人物交互(human object interaction)论文汇总-2018年
1. Detecting and Recognizing Human-Object Interactions
1.1 总述
中心思想是以人为中心。假设是一个人的外表信息(姿态、衣服、动作等)是确定与他们交互的物体的有力线索(人的外表信息对于定位参与交互的物体可能处于何处是很有帮助的,根据此可以进一步缩小参与交互的目标物体的搜索空间)。为了利用这个线索,本文的模型学习了根据检测到的人和人的外表信息来预测特定动作的物体位置的密度。
1.2 网络结构

主要分为三个分支:目标检测分支、人为中心分支、交互分支。其中:
(1)目标检测分支的输入是卷积特征,输出是物体的框坐标以及分类分数 S h S_h Sh, S o S_o So,这部分和普通的目标检测类似。
(2)人为中心分支输入人的框的特征(通过RoiAlign),输出动作分数 S h a S_h^a Sha以及基于人外观信息计算的给定人-动作对的交互目标物体的预测位置 μ h a μ_h^a μha,后面用于计算 g ( h , o ) a g_(h,o)^a g(h,o)a—物体框 b o b_o bo是真实的交互目标的可能性。由于可同时有多种交互,所以 S h a S_h^a Sha输出采用二值Sigmod分类器用于多标签分类,使用二元交叉熵损失,而 μ h a μ_h^a μha部分的损失计算类似于边框回归。
(3)交互分支输入人框的特征和物体框的特征,然后这两个分支的两个A维向量求和再通过Sigmod得到A维得分S_(h,o)^a,同样使用二元交叉熵损失。
最终的得分为 S h ∗ S o ∗ S h a ∗ g ( h , o ) a S_h*S_o*S_h^a*g_(h,o)^a Sh∗So∗Sha∗g(h,o)a。训练时,所有分支都使用RPN训练。
1.3 密度预测
根据人的外观特征 ( b h ) (b_h) (bh)直接预测精确的目标物体的坐标是很难的,所以本文预测可能位置上的密度,后面将此与检测到的物体位置一起使用以定位参与交互的物体。
作者将目标物体位置上的密度建模为高斯函数,该函数的平均值 ( μ h a ) (μ_h^a) (μha)是根据人的外观和所执行的动作来预测的。 g ( h , o ) a = e x p ( ‖ b ( o ∣ h ) − μ h a ‖ 2 / ( 2 σ 2 ) ) g_(h,o)^a=exp(‖b_(o|h)-μ_h^a ‖^2/(2σ^2 )) g(h,o)a=exp(‖b(o∣h)−μha‖2/(2σ2))。使用g来表示物体框 b o b_o bo和预测目标位置 μ h a μ_h^a μha的相关性,也就是物体框 b o b_o bo是真实的交互目标的可能性。
此外, b ( o ∣ h ) b_(o|h) b(o∣h)是 b o b_o bo相对于 b h b_h bh的位置编码, 。方式类似于边框回归,损失函数使用的是smooth L1,在 b ( o ∣ h ) b_(o|h) b(o∣h)和 μ h a μ_h^a μha之间计算。
1.4 实验
推理时,通过下面这个公式来进行配对三元组:

它会选择一个高置信度且临近于一个得分较高的动作的预测目标位置的物体框。
在VCOCO数据集上达到了40.0,在HICO-DET数据集上达到了9.94.
下面是预测的密度的可视化例子:

2. Learning to Detect Human-Object Interactions
2.1 总述
本文是在提出HICO-DET数据集时提出的。核心思想是交互模式(即空间配置图),用以描述两个边界框(人和物)的空间关系,认为人与物体的空间关系对于学习交互知识是很重要的线索。
2.2 网络结构

常规的提取人物交互proposal的方式是根据RPN的目标检测proposal两两配对(人框和物框),这样的话人物交互的proposal就太多了。本文保留检测分数最高的若干个检测框(前10个),然后对于每个交互类别,将人框和物框组合配对以生成proposal(每个交互类别有10*10=100个proposal)。
主要分为三个分支,不同的分支从不同的来源提取特征,直观上围绕人类和物体的局部信息对于区分交互类别很重要,所以主要关注人和物体的特征。人分支、物体分支和人物对分支分别从人框上、物体框上、人物空间关系上提取特征。
人和物分支:从边界框裁剪图像,然后调整为固定大小,再通过卷积网络提取特征,最后输出得分。
每个分支最后是一个二进制分类器,输出交互分数。每个交互类别都有一个二进制分类器。最终的HOI得分是三个分支融合得来的。
2.3 空间关系编码(人物对分支)

