(原文)基于甘特图的深度强化学习方法求解端到端在线重调度

获取更多资讯,赶快关注上面的公众号吧!
文章目录
- 介绍关注公众号,后台回复"甘特图"获取原文
- 新方法
- 重调度环境
- 优化目标
- 重调度策略
- 重调度方法
- 调度状态表达
- 调度动作
- 奖励函数
- 训练算法
- 马尔可夫决策过程
- 实验结果
-
- 实验1:紧急插单
- 实验2:物料延迟到达
- 实验3:标准案例
介绍关注公众号,后台回复"甘特图"获取原文
面对车间的工艺柔性、生产复杂性和订单的高可变性等影响制造工艺计划和响应的动态因素,就要求人类具有独特的认知能力,以确保对可能影响计划可行性和性能的干扰和意外事件(如紧急插单、物料延期或短缺、机床故障、质量不合格等)作出快速反应,因此车间内往往并不关注调度的最优性,而是强调赋予车间调度人员足够的自由度和先验知识来做出重调度决策,以及时响应不可预见的干扰事件(人机交互调度文章)。
很多调度研究工作也都没有明确地考虑车间环境问题,如由于资源共享、任务延迟、物料延期、紧急插单和新增任务而导致的任务工时的显著变化,通常这些研究仅仅是简单地假设生成的全局调度作为最优解按照制定好的时间精确执行,但这往往和实际生产车间情况大相径庭,计算得到的结果往往在实际中都是不可行解。
针对以上问题,我的博士论文研究主要是基于析取图模型,采用完全重调度的方法,每进行一次任务分派时都选择合适的规则,从而构造又好又快的解。但是今天的文章想给大家带来一种新的思路,就是来自阿根廷的学者Jorge Andrés Palombarini最新发表于IJPR的一篇文章,这篇文章的思路有点像我博士论文的倒数第二章(有时间会整理成文章发出来)。

新方法
Palombarini提出了一种新的方法用于生成重调度知识,用来实时处理不可预见事件。那为了获取这样的重调度知识,作者将重调度任务建模为闭环控制问题,将调度状态仿真器与重调度代理进行集成,重调度代理仅基于现成的彩色甘特图和不容忽视的先验知识,可直接从大量的仿真变迁中学习调度修复策略。生成的重调度知识存储在深度神经网络中,可作为闭环重调度控制系统的有效计算工具,选择修复动作以实现目标调度状态,而不需要在每次发生扰动事件时计算重新调度问题的解,并且将控制知识泛化到未曾见过的调度状态。实际上,该作者最早于2012年就开始了相关研究,此后在2018和2019年也发表过两篇相关问题,
重调度环境
文中采用了面向订单的动态重调度环境,该环境下不同产品源源不断地产生订单,每个订单包含多个生产批次,每个批次又考虑了准备时间。此外还考虑了订单到达的可变性,在订单到达前并不会提前知道不同订单的属性信息,如交货期、产品组合和批量大小等。并且资源是专属的,并不是所有的资源都可以加工所有的产品。加工速率取决于资源和产品,同一产品可被多个资源加工,也就说是柔性的。作者呢也给出了重调度环境的源码(https://github.com/jpu2/rescheduling_agent)。
优化目标
考虑了两个和交货期相关的目标:总拖期和makespan。
