人物交互算法(HOI)学习笔记之 ——QPIC
论文简介
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
[论文地址][https://arxiv.org/abs/2103.05399]
[代码地址][https://github.com/hitachi-rd-cv/qpic]
背景与摘要
HOI(Human Object Interaction)检测的目标是定位出图片中的人、物体以及他们之间的交互行为,通常表示为 <人物框,物体框,物体类别,动作类别>。
目前,HOI 的方法可以大致划分为两大类:两阶段和一阶段。两阶段的方法会先使用一个目标检测器定位出人和物体,然后再利用物体框区域的特征来预测交互动作类别。而一阶段方法则使用启发式定义的位置特征来预测交互,例如人和物体中心连线的中点。

然而,由于 CNN 网络的天然特性(卷积核的局部性)以及对特征的启发式利用方式,之前的方法不可避免地会遇到一些错误。比如,上图 (a) 中,要识别出洗车这个动作,手中拿的软管是一个关键,但是两阶段的方法如果只用到了人和汽车两个物体框区域的特征的话,显示会丢失一些上下文的关键信息。而如果用到两个物体框并集区域特征的话,又会不可避免地引入一些背景无关信息或者是干扰内容,比如上图 (b) 中扔飞盘和挡飞盘的动作互相重叠在一起。
一阶段的方法尝试将人和物体的特征聚合在一起,比如利用它们中心连线中点位置的特征,但是在上图 © 中,人与风筝的距离比较远,中点的特征和交互动作可能并没有关系,而在上图 (d) 中,两组交互行为的中点又距离过近,所以,这些基于 CNN 的方法在这些情况下很容易检测错误。
通过上述分析,我们发现传统的 CNN 存在以下缺陷:CNN 提取的都是局部特征,所以不能利用图片的全局特征;特征聚合阶段都是手工选取感兴趣区域,一些情况下不能覆盖到重要的上下文信息;多组交互行为距离过近时无法区分出各自对应的特征。
因此,本文提出了一种基于 transformer 的特征提取器,其中,注意力机制可以有效地在图片全局范围内聚合关键的上下文信息,而每个查询(query)最多用来预测一个[人-物体对]的设计,则可以避免将多组交互行为的特征混合。这种特征提取器可以学习到非常有效的嵌入特征,以至于下游的检测头可以设计得非常直观和简单。
方法介绍
整体框架和 DETR 基本是一样的,除了最后的检测头是针对 HOI 任务专门设计的。

对于一个输入大小为 x ∈ R 3 × H × W x\in R^{3\times H \times W} x∈R3×H×W 的图片,经过 CNN 提取到一个大小为 z c ∈ R D b × H ′ × W ′ z_c\in R^{D_b\times H' \times W'} zc∈RDb×H′×W′ 的特征图。如果以 ResNet50 为例,取的是 stage4 的特征图,图片尺寸经过了 5 次倍数为 2 的下采样,最终大小为 2048 × ⌈ H / 32 ⌉ × ⌈ w / 32 ⌉ {2048\times \lceil {H/32}\rceil \times \lceil{w/32}\rceil} 2048×⌈H/32⌉×⌈w/32⌉。
然后经过一层 1*1 的卷积,将特征图映射为 z c ∈ R D c × H ′ × W ′ z_c\in R^{D_c\times H' \times W'} zc∈RDc×H′×W′,文中 D c = 256 D_c=256 Dc=256。同时,引入位置编码 p ∈ R D c × H ′ × W ′ p\in R^{D_c\times H' \times W'} p∈RDc×H′×W′,二者相加后输入 encoder 得到编码后的特征。具体实现时, H ′ × W ′ {H' \times W'} H′×W′ 会展平成一个维度,相当于 NLP 任务中序列的长度。
在 decoder 阶段,会将一系列查询向量 Q ∈ R N × D c Q\in R^{N\times D_c} Q∈RN×Dc 转化成对应的嵌入特征,然后再分别经过对应的 FFN 即可得到人体框、物体框、物体类别和动作类别。文中 N 取 100,也即预测 100 个三元组,一般情况下可以覆盖图片中所有的动作交互。
查询向量 Q Q Q 初始化为全零,然后在训练阶段自己学习,相应地,查询向量也有其对应的位置编码信息,如下所示。
self.query_embed = nn.Embedding(num_queries, hidden_dim)
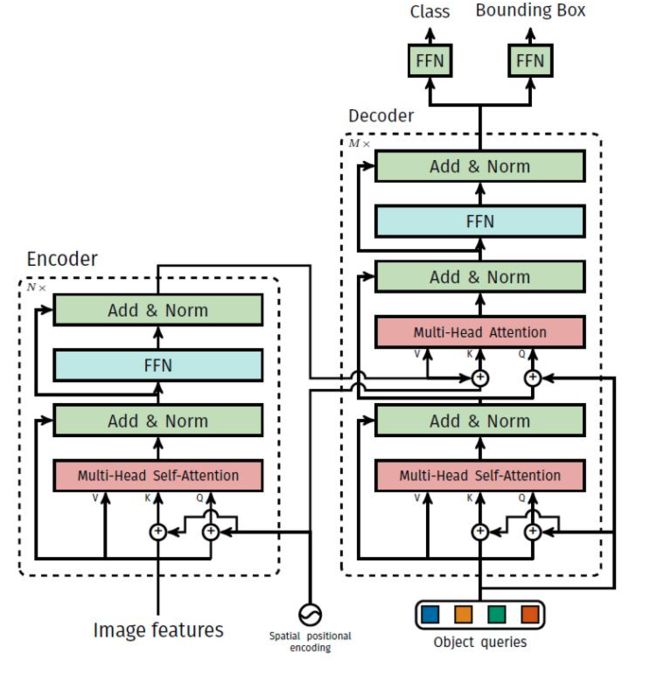