空间配置图是一个2通道的二进制图像,第一个通道和第二个通道分别是人和物,框内部分值为1,框外为0.
对于同一种空间关系,无论人-物对位于图中什么位置,它的空间配置图应该是相同的,所以需要删去人-物对之外的像素。
不同的人-物框对的宽高比(以及大小)可能是不同的,而网络的输入需要固定的宽高比和大小,所以有两种方式处理:
- 空间配置图两边调整为固定大小,不考虑宽高比。
- 将空间配置图的较长的一边固定长度,保持宽高比,在短的一边填充0
接收空间配置图输入的网络有两种方式:
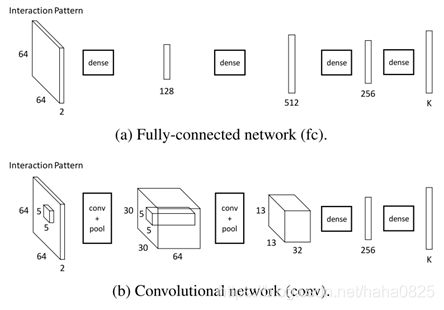
使用第二种(b)时效果更好。
因为HOI是多标签分类,所以应用Sigmod+交叉熵损失来训练该部分。总的loss为所有分支的loss之和。
2.4 实验
HICO-DET获得了10.4的结果。
3. Compositional Learning for Human Object Interaction
3.1 总述
本文探讨的是人物交互的zero-shot学习问题。现有方法未考虑使用外部先验知识,而且数据集中的交互类别是有限的,训练的模型无法推广使用。因此本文提出一种使用外部知识图和图卷积网络的方法。核心思想来自于VQA任务中的Compositional learning,不过本文侧重于人和物的交互。
日常交互动作可通过动词-名词对来描述,本文利用这些动词-名词对来学习交互。但是存在一个问题:模型如何学习在上下文中构成的新的交互类别。为此,本文探索使用外部先验知识来弥补这部分的缺陷,帮助进行交互的组合建模。具体来说就是,从知识库中提取三元组(主体、动词、客体,即主谓宾)来构建外部知识图,每个动词名词都是图形中的一个节点,单词嵌入是该节点的特征。每个三元组定义了一个相应的名词动词之间的路径,信息传递(训练)是是使用多层图神经网络实现的。最终将交互的zero-shot学习简化为图空间中的最近邻搜索问题。
3.2 网络结构
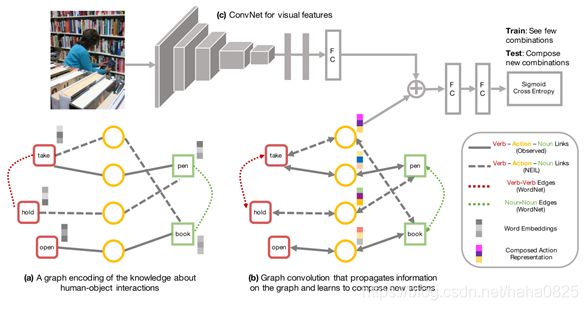
主要分为三个部分:
- 编码构建人物交互的知识图,通过使用WordNet构建。
- 对该图神经网络进行训练,来学习构建新的交互动作。
- 卷积神经网络提取视觉特征。
最终的结果来自于图神经网络特征和视觉特征的融合。网络的目标是学习一个得分函数:
其中,x是基础卷积网络提取的视觉特征, y v y^v yv和 y n y^n yn分别是动词和名词,K为交互动作的外部先验知识。本文核心就是通过一个图结构构建出K,并使用这个图学习组合新的交互动作。
交互的图表示如下图,其中圆圈代表交互动作:

3.3 实验
在HICO-DET上获得了21的mAP。
4. Learning Human-Object Interactions by Graph Parsing Neural Networks
4.1 总述
本文提出一种新的HOI识别框架—图解析神经网络(GPNN)。对于给定的一个场景,GPNN推断一个解析图,该图包括两部分,一个是由邻接矩阵表示的HOI图结构,一个是节点标签。
利用HOI图的结构化表示,可以显式地利用丰富的关系,并且可以有效地集成来自各个元素的信息并在结构上进行传播。整个模型和消息传递操作是定义明确且完全可微分的。因此,可以以端到端的方式从数据中高效地学习HOI知识。
4.2 网络结构

