数据分析第二章
数据分析第二章
第二章:第一节数据清洗及特征处理
导入numpy、pandas包和数据
import numpy as np
import pandas as pd
#加载数据train.csv
df = pd.read_csv('train.csv')
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2 第二章:数据清洗及特征处理
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的亚子。
2.1 缺失值观察与处理
我们拿到的数据经常会有很多缺失值,比如我们可以看到Cabin列存在NaN,那其他列还有没有缺失值,这些缺失值要怎么处理呢
2.1.1 任务一:缺失值观察
(1) 请查看每个特征缺失值个数
(2) 请查看Age, Cabin, Embarked列的数据
以上方式都有多种方式,所以大家多多益善
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
df.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df.isnull().any()
PassengerId False
Survived False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare False
Cabin True
Embarked True
dtype: bool
df[['Age','Cabin','Embarked']].head(3)
| Age | Cabin | Embarked | |
|---|---|---|---|
| 0 | 22.0 | NaN | S |
| 1 | 38.0 | C85 | C |
| 2 | 26.0 | NaN | S |
2.1.2 任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
(2) 请尝试对Age列的数据的缺失值进行处理
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
#处理缺失值的一般思路:
#提醒:可使用的函数有--->dropna函数与fillna函数
#删除行
#axis:控制行列的参数,0 行,1 列。
#how:any,如果有 NaN,删除该行或列;all,如果所有值都是 NaN,删除该行或列。
#thresh:指定 NaN 的数量,当 NaN 数量达到才删除。
#subset:要考虑的数据范围,如:删除缺失行,就用subset指定参考的列,默认是所有列。
#inplace:是否修改原数据,True直接修改原数据,返回 None,False则返回处理后的数据框。
df1 = df.dropna(axis=0, how='any', thresh=2)
df1.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
#删除Age 空值行
df2 = df.dropna(axis=0, subset=['Age'], how='any')
df2.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 529
Embarked 2
dtype: int64
#用特定值填充Age 空值行
df2 = df.fillna(value={'Age': df['Age'].mean()},axis=0)
df2.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
#当method 值为 backfill 或 bfill时,按后一个值进行填充。
# 当 axis = 0,用缺失值同一列的下一个值填充,如果缺失值在最后一行则不填充。
# 当 axis = 1,用缺失值同一行的下一个值填充,如果缺失值在最后一列则不填充。
df1 = df.fillna(axis=0, method='bfill')
df1.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 1
Embarked 0
dtype: int64
【思考1】dropna和fillna有哪些参数,分别如何使用呢?
fillna 参数
df.fillna(value=None,#填充值
method=None,#指定方法
axis=0, #axis = 0 列 ,1 为行
inplace=False, #是否更改原表
limit=None #limit限制填充次数
)
例如:当method 值为 ffill 或 pad时,按前一个值进行填充。
当 axis = 0,用缺失值同一列的上一个值填充,如果缺失值在第一行则不填充。
当 axis = 1,用缺失值同一行的上一个值填充,如果缺失值在第一列则不填充。
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
检索空值使用np.nan最好,也可以使用.isnull()。最好不要使用None是因为空缺值的数据类型为float64用None一般索引不到。
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.fillna.html
2.2 重复值观察与处理
由于这样那样的原因,数据中会不会存在重复值呢,如果存在要怎样处理呢
2.2.1 任务一:请查看数据中的重复值
df.duplicated().sum()
0
2.2.2 任务二:对重复值进行处理
(1)重复值有哪些处理方式呢?
