Kmeans和谱聚类算法(python实现sklearn)
Kmeans算法大家都基本耳熟能详了,而谱聚类算法的过程如下

- 构建样本相似度矩阵S
- 根据S构建度矩阵H
- 计算拉普拉斯矩阵L=H-S
- 构建标准化拉普拉斯矩阵 H(-1/2)LH(-1/2)
- 计算 L 的最小的KK个特征值对应的特征向量
- 将向量按照行进行标准化(每个元素除以本行所有元素的平方和在开根号)得到N*KK的矩阵F,N为样本点数
- F中每一行作为一个样本,共N个样本,对其进行聚类(聚为K类)(KK与sigma是需要调整的参数)
- 得到cluster{C1,C2,…Ck}
-
起始本质就是得到特征矩阵之后在对特征矩阵执行 聚类
代码如下(jupyter运行)
import numpy as np
import matplotlib.pyplot as plt
import random
import heapq
from sklearn.cluster import KMeans
import sklearn
import pyamg
import math#参数初始化
N=20 #用户数
distance=2000 #距离
sigma_d=10000
K=4 #无人机数量
KK=6#矩阵降维维数users=np.random.randint(0,distance+1,(N,2))
# print(users)
scatter_x=[]
scatter_y=[]
for i in range(N):
scatter_x.append(users[i][0])
scatter_y.append(users[i][1])#矩阵S
matric_S=np.zeros((N,N))
for i in range(N):
for j in range(N):
matric_S[i][j]=math.exp(-((scatter_x[i]-scatter_x[j])**2+(scatter_y[i]-scatter_y[j])**2)/(2*(sigma_d**2)))
print(type(matric_S))#矩阵H(度矩阵)
matric_H=np.zeros((N,N))
for i in range(N):
for j in range(N):
matric_H[i][i]=matric_H[i][i]+matric_S[i][j]#矩阵H(度矩阵负二分之一次幂)
matric_H_ = np.sqrt(np.linalg.inv(matric_H))
#将数组转化为矩阵
matric_S=np.mat(matric_S)
matric_H=np.mat(matric_H)
matric_H_=np.mat(matric_H_)#拉普拉斯矩阵
matric_L=np.dot(np.dot(matric_H_,(matric_H-matric_S)),matric_H_)
求解特征值 w 和特征向量 v
w, v = np.linalg.eigh(matric_L)
print(w)
w=list(w)
min_KK = map(w.index, heapq.nsmallest(KK, w))
min_KK=list(min_KK)
# min_KK.sort()
print(min_KK)#特征值矩阵U
matric_U=np.zeros((N,KK))
for i in range(N):
for j in range(KK):
matric_U[i,j]=v[i,min_KK[j]]#特征值归一化矩阵T
matric_fm=np.zeros((N,1))
for i in range(N):
for j in range(KK):
matric_fm[i,0]=matric_U[i,j]**2+matric_fm[i,0]
matric_T=np.zeros((N,KK))
for i in range(N):
for j in range(KK):
matric_T[i,j]=matric_U[i,j]/np.sqrt(matric_fm[i,0])#对特征值进行Kmeans聚类
kmeans = KMeans(n_clusters=4, init='k-means++',random_state=1,n_init=1000).fit(matric_T)
colors = []
for i in range(kmeans.labels_.shape[0]):
if kmeans.labels_[i] == 1:
colors.append('red')
elif kmeans.labels_[i] == 2:
colors.append('blue')
elif kmeans.labels_[i] == 3:
colors.append('green')
else:
colors.append('purple')#对原始数据进行Kmeans聚类
kmeans_=KMeans(n_clusters=4, init='random', random_state=1,n_init=100).fit(users)
colors_ = []
for i in range(kmeans_.labels_.shape[0]):
if kmeans_.labels_[i] == 1:
colors_.append('red')
elif kmeans_.labels_[i] == 2:
colors_.append('blue')
elif kmeans_.labels_[i] == 3:
colors_.append('green')
else:
colors_.append('purple')#可视化
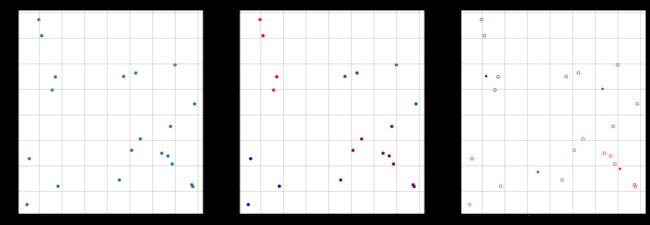
plt.figure(dpi=720,figsize=(24,8))
plt.subplot(131)
plt.title('random users')
plt.grid()
plt.scatter(scatter_x,scatter_y)
# plt.scatter(scatter_x,scatter_y,color='',edgecolors='blue')plt.subplot(132)
plt.title('kmeans ')
plt.grid()
# plt.scatter(scatter_x, scatter_y, color='',edgecolors=colors_, marker='o')
plt.scatter(scatter_x, scatter_y, c=colors_, marker='o')# 无人机位置
a_x=[]
b_y=[]
ab_color=['purple','red','blue','green']
for label_num in range(K):
a=[]
b=[]
for i in range(kmeans.labels_.shape[0]):
if kmeans.labels_[i] == label_num:
a.append(scatter_x[i])
b.append(scatter_y[i])
a_x.append(math.fsum(a)/5)
b_y.append(math.fsum(b)/5)
print(a_x)
print(b_y)plt.subplot(133)
plt.title('spectral cluster ')
plt.grid()
# plt.scatter(scatter_x, scatter_y, c=colors, marker='o')
plt.scatter(a_x,b_y,marker='*',c=ab_color)
plt.scatter(scatter_x, scatter_y, color='',edgecolors=colors, marker='o')
plt.show()
sklearn有集成的SpectralClustering谱聚类也可以自行使用,调制相关参数即可得到。