首先将所有的结点特征(所有物体,包括人)连成一个HOI图,经过网络学习得到的权重对该图的进行加权,然后得到的解析图中有的边较粗,有的较细,较粗的边对应于节点之间具有较强的信息,进而得到交互结果。
4.3 GPNN

人/物是结点,他们的关系是边。一个给定的HOI图,其中包含了所有的人物关系,通过保留有意义的边并标记结点来推断一个HOI解析图。
GPNN根据结点特征和边特征来推断出一个最佳的解析图,解析图是HOI图的一个子图。GPNN主要由四个函数组成,分别是link函数、message函数、update函数以及readout函数。
具体来说,链接函数(link)将边缘特征(F)作为输入,并推断节点之间的连通性。因此,构造了软邻接矩阵(A),并将其用作通过节点之间边缘的消息的权重。通过message函数汇总该节点的由其他节点传入的消息,然后通过update函数根据消息更新节点的隐藏嵌入状态。最后,readout函数计算每个节点的目标输出。
这四种函数的定义如下:
(1) link函数
输入节点特征和边特征,输出一个表示结点间连通性的邻接矩阵。然后开始在解析图上传播消息,其中软邻接矩阵通过边缘控制信息传递。
该部分的网络定义为具有一个或多个卷积层和Sigmod激活层的小型神经网络。使用1*1卷积,因为具有1×1内核的多个卷积层的本质效果类似于应用于每个边缘特征的全连接层,不同之处在于所有边缘均共享卷积权重。
(2) message函数和update函数
message函数汇总来自其他节点的消息;update函数根据汇总的消息来更新隐藏的结点状态。
Message函数的网络定义为拼接操作,拼接了结点隐藏状态或边特征的线性转换输出(通过全连接层线性转换)。Update函数使用循环神经网络中的Gated Recurrent Unit (GRU)实现。
(3) readout函数
对于每个结点,该函数读入隐藏状态,输出结点的HOI标签。
网络定义为几个全连接层组合在一起,再加上一个激活层(softmax或者sigmod)。
基于以上4个函数,消息沿着HOI图传递并由学习到的邻接矩阵A加权,最终得到解析图。
4.4 实验
在HICO-DET上达到了mAP13.11;在VCOCO上达到了mAP44.5。
5. Pairwise Body-Part Attention for Recognizing Human-Object Interactions
5.1 总述
常规的人物交互检测方法是将人视为一个整体,忽略了通常情况下是人的某个部位在与物体交互而不是整个人,仅关注身体部位并不能捕获重要的HOI语义,因为忽略了不同身体部位之间的相关性。所以作者认为在HOI识别中应该注意身体部位,而且对于某个交互来说不同的身体部位的重要性也不同,此外还应进一步考虑不同的身体部位之间的相关性。以此出发,本文提出一种身体部位对注意力网络,学习专注于关键身体部位以及其与HOI识别的相关性。身体部位对的引入减少了大量的误报,因为与HOI不相关的身体部位都被过滤掉了。
5.2 网络结构

网络首先从一组proposal中提取人、物体和场景的视觉特征。使用ROI-pairwise Pooling(a)对不同身体部位的特征及其成对相关性进行编码。然后,成对的身体部位注意模块(b)将选择那些重要的身体部位对的特征图。来自人、物体和场景的全局外观特征(c)也用于预测。最终的预测来自于身体注意力模块的结果和全局外观特征的结果的融合。
采用MIL(Multiple Instance Learning)解决图像中多人同时出现的问题。MIL层的输入是图像中每个人的预测,其输出是分数数组,该分数数组采用所有输入预测中每个HOI的最大分数。
5.3 全局外观特征
该部分从全局来考虑,利用整个人、物体和场景的特征进行HOI识别。在基础网络得到的特征图上,ROI Pooling为每个人和物体以及场景在给定其边界框的情况下提取ROI特征。对于每个检测到的人,将他的特征与物体特征以及场景特征连接起来作为该部分的最终特征。
给定一个物体边界框,一个简单的解决方案是提取相应的特征图,然后将其与人和场景的现有特征连接起来。然而,这种方法对于HOI识别的任务没有太大的改进,因为物体和人之间的相对位置没有被编码。因此,本文将ROI作用于检测到的人与物体的联合框而不是每个单独的人/物框。
HICO数据集中,图像中可以有多个人和多个物体。 对于每个人,可以在他周围共同出现多个物体。为解决此问题,作者对不同物体和人的多个联合框进行采样,并将ROI池分别应用于每个联合框。围绕一个人采样的物体总数是固定的。
5.4 局部身体部位对特征
(1) ROI-pairwise Pooling