在 decoder 中,有两种注意力,一种是 object queries 的自注意力,另一种则是 object queries 和 encoder features 之间的注意力。在后者中,Query 是 object queries, Q ∈ R N × D c Q\in R^{N\times D_c} Q∈RN×Dc,而 Key 和 Value 则是 encoder features, K , V ∈ R H ′ W ′ × D c K,V\in R^{H'W'\times D_c} K,V∈RH′W′×Dc,由注意力的公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
可知,注意力权重矩阵的大小为 N × H ′ W ′ N\times H'W' N×H′W′,第一个 query 向量最后变成了预测的第一个三元组,所以注意力矩阵的第一行代表第一个 query 在所有空间位置的注意力权重。这也就解决了本文一开始提出的传统方法的缺点,全局性,每个三元组都能看到全局所有空间位置的信息;一个 query 只关注一组人-物体对,纵然多个三元组有重叠,但我每个 query 可以分别关注不同区域,也就能避免相互干扰;而且用注意力来让模型自己去学习该关注哪些地方来预测动作类别,而不是简单地人为设计用人体和物体框连线的中点。
模型的输出有四个,分别是 b h ∈ R N × 4 b^h\in R^{N\times 4} bh∈RN×4,代表人体框相对图片宽高归一化之后的四点坐标; b o ∈ R N × 4 b^o\in R^{N\times 4} bo∈RN×4,物体框坐标; c ∈ R N × ( N o b j + 1 ) c\in R^{N\times (N_{obj}+1)} c∈RN×(Nobj+1),物体类别,最后一层激活函数采用 softmax, N o b j N_{obj} Nobj 代表物体的类别总数,加 1 个类别是用来表示当前预测没有人-物体对; a ∈ R N × N a c t a\in R^{N\times N_{act}} a∈RN×Nact, N a c t N_{act} Nact 代表动作类别总数,最后一层激活函数采用 sigmoid,也即分别预测当前人-物体对是否有某一个交互动作,比如人和马可以同时存在人骑马和人坐在马上两个动作。
至于在推理的时候,总共可以得到 N × N o b j × N a c t N \times N_{obj} \times N_{act} N×Nobj×Nact 个三元组,每个三元组的得分为类别得分和动作得分相乘,然后通过阈值筛选出最后符合要求的三元组即可。
到目前为止,模型的结构应该是讲明白了,就差损失函数部分的理解,这也可以说是此方法的一大核心了。刚才我们说模型预测出了 100 个三元组,那怎么让这 100 个三元组和标签对应起来呢。
二分图匹配(bipartite matching)
首先,我们将标签中的三元组填充到 100 个,没有人-物体对的就是 ∅ \emptyset ∅,这也就是刚才分类的时候多一个类别的缘故。这样预测和标签都是 100 个三元组,接下来我们使用匈牙利算法(Hungarian Algorithm)来让预测的每一个三元组和标签中的三元组对应起来,使得对应后的匹配损失最小。也就是找到一个对应关系, i → ω ( i ) = j i \to \omega(i)=j i→ω(i)=j,标签中的第 i i i 个三元组对应预测的第 ω ( i ) \omega(i) ω(i) 也即是第 j j j 个三元组。其中,两个三元组的匹配损失定义为:
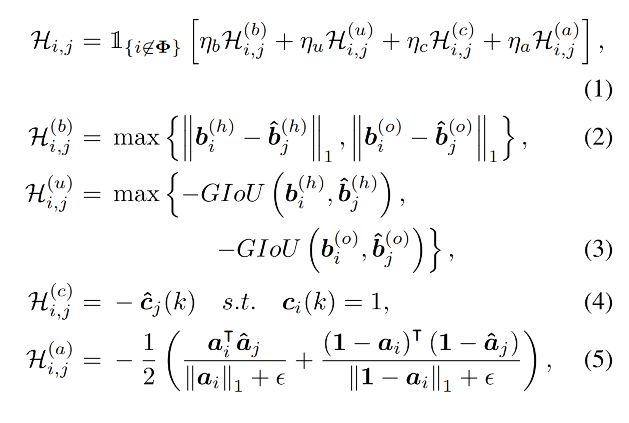
计算损失时只针对标签中的非空三元组,其中 H b \mathcal{H}^b Hb 取人体框和物体框 l 1 l_1 l1 损失的最大值, H u \mathcal{H}^u Hu 取人体框和物体框 G I O U GIOU GIOU 损失的最大值,之所以不取二者的均值是为了避免匹配时偏向于其中损失较小的一方; H c \mathcal{H}^c Hc 直接取对应物体类别预测概率的负值; H a \mathcal{H}^a Ha 使用一个加权平均以同时考虑动作类别的正负例数量,因为正例动作要远少于负例; η b , η u , η c , η a \mathcal{\eta}_b, \mathcal{\eta}_u, \mathcal{\eta}_c, \mathcal{\eta}_a ηb,ηu,ηc,ηa 分别是对应损失的超参数。
@torch.no_grad()
def forward(self, outputs, targets):
bs, num_queries = outputs['pred_obj_logits'].shape[:2]
out_obj_prob = outputs['pred_obj_logits'].flatten(0, 1).softmax(-1) # (bs, query_num, cls_num) -> (bs*query_num, cls_num)