(2)处理我们数据的重复值
方法多多益善
df1 = df.drop_duplicates()
df1.count()
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64
2.2.3 任务三:将前面清洗的数据保存为csv格式
#写入代码
df.to_csv('test_clear.csv')
2.3 特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征,数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
2.3.1 任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
(3) 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
(5) 将上面的获得的数据分别进行保存,保存为csv格式
#将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 2 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 3 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 2 |
#将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80], right=False)
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | [15, 30) |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | [30, 50) |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | [15, 30) |
#将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80], right=False, labels = [1,2,3,4,5])
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 3 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 4 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 3 |
#将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5])
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 2 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 5 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 3 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 4 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 4 |
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.cut.html
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.qcut.html
2.3.2 任务二:对文本变量进行转换
(1) 查看文本变量名及种类
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
#查看类别文本变量名及种类
#方法一: value_counts
df['Embarked'].value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
df['Embarked'].unique()
array(['S', 'C', 'Q', nan], dtype=object)
#将类别文本转换为12345
#方法一: replace
df['Embarked_num'] = df['Embarked'].replace(['S','C','Q'],[1,2,3])
df['Embarked_num'].value_counts()
1.0 644
2.0 168
3.0 77
Name: Embarked_num, dtype: int64
#方法二: map
df['Embarked_num'] = df['Embarked'].map({'S': 1, 'C': 2, 'Q': 3})
df['Embarked_num'].value_counts()
1.0 644
2.0 168
3.0 77
Name: Embarked_num, dtype: int64
#方法三: 使用sklearn.preprocessing的LabelEncoder
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Sex']:
lbl = LabelEncoder()
label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))
df[feat + "_labelEncode"] = df[feat].map(label_dict)
df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | Embarked_num | Cabin_labelEncode | Sex_labelEncode | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 2 | 1.0 | 147 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 5 | 2.0 | 81 | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 3 | 1.0 | 147 | 0 |
2.3.3 任务三:从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | AgeBand | Embarked_num | Cabin_labelEncode | Sex_labelEncode | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 2 | 1.0 | 147 | 1 | Mr |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 5 | 2.0 | 81 | 0 | Mrs |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 3 | 1.0 | 147 | 0 | Miss |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 4 | 1.0 | 55 | 0 | Mrs |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 4 | 1.0 | 147 | 1 | Mr |
#保存最终你完成的已经清理好的数据
df.to_csv('test_fin1.csv')
2.4 数据的合并
import os
path = os.path.abspath('train-left-up.csv')
path
'C:\\Users\\Administrator\\hands-on-data-analysis-master\\第二章项目集合\\train-left-up.csv'
# 载入data文件中的:train-left-up.csv
train_left_up = pd.read_csv('C:\\Users\\Administrator\\hands-on-data-analysis-master\\第二章项目集合\\data\\train-left-up.csv')
2.4.1 任务一:将data文件夹里面的所有数据都载入,观察数据的之间的关系
train_left_down = pd.read_csv('C:\\Users\\Administrator\\hands-on-data-analysis-master\\第二章项目集合\\data\\train-left-down.csv')
train_right_down = pd.read_csv('C:\\Users\\Administrator\\hands-on-data-analysis-master\\第二章项目集合\\data\\train-right-down.csv')
train_right_up = pd.read_csv('C:\\Users\\Administrator\\hands-on-data-analysis-master\\第二章项目集合\\data\\train-right-up.csv')
print(train_left_down.head(3))
print(train_left_up.head(3))
print(train_right_down.head(3))
print(train_right_up.head(3))
PassengerId Survived Pclass Name
0 440 0 2 Kvillner, Mr. Johan Henrik Johannesson
