opencv相关学习笔记(一)
1.数据读取及变换——图片
(1)数据读取:cv.imread()
·有三种读取方式:彩色模式(参数为1或cv2.IMREAD_COLOR)
灰度模式(参数为0或cv2.IMREAD_GRAYSCALE)
包括alpha通道的加载图像模式(-1或cv2.IMREAD_UNCHANGED)
注意:opencv的读取格式是BGR
(2)图像显示:cv2.inshow()
import cv2
img = cv2.imread("D:/meishaonv.jpg") #读取图像,注意图像的路径写法,路径不能带有中文
cv2.namedWindow("1") #创建一个窗口
cv2.imshow("1",img) #在此窗口中展示图象
cv2.waitKey(0) #等待时间,0表示任意键终止;如果不添加此句,图像会一闪而过
cv2.destroyAllWindows()(3)保存图像:cv.imwrite("保存路径及文件名",图像矩阵)
其中有个可选的第三个参数:
对于JPEG:cv2.IMWRITE_JPEG_QUALITY它表示图像的质量,
用0-100表示,默认为95
对于PNG:cv2.IMWRITE_PNG_COMPRESSION表示压缩级别, 从0-9压缩级别越高,图像尺寸越小,默认为3
注意:cv2.IMWRITE_JPEG_QUALITY类型是Long,要转成int
cv2.imwrite("./cat.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
cv2.imwrite("./cat2.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])(4)截取部分图像数据:img=img[a:b,c:d]
a~b表示取得的高度范围,c~d表示取得的宽度范围
import cv2
img = cv2.imread("D:/meishaonv.jpg")
cat=img[0:50,0:200]
cv2.imshow("2",cat)
cv2.waitKey(0)(5)颜色通道提取:b,g,r=cv2.split(变量名)
#拆分
b,g,r=cv2.split(img)
cv2.waitKey(0)
r.shape
#合并
img=cv2.merge((b,g,r))
img.shape
(6)边界填充:
BORDER_REPLICATE:复制法,也就是复制最边缘像素。
BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如: fedcba|abcdefgh|hgfedcb
BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
BORDER_CONSTANT:常量法,常数值填充。

(7)绘制几何图形:
1.绘制直线:cv.line(img,start,end,color,thickness)
2.绘制圆形:cv.circle(img,centerpoint,r,color,thickness)
3.绘制矩形:cv.rectangle(img,leftupper,rightdown,color,thickness)
leftupper,rightdown矩形的左上角和右下角坐标
4.添加文字: cv.putText(img,text,station,font,fontsize,color,thickness,cv.LINE_AA)
(8)获取图像属性:
形状: img.shape
大小:img.size
数据类型:img.dtype
(9)色彩空间的改变:cv.cvtColor(input_image,flag)
- flag:转化类型 :cv.COLOR_BGR2GRAY:BGR
 Gray
Gray
cv.COLOR_BGR2HSV:BGR HSV
HSV
(10)图像几何变换:
- 图像缩放 :cv2.resize(scr.dsize,fx=0,fy=0,interpolation=cv2.INTE) dsize:绝对尺寸; fx,fy:相对尺寸,注意要将dsize设为None interpolation:插值方法,默认为INTER_LINEAR(线性插值)。
可选的插值方式如下:INTER_NEAREST - 最近邻插值
INTER_LINEAR - 线性插值(默认值)
INTER_AREA - 区域插值(利用像素区域关系的重采样插值)
lapu INTER_CUBIC –三次样条插值(超过4×4像素邻域内的双三次插值)
INTER_LANCZOS4 -Lanczos插值(超过8×8像素邻域的Lanczos插值)
若要缩小图像,一般情况下最好用CV_INTER_AREA来插值,而若要放 大图像,一般情况下最好用CV_INTER_CUBIC(效率不高,慢,不推荐 使用)或CV_INTER_LINEAR(效率较高,速度较快,推荐使用)。 -
图像平移:cv.warpAffine(img,M,dsize) 示例代码:
import cv2 import numpy as np img = cv2.imread('Rachel.jpg', 0) rows, cols = img.shape M = np.float32([[1, 0, 200], [0, 1, 100]]) dst = cv2.warpAffine(img, M, (cols, rows)) cv2.imshow('img', dst) k = cv2.waitKey(0) if k == ord('s'): cv2.imwrite('Rachel3.jpg', dst) cv2.destroyAllWindows() -
图像旋转:cv2.getRotationMatrix2D(center, angle, scale) 参数:center:旋转中心 angle:旋转角度 scale:缩放比例 返回:M:旋转矩阵 调用cv.warpAffine完成图像的旋转 示例代码:
import cv2 img = cv2.imread('Rachel.jpg', 0) rows, cols = img.shape M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 90, 1) dst = cv2.warpAffine(img, M, (cols, rows)) # 仿射变换,以后再说 cv2.imshow('Rachel', dst) cv2.waitKey(0) cv2.destroyAllWindows() -
仿射变换:

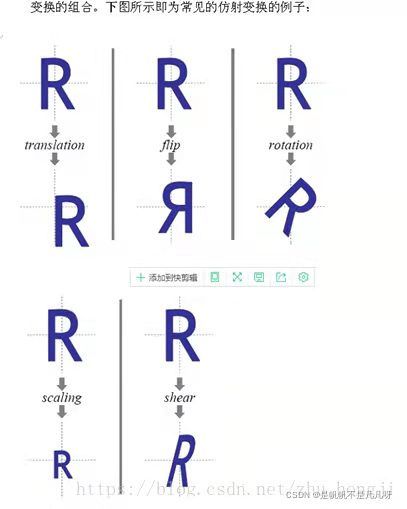
因此,空间变换中的仿射变换对应着五种变换,平移,缩放,旋转,翻转,错切。而这五种变化由原图像转变到变换图像的过程,可以用仿射变换矩阵进行描述。而这个变换过程可以用一个2*3的矩阵与原图进行相乘得到。
示例代码:
img = cv2.imread('Rachel.jpg')
rows, cols, ch = img.shape
pts1 = np.float32([[0, 0], [cols - 1, 0], [0, rows - 1]])
pts2 = np.float32([[cols * 0.2, rows * 0.1], [cols * 0.9, rows * 0.2], [cols * 0.1, rows * 0.9]])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('image', dst)
k = cv2.waitKey(0)
if k == ord('s'):
cv2.imwrite('Rachel1.jpg', dst)
cv2.destroyAllWindows()5.透射变换:透射变换是视角变化的结果,是指利用中心、像点、目标点三点共线的条件,按 透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有 的投影光线束,仍能保持承影面上投影几何图形不变的变换。
在opencv中,要找到四个点,其中任意三个不共线,然后获取变换矩阵T,再进行 透射变换。通过函数cv.getPerspectiveTransform找到变换矩阵,将cv.warpPerspective 应用于此3x3变换矩阵。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1 读取图像
img = cv.imread("./1.png")
# 2 透射变换
rows, cols = img.shape[:2]
# 2.1 创建变换矩阵
pts1 = np.float32([[56, 65], [368, 52], [28, 387], [389, 390]])
pts2 = np.float32([[100, 145], [300, 100], [80, 290], [310, 300]])
T = cv.getPerspectiveTransform(pts1, pts2)
# 2.2 进行变换
dst = cv.warpPerspective(img, T, (cols, rows))
# 3 图像显示
fig, axes=plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
axes[0].imshow(img[:, :, ::-1])
axes[0].set_title("原图")
axes[1].imshow(dst[:, :, ::-1])
axes[1].set_title("透射后结果")
plt.show()6.图像金字塔:

这里的向下与向上采样是对图像的尺度来说的 ,向上就是图像尺寸加倍,向下就是图像尺寸减半。
注意:pyrUp和pyrDown不是互逆的,即上采样不是下采样的逆操作。
pyrDown()是一个会丢失信息的函数。为了恢复原来更高分辨率的图像,要获得由于下采样操作所丢失的信息,这些数据就和拉普拉斯金字塔有关了。
图像的拉普拉斯金字塔可以由图像的高斯金字塔得到,转换的公式为:
![]()
拉普拉斯金字塔的图像看起来更像是边界图。
代码示例:
img = cv2.imread('D:/meishaonv.jpg', 0)
img1 = cv2.pyrDown(img) # 高斯金字塔
_img1 = cv2.pyrDown(img1)
_img = cv2.pyrUp(_img1)
_img=cv2.resize(_img,(408,423))
img2 = img1 - _img # 拉普拉斯金字塔
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果:
2.数据读取——视频
视频其实就是一帧阵的图片组成的,所以我们读取视频实际上是读取一帧一帧的图片。
import cv2
import matplotlib.pyplot as plt
vc=cv2.VideoCapture("qianxi.mp4")
#检查打开是否正确
if vc.isOpened():
open, frame= vc.read() #一它是一帧一帧向下读取的
else:
open=False
while open: #遍历视频的每一帧
ret, frame=vc.read()
if frame is None:
break
if ret==True:
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #转换成灰度图
cv2.imshow('result',gray)
if cv2.waitKey(1) & 0xFF==27:
break
vc.release()
cv2.destroyAllWindows()