01_the_machine_learning_landscape
1. How would you define Machine Learning?
Ans: Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure.

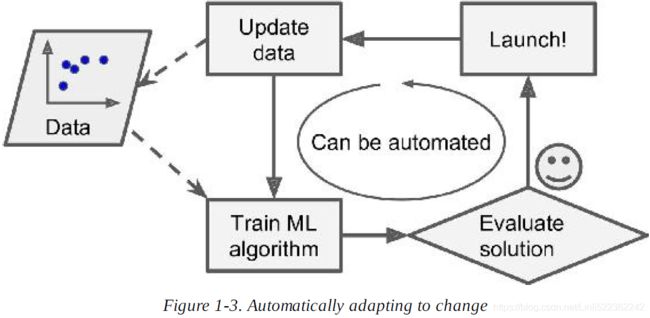
2. Can you name four types of problems where it shines?
Ans: Machine Learning is great for complex problems for which we have no algorithmic solution(the best Machine Learning techniques can find a solution), to replace long lists of hand-tuned rules(one machine learning algorithm can often simplify code and perform better), to build systems that adapt to fluctuating environments(a Machine learning system can adapt to new data), and finally to help humans learn(e.g., data mining; geting insights about complex problems and large amounts of data).

3. What is a labeled training set?
Ans: A labeled training set is a training set that contains the desired solution(called label) for each instance.
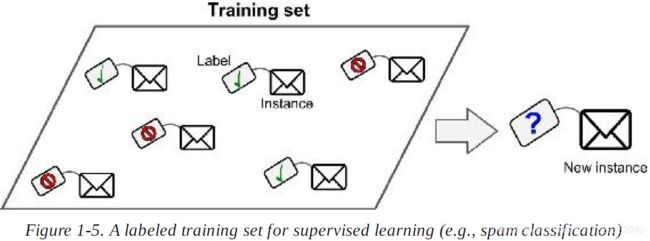
4. what are the two most common supervised tasks?
ans: The two most common supervised tasks are regression(this task is to predict a target numeric value, given a set of features) and classification.
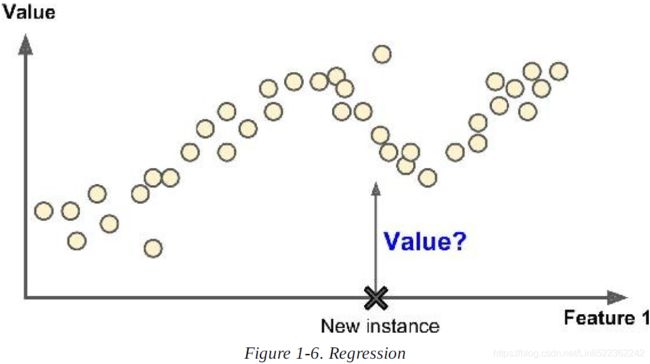
Note that some regression algorithm can be used for classification as well, and vice versa. For example, Logistic Regression is commonly used for classification, as it can output a value that corresponds to the probability of belonging to a given class.
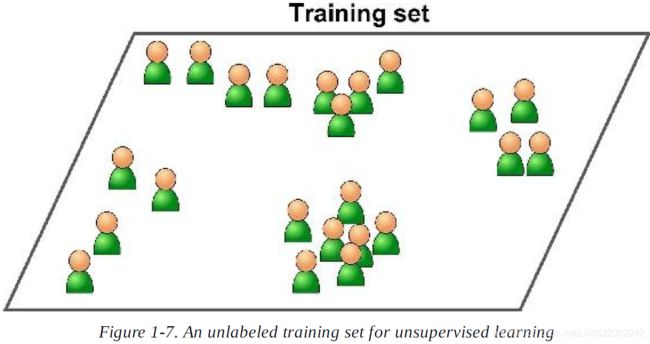
5. Can you name four common unsupervised tasks?(the training data is unlabeled)
Ans: Common unsupervised tasks include clustering, (run a clustering algorithm to try to detect groups of similar visitors.)
{k-Means, Hierarchical Cluster Analysis, Expectation Maximization)
visulization,(Visualization algorithms are also good examples of unsupervised learning algorithms: you feed them a lot of complex and unlabeled data, and they output a 2D or 3D representation of your data that can easily be plotted . These algorithms try to preserve as much structure as they can (e.g., trying to keep separate clusters in the input space from overlapping in the visualization), so you can understand how the
data is organized and perhaps identify unsuspected patterns.)
{Principal Component Analysis, Kernel PCA, Locally-Linear Embedding, t-distributed Stochastic Neighbor Embedding}