1 441 1 2 Hart, Mrs. Benjamin (Esther Ada Bloomfield)
2 442 0 3 Hampe, Mr. Leon
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
Name
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 male 31.0 0 0 C.A. 18723 10.50 NaN S
1 female 45.0 1 1 F.C.C. 13529 26.25 NaN S
2 male 20.0 0 0 345769 9.50 NaN S
Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 male 22.0 1 0 A/5 21171 7.2500 NaN S
1 female 38.0 1 0 PC 17599 71.2833 C85 C
2 female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
【提示】结合之前我们加载的train.csv数据,大致预测一下上面的数据是什么
2.4.2:任务二:使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
list_up = [train_left_up,train_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2.4.3 任务三:使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result。
list_down=[train_left_down,train_right_down]
result_down = pd.concat(list_down,axis=1)
result_down.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 440 | 0 | 2 | Kvillner, Mr. Johan Henrik Johannesson | male | 31.0 | 0 | 0 | C.A. 18723 | 10.50 | NaN | S |
| 1 | 441 | 1 | 2 | Hart, Mrs. Benjamin (Esther Ada Bloomfield) | female | 45.0 | 1 | 1 | F.C.C. 13529 | 26.25 | NaN | S |
| 2 | 442 | 0 | 3 | Hampe, Mr. Leon | male | 20.0 | 0 | 0 | 345769 | 9.50 | NaN | S |
result = pd.concat([result_up,result_down])
result.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2.4.4 任务四:使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
result_up = train_left_up.join(train_right_up)
result_down = train_left_down.join(train_right_down)
result = result_up.append(result_down)
result.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2.4.5 任务五:使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
# merge参数如下:
# left: 拼接的左侧DataFrame对象
# right: 拼接的右侧DataFrame对象
# on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
# left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
# right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
# left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
# right_index: 与left_index功能相似。
# how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
# sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
# suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
# copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
# indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
result_up = pd.merge(train_left_up,train_right_up,left_index=True,right_index=True)
result_down = pd.merge(train_left_down,train_right_down,left_index=True,right_index=True)
result = result_up.append(result_down)
result.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
【思考】对比merge、join以及concat的方法的不同以及相同。思考一下在任务四和任务五的情况下,为什么都要求使用DataFrame的append方法,如何只要求使用merge或者join可不可以完成任务四和任务五呢?
2.4.6 任务六:完成的数据保存为result.csv
result.to_csv('result.csv')
2.5 换一种角度看数据
2.5.1 任务一:将我们的数据变为Series类型的数据
# stack()函数将dataframe变成了series,所有列挤到一列
# stack()即“堆叠”,作用是将列旋转到行
# unstack()即stack()的反操作,将行旋转到列
unit_result=result.stack().head(20)
unit_result.head(11)
0 PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
Sex male
Age 22.0
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Embarked S
dtype: object
type(unit_result)
pandas.core.series.Series
#将代码保存为unit_result,csv
unit_result.to_csv('unit_result.csv')
数据聚合与运算
# 载入上一个任务人保存的文件中:result.csv,并查看这个文件
df = pd.read_csv('result.csv')
df.head(3)
| Unnamed: 0 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2.6 数据运用
2.6.1 任务一:通过教材《Python for Data Analysis》P303、Google or anything来学习了解GroupBy机制
#pandas提供了一个灵活高效的gruopby功 能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
在了解GroupBy机制之后,运用这个机制完成一系列的操作,来达到我们的目的。
下面通过几个任务来熟悉GroupBy机制。
2.6.2:任务二:计算泰坦尼克号男性与女性的平均票价
df1 = df['Fare'].groupby(df['Sex'])
means = df1.mean()
means
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
2.6.3:任务三:统计泰坦尼克号中男女的存活人数
survived_sex = df['Survived'].groupby(df['Sex']).sum()
survived_sex
Sex
female 233
male 109
Name: Survived, dtype: int64
2.6.4:任务四:计算客舱不同等级的存活人数
#方法1
survived_pclass = df['Survived'].groupby(df['Pclass'])
survived_pclass.sum()
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
#方法2
survived_pclass = df['Survived'].groupby(df['Pclass']).sum()
survived_pclass
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
【提示:】表中的存活那一栏,可以发现如果还活着记为1,死亡记为0
【思考】从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。你可以按照提示写出这个过程吗?
