大数据基础平台搭建-(二)Hadoop集群搭建
大数据基础平台搭建-(二)Hadoop集群搭建
大数据平台系列文章:
1、大数据基础平台搭建-(一)基础环境准备
2、大数据基础平台搭建-(二)Hadoop集群搭建
大数据平台是基于Apache Hadoop_3.3.4搭建的;
目录
- 大数据基础平台搭建-(二)Hadoop集群搭建
- 一、部署架构
- 二、在hnode1服务器上搭建Name_Node_Master
-
- 1、解压Hadoop
- 2、配置HADOOP_HOME环境变量
- 3、配置Hadoop集群配置文件
-
- 1). 配置hadoop守护进程
- 2). 配置NameNode
- 3). 配置YARN的ResourceManager
- 4). 配置MapReduce应用
- 5). 配置Hadoop环境变量
- 5). 配置Yarn环境变量
- 6). 配置Hadoop集群工作节点
- 三、在hnode2服务器上搭建Name_Node_Secondary
-
- 1、复制Hadoop
- 2、配置HADOOP_HOME环境变量
- 四、在hnode3服务器上搭建DataNode
-
- 1、复制Hadoop
- 2、配置HADOOP_HOME环境变量
- 五、在hnode4服务器上搭建Name_Node_Secondary
-
- 1、复制Hadoop
- 2、配置HADOOP_HOME环境变量
- 六、在hnode5服务器上搭建Name_Node_Secondary
-
- 1、复制Hadoop
- 2、配置HADOOP_HOME环境变量
- 七、启动Hadoop集群(在hnode1服务器上操作)
-
- 1. 创建Hadoop启动停止脚本
- 2. Hadoop集群初始化
- 3. Hadoop集群启动
- 八、确认Hadoop集群状态
-
- 1. 查看HDFS
- 2. 查看DataNode
- 3. 查看HistoryServer
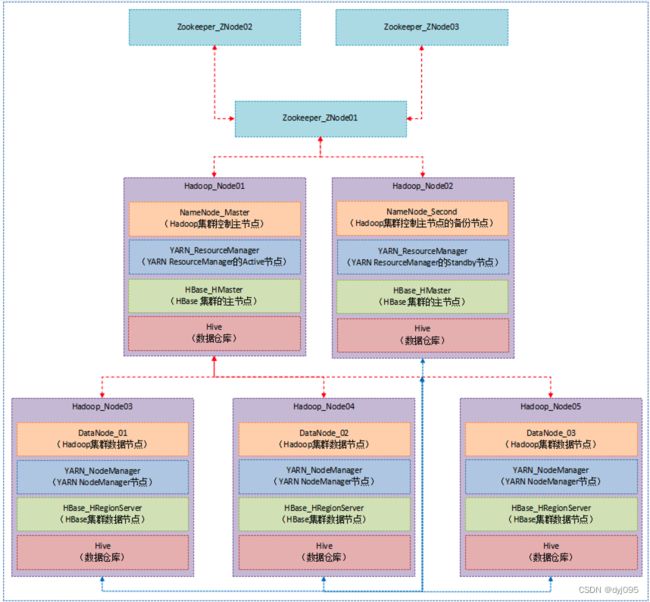
一、部署架构
二、在hnode1服务器上搭建Name_Node_Master
1、解压Hadoop
[root@hnode1 ~]# cd /opt/hadoop/
[root@hnode1 hadoop]# mkdir data
[root@hnode1 hadoop]# tar -xzvf hadoop-3.3.4.tar.gz
2、配置HADOOP_HOME环境变量
[root@hnode1 hadoop]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@hnode1 hadoop]# source /etc/profile
3、配置Hadoop集群配置文件
配置文件所在的目录/opt/hadoop/hadoop-3.3.4/etc/hadoop/,所要编辑的配置文件如下表所示
| 序号 | 配置文件 | 说明 |
|---|---|---|
| 1 | core-site.xml | 配置Hadoop守护进程 |
| 2 | hdfs-site.xml | 配置HDFS的NameNode |
| 3 | yarn-site.xml | 配置YARN的ResourceManager |
| 4 | mapred-site.xml | 配置MapReduce应用 |
| 5 | hadoop-env.sh | 配置Hadoop环境变量 |
| 6 | yarn-env.sh | 配置Yarn环境变量 |
| 7 | workers | 配置Hadoop集群工作节点 |
1). 配置hadoop守护进程
[root@hnode1 hadoop]# cd hadoop-3.3.4
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hnode1:8020value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>rootvalue>
property>
configuration>
2). 配置NameNode
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>hnode1:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hnode2:9868value>
property>
configuration>
3). 配置YARN的ResourceManager
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hnode1value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hnode2:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
4). 配置MapReduce应用
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hnode2:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hnode2:19888value>
property>
configuration>
5). 配置Hadoop环境变量
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_271
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5). 配置Yarn环境变量
