MySQL高级【索引概述&索引结构】
目录
索引概述
无索引演示:一种表没有索引的查找方式
有索引演示:以二叉树进行演示
索引的优缺点
索引结构
二叉树:
B-Tree(多路平衡查找树)
B+Tree树
Hash数据结构
索引概述
索引它是一种有序的数据结构,这种数据结构是用来做什么的?用来高效获取数据的,
在我们的数据库表结构当中,除了要保存原始数据之外,
还需要去维护索引这种数据结构,那么要通过这种数据结构来指向原始数据,
这样就可以在这种数据结构当中通过高级的查找算法,快速定位到原始数据,
这种数据结构就叫做索引

无索引演示:一种表没有索引的查找方式

我要查找age=45的人的信息,这个时候,就会根据sql语句在表中进行查找
依次查找每一条数据,进行比对,符合条件就查找到了,没有符合条件的就
查找到数据的最底部,这种是无索引表的查找方式,被称为全表扫描
有索引演示:以二叉树进行演示
如果以age建立索引,就需要去维护这样一个二叉树,当我们往
这种表中插入一条数据时,那么就需要维护这个二叉树
的节点, 那么这个二叉树的节点就需要指向这条数据的地址
,再插入一条数据二叉树的新节点就指向这条数据的新地址
再重新查找age =45 的 它会先比对头节点,比头节点大
就去右边比对,小就去左边树比对
这个二叉树并不是真实的索引结构,只是为了理解
索引的优缺点
优点:
1,降低数据库的IO成本,因为数据库的数据是操作磁盘的,你要操作数据就会和磁盘进行交互,有了索引,降低了交互次数,从而也减少IO成本(提高了查询效率)
2, 通过索引对数据进行了重新排序,降低了以往数据排序的成本,降低了cpu的消耗(提高了排序效率 )
3,提高了数据的检索效率
缺点:
1,索引需要占用磁盘空间(可以忽略)
2,降低了更新的表的速度,但是(一般在考虑给表加索引的时候,这两点可以忽略不及,
磁盘很便宜,2在正常的业务系统中,增删改的比例很小,主要是查询)
索引结构
不同的存储引擎存在不同的索引结构,而不同的索引结构是由不同的数据结构实现的
mysql的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含,B+Tree索引,Hash索引,R-tree索引(空间索引),Full-text(全文索引)
| 索引结构 | 描述 |
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+ 树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的, 只有精确匹配索引列的查询才有效, 不 支持范围查询 |
| R-tree(空间索 引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类 型,通常使用较少 |
| Full-text(全文 索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于 Lucene,Solr,ES |
上述是MySQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持 情况。
| 索引 | InnoDB | MyISAM | Memory |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
注意: 我们平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引。
二叉树:

二叉树:每个节点下有两个节点,插入的形式是,当第一个节点是36,插入第二个数据比36小放入左侧,比36大就放入右侧,最终形成二叉树
如果进行查询上图中的17数据,查找次数为:
第一次:比较头节点36,不匹配第一次查询,比36小进入左侧节点进行比较
第二次:17和左侧节点22进行比较,不匹配,比左侧节点小,进入下一层的左侧节点
第三次:17和左侧节点19进行比较,不匹配,比左侧节点小,进入下一层的左侧节点
第四次:17和左侧节点17进行比较,不匹配,数据值相等,完成查询
总共查询四次
二叉树的两个弊端:
第一个弊端:
当数据顺序插入一组数据,最终形成了一个单项链表,例如插入一组

36,34,33,23,22,20,19,17
这时顺序插入时会形成单项链表,查询性能会大大降低
因为:这是查询17,第一次比对36,第二次比对34,第三次比对33,第四次比对23,第五次比对22,第六次比对20,第七次比对19,第八次比对成功
这时:查询次数是八次,次数大大的提升,就造成了查询性能大大降低。
第二个弊端:
在大数据的情况下,二叉树的层级就变得很深,因为每个节点下面只能挂载两个节点,大数据量的情况下,会形成很大的层级,层级变深,查询次数加大,检索速度很慢
第一个弊端解决:
就引入了红黑树,红黑树是一个自平衡的二叉树,当顺序插入时,形成了单项列表,红黑树通过本身的特性左旋一下右旋一下,构成了一个平衡的二叉树

这时重新查找17,只需要四次,提高了一倍的检索效率,第一次弊端就解决
当然:红黑树也是一个二叉树,在数据量大的情况下,也同样存在检索效率变慢的问题
为了解决这个问题,就引入了另外一种数据结构,B-Tree
B-Tree(多路平衡查找树)
多路:为什么要称为多路呢!多路就是一个节点下可以挂载多个子节点
例如:一颗最大度数(max-degree)为5(5阶)的b-tree,(每个节点下有五个节点,每个节点可以存储四个key,5个指针进行指向)
树的度数:是指一个节点的子节点个数

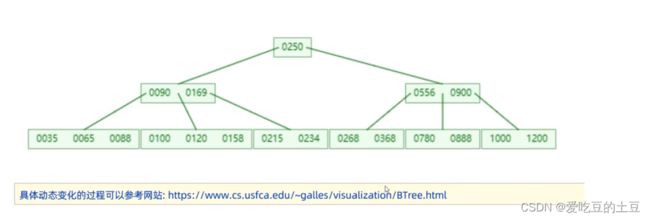
B+Tree树
B+Tree
第一个特点:所有的数据都会出现在叶子节点,就是说下一层的叶子节点会包含上一次非叶子节点的数据
,非叶子节点起到一个指向的作用
第二个特点:叶子节点会形成一个单向的链表!

在MySQL索引数据结构对经典的B+Tree进行了优化,!在B+tree的基础上面,增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问时候的性能!
Hash数据结构

采用hash作为索引结构,哈希索引就是采用一定的hash算法,将键值通过算法换成新的hash值,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的hash表的槽位中,他们就产生了hash冲突(也成为hash碰撞),可以通过链表进行解决
(如果hash表中有相同的hash值,那就给这个hash值对应hash表中的槽位,赋予一个链表,将冲突的值依次追加到链表中)

Hash索引的特点
1,hash索引只能用于等值查询(=,in),不支持范围查询(between,<,>)
2,无法利用索引完成排序操作,因为hash算法出来的hash值是无序的
3,查询效率高,通过只需要一次检索就可以了,效率通常要高于B+tree索引(这边通常是指不出现hash碰撞的情况下,如果出现hash冲突,还需要进行查找链表,这时效率会影响)
在Mysql中,支持hash索引的是Memory引擎,而InnoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的