# agg()函数是聚合函数,
# DataFrame.agg(func,axis = 0,* args,** kwargs )
# 实现某种统计功能的函数,如果要不同列用求不同统计量,则用字典{‘行名/列名’:‘函数名’}指定。
df2= df.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns=
{'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
df2.head(3)
| mean_fare | count_pclass | |
|---|---|---|
| Sex | ||
| female | 44.479818 | 314 |
| male | 25.523893 | 577 |
2.6.5:任务五:统计在不同等级的票中的不同年龄的船票花费的平均值
df.groupby(['Pclass','Age'])['Fare'].mean().head(3)
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
Name: Fare, dtype: float64
2.6.6:任务六:将任务二和任务三的数据合并,并保存到sex_fare_survived.csv
result = pd.merge(means,survived_sex,on='Sex')
result
| Fare | Survived | |
|---|---|---|
| Sex | ||
| female | 44.479818 | 233 |
| male | 25.523893 | 109 |
2.6.7:任务七:得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
#不同年龄的总的存活人数
survived_age = df['Survived'].groupby(df['Age']).sum()
survived_age.head()
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
Name: Survived, dtype: int64
#存活人数最多的年龄段
survived_age[survived_age.values==max(survived_age)]
Age
24.0 15
Name: Survived, dtype: int64
# 计算存活人数最高的存活率(存活人数/总人数)¶
survived_rate = max(survived_age)/df['Survived'].sum()
print( '存活人数最高的存活率: '+ str(survived_rate))
存活人数最高的存活率: 0.043859649122807015
2.7 如何让人一眼看懂你的数据?
开始之前,导入numpy、pandas以及matplotlib包和数据
# 加载所需的库
# 如果出现 ModuleNotFoundError: No module named 'xxxx'
# 你只需要在终端/cmd下 pip install xxxx 即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#加载result.csv这个数据
df = pd.read_csv('result.csv')
df.head(3)
| Unnamed: 0 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
2.7.1 任务一:跟着书本第九章,了解matplotlib,自己创建一个数据项,对其进行基本可视化
【思考】最基本的可视化图案有哪些?分别适用于那些场景?(比如折线图适合可视化某个属性值随时间变化的走势)
1.折线图
折线图或曲线图用于说明一段时间或连续时间间隔内数据的趋势。 折线图往往会通过连接不同的绘制点来反映随着时间变化的不同事物。例如,我们可以使用折线图的场景是每月降雨量,公司的年销售额,股票价格逐月趋势,门户网站用户等。
2.柱形图
柱形图是最基本的图表,它们使用柱形显示类别之间的数值。 柱形图包括沿水平轴的数据标签,以及沿垂直轴的度量或值。
例如,可以使用柱形图的一些方案是-按不同区域的销售额,产品类别,分类数据的比较。
3.条形图
条形图的用法与柱形图相似,只是条形图的两个轴的位置发生了变化。 条形图通常在类别相对较多时使用,或者在显示负值时很有用。比较不同类型的类别时,也可以堆叠或群集条形图。 使用条形图的情况与柱形图相同。
4.饼图
饼图用于表示各个领域中不同类别的比例。 它们对于了解某物有多少是整体非常有用。
例如,可以使用饼图的场景包括人口细分之间的比较,预算分配,男女比例,在线流量来源等。
5.面积图
面积图表示与折线图相同的数据(量)随时间的变化。 它是根据折线图形成的,在折线图中,趋势线和轴之间的颜色填充有颜色。 随着颜色的填充更好地突出了趋势信息。
面积图可用于描述时间序列关系,零件到整体分析,每个类别的趋势之间的简单比较等。
6.散点图
散点图用于识别两个度量(数量)之间的两个关系。 散点图主要用于识别从水平轴值推断垂直值的能力。
7.热图
热图根据完全在指定区域中的不同值使用从浅到深的颜色渐变范围。 热图可用于指定温度分布,人口密度等。
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)。
sex = df.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()

