?对,第一名是下面的 GoogLeNet。
下图是论文中提出的几种对比模型, 其中 D 和 E 分别就是顶顶大名的 VGG16 和 VGG19。整体结构上还是遵循了 input->n*(Conv->ReLU->Max Pool)->3*fc->outpput 的结构。
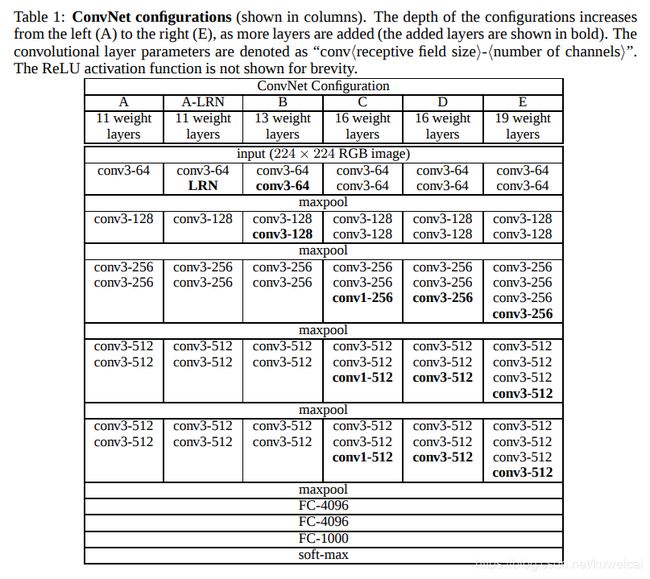
下面我们来看下 VGG 所取得的突破。
-
- 在当年的 ImageNet 挑战赛上刷新了成绩,而且是较之前的网络取得了非常大的进步。
-
- 将错误率降到10以下,网络的层数也是突破了个位数,达到16-19。
-
- 选用比较小的卷积核(3x3),而之前无论 AlexNet 还是 LeNet5 都是采用较大的卷积核,比如 11x11, 7x7。而采用小卷积核的意义主要有两点,一是在取得相同的感受野的情况下,比如两个3x3的感受野和一个5x5的感受野的大小相同,但是计算量却小了很多,关于这点原文中有很详细的解释,建议直接看原文;第二点是两层3x3相比一层5x5可以引入更多的非线性,从而使模型的拟合能力更强,这点作者也通过实验进行了证明。其实这里还有一个优点就是采用小的卷积核更方便优化卷积计算,比如Winograd算法对小核的卷积操作有比较好的优化效果。
-
- 使用1x1的卷积核在不影响输入输出的维度情况下,通过ReLU进行非线性处理,提高模型的非线性。当然这个并非 VGGNet 首创,最先在 Network In Network中提出。
-
- 证明提高网络的深度能提高精度。
VGGNet16 和 VGGNet19 的效果相当,但是 VGGNet16 的结构更简洁美观,因此 VGGNet16 应用的更为广泛一些。
3.3 GoogLeNet/Inception
GoogLeNet 由 Christian Szegedy 等于 2014年发表在 Going Deeper with Convolutions上。
细心的同学肯定已经发现了,这个网络的名字有点奇怪,好好的 Google 为什么写成 GoogLe, 作者说是为了致敬 LeNet。GoogLeNet 也参加了2014年的 ImageNet 挑战赛,并取得第一名的成绩。GoogLeNet 前后有4个版本,这里说的 GoogLeNet 其实是指的 v1。
GoogLeNet 取得的突破主要有:
-
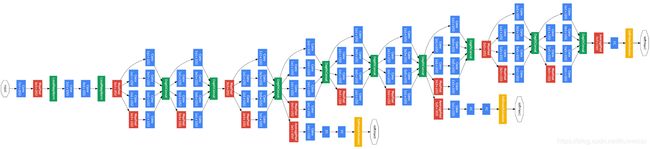
- 在网络结构上与之前的网络结构有比较大的差异,而且深度也达到了22层。在 GoogLeNet 上开始出现了分支,而不是一条线连到底,这是最直观的差异,也被称作 Inception module,如下图所示。从图中可以看到, 每个 module 中采用了不同 size 的 kernel,然后在将特征图叠加,实际上起到了一个图像金字塔的作用,即 所谓的 multiple resolution。

- 在网络结构上与之前的网络结构有比较大的差异,而且深度也达到了22层。在 GoogLeNet 上开始出现了分支,而不是一条线连到底,这是最直观的差异,也被称作 Inception module,如下图所示。从图中可以看到, 每个 module 中采用了不同 size 的 kernel,然后在将特征图叠加,实际上起到了一个图像金字塔的作用,即 所谓的 multiple resolution。
-
- 上图中有很多 1x1 的卷积核,这里的1x1的卷积操作与之前讲到是不一样的,这里利用它来改变 output 的 channel, 具体说这里是减少 channel 数,从而达到减少计算的目的。
-
- 用 Global Ave Pool 取代 FC。下图可以看到,对于 FC ,超参数的个数为 7x7x1024x1024=51.3M,但是换成 Ave Pool之后,超参数变为0,所以这里可以起到防止过拟合的作用,另外作者发现采用 Ave Pool 之后,top-1的精度提高了大概0.6%。但是需要注意的是,在 GoogLeNet 中并没有完全取代 FC。