out_verb_prob = outputs['pred_verb_logits'].flatten(0, 1).sigmoid()
out_sub_bbox = outputs['pred_sub_boxes'].flatten(0, 1)
out_obj_bbox = outputs['pred_obj_boxes'].flatten(0, 1) # (bs, query_num, 4) -> (bs*query_num, 4)
tgt_obj_labels = torch.cat([v['obj_labels'] for v in targets]) # (obj_num)
tgt_verb_labels = torch.cat([v['verb_labels'] for v in targets]) # (obj_num, verb_num)
tgt_verb_labels_permute = tgt_verb_labels.permute(1, 0)
tgt_sub_boxes = torch.cat([v['sub_boxes'] for v in targets])
tgt_obj_boxes = torch.cat([v['obj_boxes'] for v in targets]) # (obj_num, 4) obj_num为当前batch输入里面所有物体的个数
cost_obj_class = -out_obj_prob[:, tgt_obj_labels] # (bs*query_num, obj_num)
tgt_verb_labels_permute = tgt_verb_labels.permute(1, 0)
cost_verb_class = -(out_verb_prob.matmul(tgt_verb_labels_permute) / \
(tgt_verb_labels_permute.sum(dim=0, keepdim=True) + 1e-4) + \
(1 - out_verb_prob).matmul(1 - tgt_verb_labels_permute) / \
((1 - tgt_verb_labels_permute).sum(dim=0, keepdim=True) + 1e-4)) / 2
cost_sub_bbox = torch.cdist(out_sub_bbox, tgt_sub_boxes, p=1) # (bs*query_num, obj_num)
cost_obj_bbox = torch.cdist(out_obj_bbox, tgt_obj_boxes, p=1) * (tgt_obj_boxes != 0).any(dim=1).unsqueeze(0)
# (tgt_obj_boxes != 0).any(dim=1).unsqueeze(0) (1, obj_num) 四个坐标点只要有一个不为0就计算bbox损失
if cost_sub_bbox.shape[1] == 0:
cost_bbox = cost_sub_bbox
else:
cost_bbox = torch.stack((cost_sub_bbox, cost_obj_bbox)).max(dim=0)[0]
cost_sub_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_sub_bbox), box_cxcywh_to_xyxy(tgt_sub_boxes))
cost_obj_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_obj_bbox), box_cxcywh_to_xyxy(tgt_obj_boxes)) + \
cost_sub_giou * (tgt_obj_boxes == 0).all(dim=1).unsqueeze(0)
if cost_sub_giou.shape[1] == 0:
cost_giou = cost_sub_giou
else:
cost_giou = torch.stack((cost_sub_giou, cost_obj_giou)).max(dim=0)[0]
C = self.cost_obj_class * cost_obj_class + self.cost_verb_class * cost_verb_class + \
self.cost_bbox * cost_bbox + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu() # (bs, query_num, obj_num)
sizes = [len(v['obj_labels']) for v in targets]