【思考】计算出泰坦尼克号数据集中男女中死亡人数,并可视化展示?如何和男女生存人数可视化柱状图结合到一起?看到你的数据可视化,说说你的第一感受(比如:你一眼看出男生存活人数更多,那么性别可能会影响存活率)。
#相对于柱状图感觉用饼图看得会更直观些
sex = df.groupby('Sex')['Survived'].sum()
sex.plot.pie()
plt.title('survived_count')
sex
Sex
female 233
male 109
Name: Survived, dtype: int64

2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)。
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
df.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('survived')

【提示】男女这两个数据轴,存活和死亡人数按比例用柱状图表示
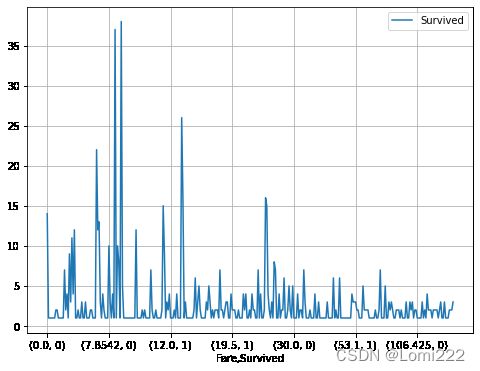
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
【提示】对于这种统计性质的且用折线表示的数据,你可以考虑将数据排序或者不排序来分别表示。看看你能发现什么?
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
fare_survived = df.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_survived
Fare Survived
8.0500 0 38
7.8958 0 37
13.0000 0 26
7.7500 0 22
13.0000 1 16
..
7.7417 0 1
26.2833 1 1
7.7375 1 1
26.3875 1 1
22.5250 0 1
Name: Survived, Length: 330, dtype: int64
# 排序后绘折线图
fig = plt.figure(figsize=(8, 6))
fare_survived.plot(grid=True)
plt.legend()
plt.show()

# 排序前绘折线图
fare_survived1 = df.groupby(['Fare'])['Survived'].value_counts()
fare_survived1
Fare Survived
0.0000 0 14
1 1
4.0125 0 1
5.0000 0 1
6.2375 0 1
..
247.5208 1 1
262.3750 1 2
263.0000 0 2
1 2
512.3292 1 3
Name: Survived, Length: 330, dtype: int64
fig = plt.figure(figsize=(8, 6))
fare_survived1.plot(grid=True)
plt.legend()
plt.show()
2.7.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
# 1表示生存,0表示死亡
import seaborn as sns
pclass_survived = df.groupby(['Pclass'])['Survived'].value_counts()
sns.countplot(x="Pclass", hue="Survived", data=df)
pclass_survived
Pclass Survived
1 1 136
0 80
2 0 97
1 87
3 0 372
1 119
Name: Survived, dtype: int64
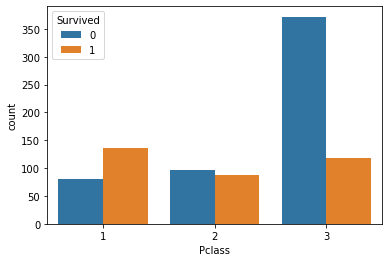
【思考】看到这个前面几个数据可视化,说说你的第一感受和你的总结
#学习到了多种柱状图的可视化方法
2.7.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
facet = sns.FacetGrid(df, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, df['Age'].max()))
facet.add_legend()

age_survived = df.groupby(['Age'])['Survived'].value_counts()
sns.displot(x="Age", hue="Survived", data=df,kind='kde')
age_survived.sort_values(ascending=False)
Age Survived
21.0 0 19
28.0 0 18
18.0 0 17
25.0 0 17
19.0 0 16
..
36.5 0 1
37.0 1 1
43.0 1 1
47.0 1 1
80.0 1 1
Name: Survived, Length: 142, dtype: int64

2.7.7 任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
df.Age[df.Pclass == 1].plot(kind='kde')
df.Age[df.Pclass == 2].plot(kind='kde')
df.Age[df.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")