- 用 Global Ave Pool 取代 FC。下图可以看到,对于 FC ,超参数的个数为 7x7x1024x1024=51.3M,但是换成 Ave Pool之后,超参数变为0,所以这里可以起到防止过拟合的作用,另外作者发现采用 Ave Pool 之后,top-1的精度提高了大概0.6%。但是需要注意的是,在 GoogLeNet 中并没有完全取代 FC。
-
- 采用了辅助分类器。整个模型有三个 output(之前的网络都只有一个 output),这里的多个 output 仅仅在训练的时候用,也就是说测试或者部署的时候仅仅用最后一个输出。在训练的时候,将三个输出的loss进行加权平均,weight=0.3, 通过这种方式可以缓解梯度消失,同时作者也表示有正则化的作用。其实这个思想有点类似于传统机器学习中的投票机制,最终的结果由多个决策器共同投票决定,这个在传统机器学习中往往能提升大概2%的精度。
- 采用了辅助分类器。整个模型有三个 output(之前的网络都只有一个 output),这里的多个 output 仅仅在训练的时候用,也就是说测试或者部署的时候仅仅用最后一个输出。在训练的时候,将三个输出的loss进行加权平均,weight=0.3, 通过这种方式可以缓解梯度消失,同时作者也表示有正则化的作用。其实这个思想有点类似于传统机器学习中的投票机制,最终的结果由多个决策器共同投票决定,这个在传统机器学习中往往能提升大概2%的精度。
关于 GoogLeNet 的更多讲解可以参考 Review: GoogLeNet (Inception v1)— Winner of ILSVRC 2014 (Image Classification)。关于 GoogLeNet 其他版本的讲解可以参考 大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)。
3.4 ResNet
ResNet 是何凯明于2015年在Deep Residual Learning for Image Recognition提出的。这个应该是凯明续 dark channel 之后的又一杰作。我们之前提 ResNet 将深度学习推到了新的高度,因为它首次将错误率降到比人类还低的水平,网络深度甚至达到1202层,所以它具有里程碑式的意义。文章中作者提出了多种不同深度的结构,其中50,101和152层的网络后来用的比较多。由于 ResNet 取得了惊人的成绩,研究者们蜂拥而至,ResNet 被不断推进,多种变种网络被提出。这里仅仅针对 ResNet 的原始版本进行讲解。
下面我们来具体看看 ResNet 的创新点。
-
- ResNet 的核心思想是采用了 identity shortcut connection。前面我们提到,已经得出了结论,加深网络深度有助于提高模型精度,那什么不直接干到几千几万层?这里的原因很多,抛开计算资源和数据集的原因,还有一个很重要的原因是梯度消失。在最开始,比如在 LeNet 那个年代,也就几层网络,当网络更深的时候便会出现精度不升反降的现象,后来我们知道是因为梯度下降导致学习率下降甚至停滞,而到了 VGG 和 GoogLeNet 的年代,我们有了 ReLU,有了更好的初始化方法,有了 BN,但是如下面第一幅图所示,当深度达到50多层时,问题又出现了了,所以激活函数或者初始化方法仅仅是缓解了梯度消失,让网络的深度从几层推移到了二十多层,而如何让网络更深,正是 ResNet 被提出的原因。GoogLeNet 中我们提到采用辅助分类器的方式来解决梯度消失的问题,而 ResNet 是另一种思路,虽然这个思路并非由凯明首创,但是确实取得了很好的效果。这个应该比较好理解,因为 shortcut 的存在,因此有 assemble 的效果,如下面第二幅图所示。


- ResNet 的核心思想是采用了 identity shortcut connection。前面我们提到,已经得出了结论,加深网络深度有助于提高模型精度,那什么不直接干到几千几万层?这里的原因很多,抛开计算资源和数据集的原因,还有一个很重要的原因是梯度消失。在最开始,比如在 LeNet 那个年代,也就几层网络,当网络更深的时候便会出现精度不升反降的现象,后来我们知道是因为梯度下降导致学习率下降甚至停滞,而到了 VGG 和 GoogLeNet 的年代,我们有了 ReLU,有了更好的初始化方法,有了 BN,但是如下面第一幅图所示,当深度达到50多层时,问题又出现了了,所以激活函数或者初始化方法仅仅是缓解了梯度消失,让网络的深度从几层推移到了二十多层,而如何让网络更深,正是 ResNet 被提出的原因。GoogLeNet 中我们提到采用辅助分类器的方式来解决梯度消失的问题,而 ResNet 是另一种思路,虽然这个思路并非由凯明首创,但是确实取得了很好的效果。这个应该比较好理解,因为 shortcut 的存在,因此有 assemble 的效果,如下面第二幅图所示。
-
- 下图对比了 VGG-19 和 34层的 ResNet,可以看到 ResNet 的 kernel channel 比 VGG-19 少很多,另一个就是 ResNet 中已经没有 FC 了, 而是用的 Ave Pool,这点在 GoogLeNet 中已经提到过。下面的 VGG-19 的 FLOPs 是 19.6 biliion, 而下面的 34 层的 ResNet 仅仅只有3.6 billion,即使是152层的 ResNet152 也才 11.6 billion。另外还可以发现在 ResNet 中只有开头和结尾的位置有 pooling 层,中间是没有的,这是因为 ResNet 中间采用了 stride 为2的卷积操作,取代了 pooling 层的作用。