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_271
6). 配置Hadoop集群工作节点
[root@hnode1 hadoop-3.3.4]# vim etc/hadoop/works
hnode1
hnode2
hnode3
hnode4
hnode5
三、在hnode2服务器上搭建Name_Node_Secondary
1、复制Hadoop
[root@hnode2 ~]#cd /opt/hadoop/
[root@hnode2 hadoop]# mkdir data
[root@hnode2 hadoop]# scp -r hnode1:/opt/hadoop/hadoop-3.3.4/ ./
2、配置HADOOP_HOME环境变量
[root@hnode2 hadoop]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@hnode2 hadoop]# source /etc/profile
四、在hnode3服务器上搭建DataNode
1、复制Hadoop
[root@hnode3 ~]#cd /opt/hadoop/
[root@hnode3 hadoop]# mkdir data
[root@hnode3 hadoop]# scp -r hnode1:/opt/hadoop/hadoop-3.3.4/ ./
2、配置HADOOP_HOME环境变量
[root@hnode3 hadoop]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@hnode3 hadoop]# source /etc/profile
五、在hnode4服务器上搭建Name_Node_Secondary
1、复制Hadoop
[root@hnode4 ~]#cd /opt/hadoop/
[root@hnode4 hadoop]# mkdir data
[root@hnode4 hadoop]# scp -r hnode1:/opt/hadoop/hadoop-3.3.4/ ./
2、配置HADOOP_HOME环境变量
[root@hnode4 hadoop]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@hnode4 hadoop]# source /etc/profile
六、在hnode5服务器上搭建Name_Node_Secondary
1、复制Hadoop
[root@hnode5 ~]#cd /opt/hadoop/
[root@hnode5 hadoop]# mkdir data
[root@hnode5 hadoop]# scp -r hnode1:/opt/hadoop/hadoop-3.3.4/ ./
2、配置HADOOP_HOME环境变量
[root@hnode5 hadoop]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@hnode5 hadoop]# source /etc/profile
七、启动Hadoop集群(在hnode1服务器上操作)
1. 创建Hadoop启动停止脚本
shell脚本是引用 FlyingCodes的博文大数据平台搭建详细流程(二)Hadoop集群搭建的脚本
[root@hnode1 ~]#cd /opt/hadoop/
[root@hnode1 hadoop]# vim hadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "缺少参数..."
exit ;
fi
case $1 in
"start")
echo " ===================| 启动 Hadoop集群 | ==================="
echo " -------------------| 启动 HDFS | ---------------"
ssh hnode1 "/opt/hadoop/hadoop-3.3.4/sbin/start-dfs.sh"
echo " -------------------| 启动 YARN | ---------------"
ssh hnode1 "/opt/hadoop/hadoop-3.3.4/sbin/start-yarn.sh"
echo " -------------------| 启动 HistoryServer |---------------"
ssh hnode2 "/opt/hadoop/hadoop-3.3.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " ===================| 关闭 Hadoop集群 |==================="
echo " -------------------| 关闭 HistoryServer |---------------"
ssh hnode2 "/opt/hadoop/hadoop-3.3.4/bin/mapred --daemon stop historyserver"
echo " -------------------| 关闭 YARN | ---------------"
ssh hnode1 "/opt/hadoop/hadoop-3.3.4/sbin/stop-yarn.sh"
echo " -------------------| 关闭 HDFS | ---------------"
ssh hnode1 "/opt/hadoop/hadoop-3.3.4/sbin/stop-dfs.sh"
;;
*)
echo "输入的参数错误..."