重调度策略
当扰动事件发生时,就对已有的生产调度进行更新或修复,以最小化对系统性能的影响,因此本质上是一种事件驱动的反应式调度方法,同时也可以看成是一种混合重调度策略,因为重调度动作既可以由事件触发,也可以根据用户需求触发。
重调度方法
采用的重调度方法是一种在线调度重新生成方法,这种重新生成既可以是部分的也可以是完全的,这取决于当前调度中的总拖期和扰动事件导致的额外拖期。控制策略定义了修复算子的最优序列,通过在当前调度上应用该序列就能重新生成新的调度解。
调度状态表达
作者直接使用甘特图作为训练复杂神经网络的输入,从中利用卷积神经网络自动提取调度特征,避免手动设计特征。
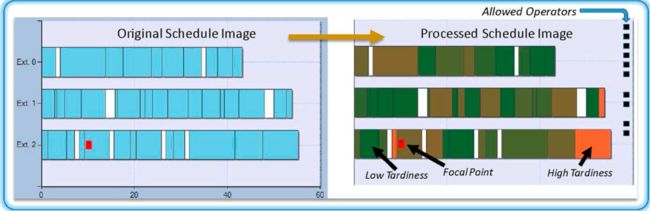
实际上,作者先是对原始图像进行了预处理的。一方面,先是对原始图像进行裁边处理,以去除多余的像素,降低训练复杂度;另一方面,是按照最大拖期和最小拖期对任务拖期进行归一化并重新着色,从而将任务拖期情况于目标建立关联关系。
调度动作
调度动作就是修复算子,它以一组任务及其对应的分配资源为参数,并根据算子定义来产生新的状态。这样的算子包括:拼接两个任务为一个任务作为输出,分割一个任务为多个类似的任务,交换资源上的两个任务,重新设置任务的开始时间,等等。
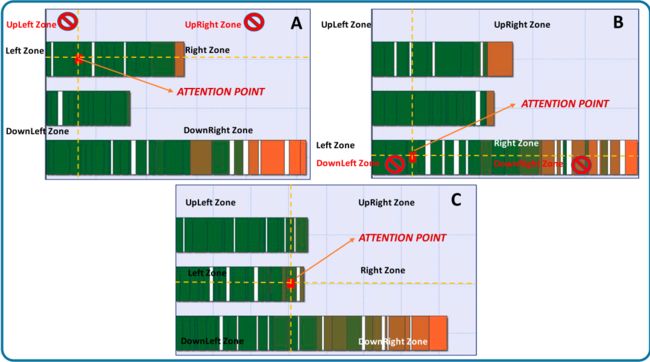
具体来说,文中定义了焦点的概念,来定位任务、资源及所在区域。焦点任务用红色标记标出。焦点的作用就是用于集中重调度代理的注意力,以确定修复算子和与该标志有关的剩余任务。通过在焦点任务上添加十字线,将调度图像划分为6个区域(左上、右上、左、右、左下、右下),所有的任务都将处在其中一个区域内,如图2所示,因此当将焦点任务与其他任务进行移动或交换时,该动作对调度状态的影响都是基于焦点任务的当前位置的。区域的划分可以有效地帮助过滤掉一些不合法的修复算子,如图2中的A图,焦点任务位于最上面的资源1上,和“上”相关的所有修复算子都是不可行的,因为上面没有其他任务和资源了。
那选择哪个工序进行修复呢?文中也给出了选择规则,并且这种规则是和扰动事件的类型有密切关系的。如果是插单,订单会根据混合的产品类型和需求数量被分解为一组任务,然后从这些任务中随机选择一个作为焦点任务,并被插入到当前调度中的随机位置,在整个修复过程中,就一直将该任务作为焦点;如果是机器故障,在可选资源中随机位置插入任务并选择其中一个任务作为焦点,就生成一个开始时间随机的故障来影响其中一个资源,从而使得机器在一段时间内不可用。
奖励函数
不失一般性,奖励函数定义为拖期/制造期的提升程度,这样定义的好处是可以用于不同的调度性能指标,也可以不受任务数和加工时间不同的影响,通用性比较好。调度代理就是要学习如何降低扰动事件导致的总拖期,如果总拖期相比于初始值(扰动发生前)是降低的,那么就认为调度是被修复了的(或达到目标状态)。