- 下图对比了 VGG-19 和 34层的 ResNet,可以看到 ResNet 的 kernel channel 比 VGG-19 少很多,另一个就是 ResNet 中已经没有 FC 了, 而是用的 Ave Pool,这点在 GoogLeNet 中已经提到过。下面的 VGG-19 的 FLOPs 是 19.6 biliion, 而下面的 34 层的 ResNet 仅仅只有3.6 billion,即使是152层的 ResNet152 也才 11.6 billion。另外还可以发现在 ResNet 中只有开头和结尾的位置有 pooling 层,中间是没有的,这是因为 ResNet 中间采用了 stride 为2的卷积操作,取代了 pooling 层的作用。
另外上图中需要注意的是,shortcut 有虚线和实线之分,实际上虚线的地方是因为用了 stride 为2的conv,因此虚线连接的 input 和 output 的 size 是不一样大的,因此没法直接进行 element wise addition,所以虚线表示并非是直接相连,而是通过了一个 conv 去完成了 resize 的操作,是相加的两个输入有相同的 size。
还一点是,之前在 VGG 和 GoogLeNet 中都采用3x3的conv,但是我们看到在 ResNet 中又用回了7x7的 conv。上图中 VGG-19用的4个 3x3, 而 ResNet 用的一个 7x7, 我觉得主要还是因为 ResNet 的 channel 数比较小,因此大的 kernel size 也不会使计算量变的很大(和 VGG-19 的4个 conv 比,计算量更小),而且可以获得较大的感受野。
关于 ResNet 的变种主要有两个思路,一个是让 ResNet 更深(比如Identity Mappings in Deep Residual Networks),一个是让 ResNet 更宽(比如 ResNeXt)。
3.5 SqueezeNet
在开始 SqueezeNet 之前, 我们从轻量化的实现方式上来看看这些轻量化网络是如何实现的。
-
- 优化网络结构。比如 Shuffle Net。
-
- 减少模型参数。比如 SqueezeNet。
-
- 优化卷积操作。这里又可以分为两种,一种是改变卷积操作的过程,比如 MobileNet;另外一种是从算法的角度对卷积进行优化,比如 Winograd。
-
- 剔除 FC。比如 SqueezeNet,LightCNN。
SqueezeNet 是 Forrest N. Iandola 等人2016年于 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size 中提出的一种网络模型,从论文标题我们就可以看到,作者仅用 AlexNet 1/50 的参数就取得了与 AlexNet 相当的精度。
SqueezeNet 的主要思想如下:
-
- 多用 1x1 的卷积核,而少用 3x3 的卷积核。因为 1x1 的好处是可以在保持 feature map size 的同时减少 channel。
-
- 在用 3x3 卷积的时候尽量减少 channel 的数量,从而减少参数量。
-
- 延后用 pooling,因为 pooling 会减小 feature map size,延后用 pooling, 这样可以使 size 到后面才减小,而前面的层可以保持一个较大的 size,从而起到提高精度的作用。
基于上面的思想, 论文中提出了 fire module,其结构如下。

其具体的结构如下。

最后作者对比了三种不同结构网络,如下图所示。测试表明,中间的效果最好,左边的次之,右边的最差。

更多 SqueezeNet 的内容可以参考 Review: SqueezeNet (Image Classification)
3.6 MobileNet V1
MobileNet(v1)是 Andrew G. Howard 等在2017年于 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 中提出的。
前面我们已经提到, MobileNet 是通过优化卷积操作来达到轻量化的目的的,具体来说,文中通过 Deepwise Conv(其实是Deepwise Conv + Pointwise Conv)代替原始的卷积操作实现,从而达到减少计算的目的(通常所使用的是 3×3 的卷积核,计算量会下降到原来的九分之一到八分之一)。如下图所示。

关于 Deepwise Conv 的详细介绍可以参考 可分离卷积基本介绍。
另外上面提到了改变卷积操作后的好处是加速,那缺点是什么呢?一个是精度会下降大约1%,另一个是训练速度有可能会慢一点。
现在(2019年)V3 已经推出来了,可以优先选用 V3。更多关于 MobileNet 的介绍可以参考 MobileNet 进化史: 从 V1 到 V3
3.7 ShuffleNet V1
ShuffleNet 是 Xiangyu Zhang(旷视)等人于2017年在 ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 中提出来的。ShuffleNet 的核心思想是对卷积进行分组,从而减少计算量,但是由于分组相当于将卷积操作局限在某些固定的输入上,为了解决这个问题采用 shuffle 操作将输入打乱,从而解决这个问题。

二、结语
如果你想关注更多的发展总结,可以参考今年(2019)刚出的一片综述文章 A Survey of the Recent Architectures of Deep Convolutional Neural Networks。