# [(bs, query_num, obj_num0), (bs, query_num, obj_num1), (bs, query_num, obj_num2) ...]
# obj_num0 代表当前batch中第一张图片的物体个数,也即是三元组个数
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
此部分代码实现在 models/matcher.py/HungarianMatcherHOI 类中。由于当前 batch 中每一张图的标签三元组个数都可能是不相同的,所以,为了进行 batch 处理,是把当前 batch 标签中的所有三元组先合并在一起来计算匹配损失,最后再拆分开来一张图一张图地计算索引的对应关系。
比如,假设当前 batch 为 4,每张图片中的标签三元组个数分别为 [2, 2, 0, 1],那么 tgt_sub_boxes 经过 cat 操作后就变成了 5*4,代表有 5 个人体框。那么计算 cost_sub_box 的时候用预测的 400 个人体框和这 5 个框分别计算损失,最终的匹配损失经过 view 操作后大小为 [4, 100, 5],每张图片预测的 100 个三元组都和当前 batch 标签中的所有三元组计算了损失。
然后,split 操作会得到一个长度为 batch 的列表,其中第一个元素代表每张图片预测的 100 个三元组和当前 batch 中第一张图片中三元组的匹配损失,第二个元素也即代表和第二张图片中三元组的匹配损失。再加上一个 c[i] 的索引操作,即得到了每张图片的匹配损失矩阵。比如,第一张图的损失矩阵大小即为 [100, 2],scipy 库中的 linear_sum_assignment 函数则会返回预测的 100 个三元组中哪两个和标签中的 2 个三元组匹配时匹配损失最小。indices[0] = [[54, 98], [0, 1]],代表预测的第 54 个三元组和标签中第 1 个三元组匹配,第 98 个三元组和第 1 个匹配。
损失函数
弄明白了匹配过程,损失函数也就好说了,对于非空三元组,检测框损失依然采用 l 1 l_1 l1 损失和 G I O U GIOU GIOU 损失,只不过这里是人体框和物体框损失加在一起,而物体类别则采用 softmax 损失,动作类别采用 focal loss,如下所示:

当匹配的标签三元组为空的时候,则只计算物体类别和动作类别的损失,其中,物体类别的标签为 N o b j + 1 N_{obj}+1 Nobj+1,动作类别的标签为零向量,也即是没有动作。
由于 decoder 一般由多层组成,可以把每一层的输出都拿出来接上最后的检测头预测一下,然后计算每一层的损失,平均之后作为最终的损失。
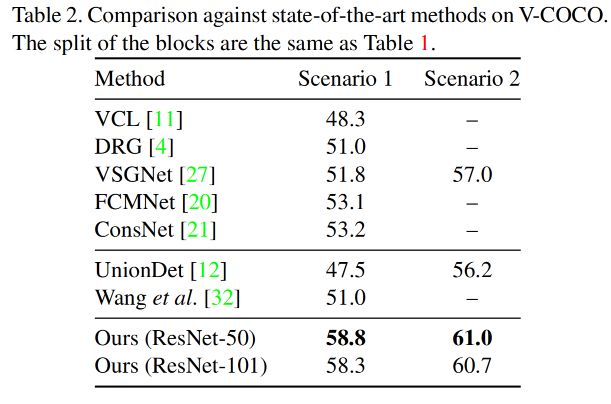
实验结果
在 HICO-DET 和 V-COCO 两个数据集上的实验效果如下所示,可以看到,相比之前的方法 mAP 均有比较明显的提升,验证了 transformer 强大的表示能力。