r t = ( ( totalTardiness ( s initial ) − totalTardiness ( s t ) ) ) totalTardiness ( s initial ) (1) r_{t}=\frac{\left(\left(\text { totalTardiness }\left(s_{\text {initial }}\right)-\text { totalTardiness }\left(s_{t}\right)\right)\right)}{\text { totalTardiness }\left(s_{\text {initial }}\right)}\tag{1} rt= totalTardiness (sinitial )(( totalTardiness (sinitial )− totalTardiness (st)))(1)
值得注意的是,当初始总拖期为0时,为避免除以0,使用一个非常小的正实数代替,此外,如果选择了不可执行的修复算子,则给出 -1 \text{-1} -1 的奖励,这就相当于总拖期增大了100%,并且该算子也不会影响调度状态,这样就迫使调度代理不倾向于选择非法的修复算子。
训练算法
这篇文章中和以前不同的是采用了比较新的策略梯度法PPO来学习最优调度策略。

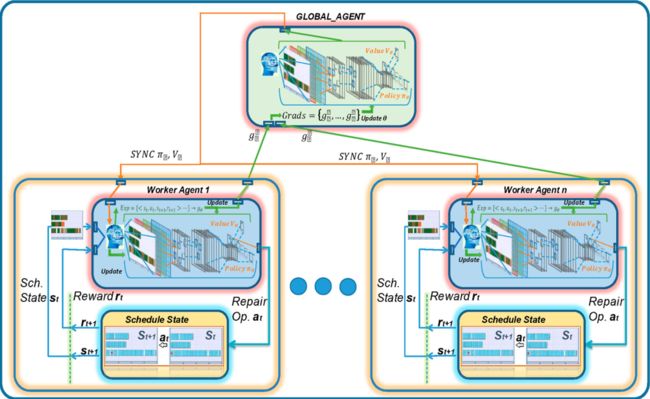
同时为了加快训练,采用了异步A3C框架。
马尔可夫决策过程
为了学习重调度策略,利用马尔可夫决策过程将调度问题转换为序列决策问题:
M D P resch = ( S , A , T , R , γ , goal ) (2) M D P_{\text {resch }}=(S, A, T, R, \gamma, \text { goal })\tag{2} MDPresch =(S,A,T,R,γ, goal )(2)
其中 S , A , R S,A,R S,A,R分别为状态、动作和奖励函数,前面已经介绍过。 T T T为状态转移函数,决定了在某一状态下执行某一动作会跳转到的下一状态,状态转移函数是由调度仿真器决定的。 γ \gamma γ为折扣因子,$ \text { goal }$为重调度结束目标,也是强化学习训练一个episode结束的标志,文中设计的是总拖期少于1天。如果无法找到一个修复算子序列使得调度满足调度目标状态,则会通过最大片段修复算子数来结束循环。
实验结果
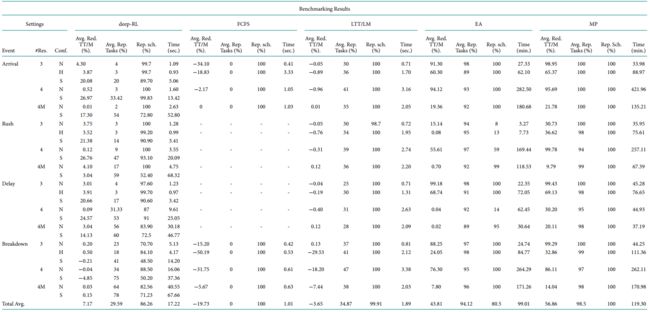
为了验证方法的有效性,作者选择了一个工厂实例,这个工厂有3台挤压机,用来加工4种产品,每台挤压机并不能都可以加工这4种产品,考虑了准备顺序依赖,设置了3种不同的配置:正常(N)、较难(H)、严格(S),详细参数见下表。
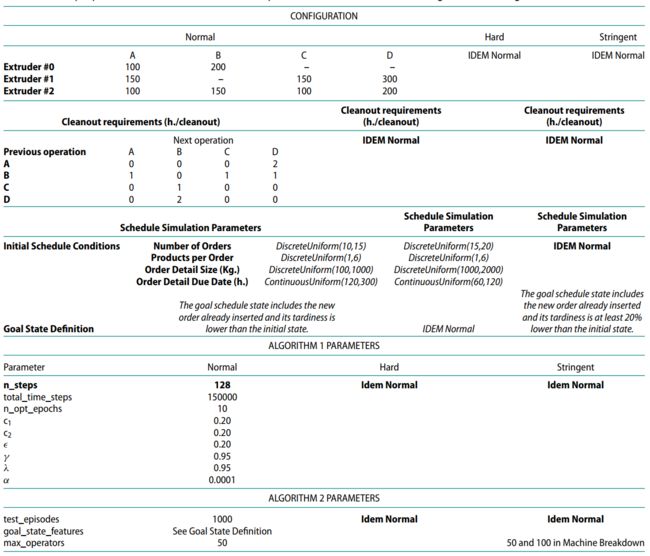
实验1:紧急插单
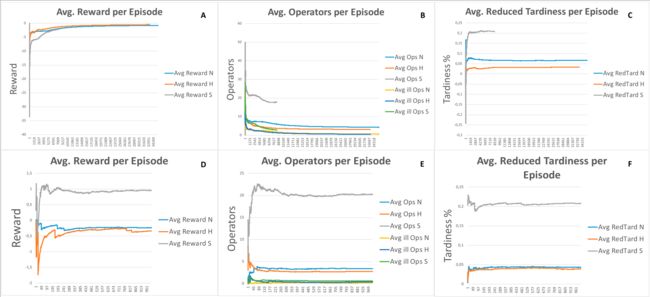
实验2:物料延迟到达
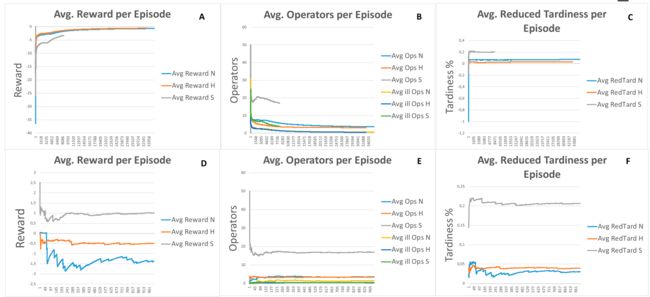
实验3:标准案例