R 1 R_1 R1和 R 1 R_1 R1分别代表不同身体部位的边界框, R u R_u Ru代表身体部位对的联合框。常规做法是取一个人的所有的身体部位对,但是若该对中的两个身体部位相距较远则联合框包含了大量的与HOI不相关的信息,为此ROI-pairwise pooling层提取 R 1 R_1 R1和 R 2 R_2 R2的框内区域特征,框外区域将被丢弃(设为0)。对于ROI-pairwise pooling中每个采样的网格位置,对网格区域内的最大值进行采样。
(2) Attention Module
身体部位对的数量很大(若有n个身体部位,则数量为 C n 2 C_n^2 Cn2),而其中相互关联的对很少,所以作者用注意力模块自动发现那些有重要的相关联的对。

根据由ROI-pairwise pooling层池化的逐对身体部位特征图(pair 1—pair m),应用FC层来估计注意力得分,这些得分代表了该身体部位对的重要性。然后,将注意力分数与身体部位特征图相乘。最后,引入特征选择层,该层选择前k个最重要的身体部位对(根据得分),并将它们的reweight特征图传播到下一步。
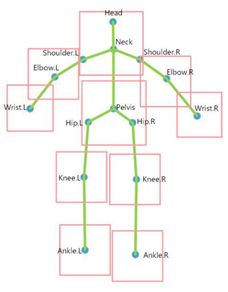
(3) 身体部位框的构建
首先利用姿态估计器估计人体关键点,然后根据这些关键点定义十个人体部位,然后这些部位定义为规则的边界框,边长与人体框大小成正比。
6. iCAN: Instance-Centric Attention Network for Human-Object Interaction Detection
6.1 总述
本文提出了端到端可训练的以实例为中心的注意力模块用于学习使用人或外观突出信息区域的物体实例。假设是一个实例的外观(无论是人还是物)提供关于图像中我们应该注意的位置的提示。例如,更好地确定一个人是否携带物体,应该将其注意力集中在拿着物体的人的手周围的区域。以实例为中心的注意力网络(iCAN)为每个检测到的人或物体动态生成注意力图以突出显示与任务相关的区域。
6.2 网络结构

所提出的模型主要包括以下三个分支:
1)基于人类外观检测交互的人的分支;
2)基于物体外观预测交互的物体的分支;
3)用于编码人类和物体边界框之间的空间布局的成对分支。
首先给定由Faster R-CNN检测到的目标实例,使用所有人-物体对生成HOI假设。然后融合来自各个分支的动作分数以产生最终预测。
6.3 iCAN模块

给定图像的卷积特征(以灰色显示)和人/物体边界框(以红色显示),iCAN模块提取实例 x i n s t h x_{inst}^h xinsth(人类)或 x i n s t o x_{inst}^o xinsto(物体)的外观特征, 作为以实例为中心的注意力图的特征。
为了计算注意力图,首先使用ROI Pooling提取实例级外观特征,即通过残差块、全局平均池化以及全连接层得到512维的特征。
接下来是将实例级外观特征和卷积特征图嵌入到512维空间中,并使用向量点积测量该嵌入空间中的相似性。然后通过应用Softmax获得以实例为中心的注意力图。注意图突出显示图像中的相关区域,其可以有助于识别与给定人/物体实例相关联的HOI。
最后通过计算注意力特征和卷积特征融合后特征的加权平均值来提取上下文特征。iCAN模块的最终输出是实例级外观特征和基于注意力的上下文特征的融合(拼接),即使用1×1卷积和人类实例外观特征 x i n s t h x_{inst}^h xinsth将图像特征嵌入到全连接层中。
其中,res5表示第五残差块,GAP表示全局平均池化层,FC表示全连接层。
6.4 实验
在HICO-DET上达到了14.84的mAP;在VCOCO上达到了45.3的mAP。其中通过添加iCAN模块,AP提高了1.5.