;;
esac
[root@hnode1 hadoop]# chmod +x ./hadoop.sh
2. Hadoop集群初始化
[root@hnode1 hadoop]# start-dfs.sh
[root@hnode1 hadoop]# start-yarn.sh
[root@hnode1 hadoop]# hdfs namenode -format
[root@hnode1 hadoop]# ./hadoop.sh stop
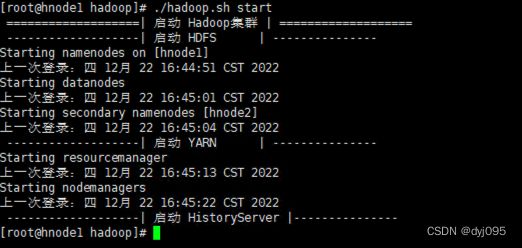
3. Hadoop集群启动
[root@hnode1 hadoop]# ./hadoop.sh start
八、确认Hadoop集群状态
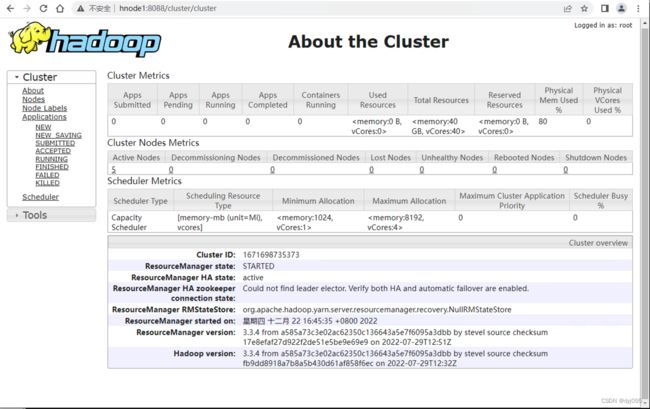
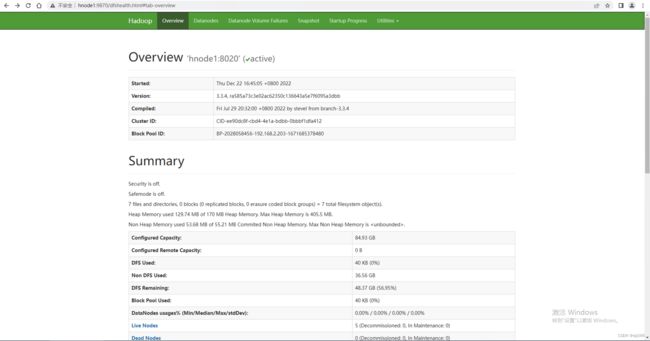
1. 查看HDFS
http://hnode1:8088
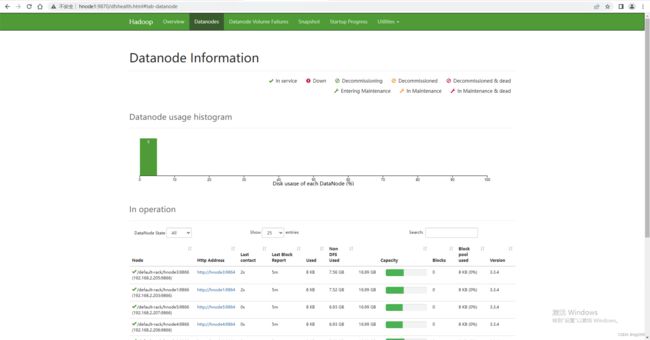
2. 查看DataNode
http://hnode1:9870
3. 查看HistoryServer
http://hnode2:19888/jobhistory