dimensionality reduction, (merge several correlated features into one. It will run much faster, the data will take up less disk and memory space, and even in some cases it may also perform better.)
and association rule learning.(the goal is to dig into large amounts of data and discover interesting relations between attributes)
{Apriori, Eclat}
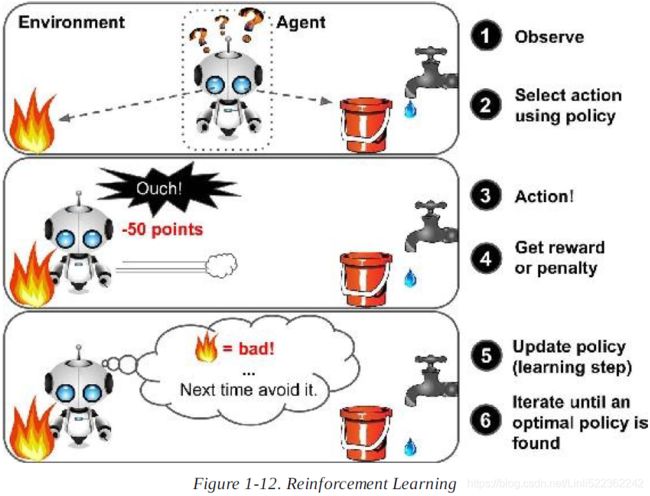
6. What type of Machine Learning algorithm would you use to allow a robot to walk in various unknown terrains(地形)?
Ans: Reinforcement Learning is likely to perform best if we want a robot to learn to walk in various unknown terrains since this is typically the type of problem as a supervised or semisupervised learning problem, but it would be less natural.(Reinforcement Learning system called an agent in the context, can observe the environment, select and perform actions, and get rewards in return or penalities in the form of negative rewards. It must then learn by itself what is the best strategy, called a policy to get the most reward over time. A policy defines what action the agent should choose when it is in given situation)
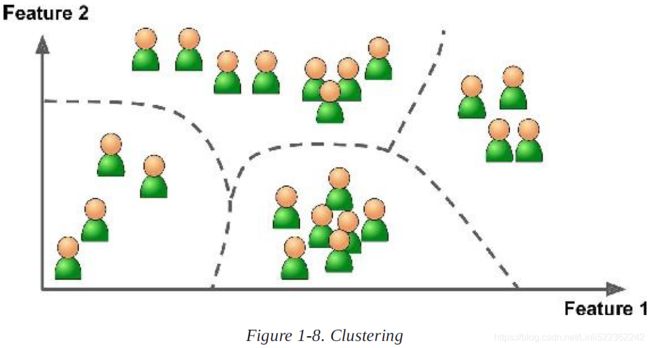
7. What type of algorithm would you use to segment your customers into multiple groups?
Ans: If you don't know how to define the groups, then you can use a clustering algorithm (unsupervised learning) to segment your customers into clusters of similar customers. However , if you know what groups you would like to have, then you can feed many examples of each group to a classification algorithm(supervised learning), and it will classify all your customers into these groups.
8. Would you frame the problem of spam detection as a supervised learning problem or an unsupervised learning problem?
Ans: Spam detection is a typical supervised learning problem: the alorithm is fed many emails among with their label(spam or not spam).
9. What is an online learning system?
Ans: An online learning system can learn incrementally, as opposed to a batch learning system. This makes it capable of adapting rapidly to both changing data and automous systems, and of training on very large quantities of data.

10. What is out-of-core learning?
Ans: Out-of-core algorithm can handle vast quantities of data that cannot fit in a computer's main memory. An out-of-core learning algorithm chops the data into mini-batches and use online learning techniques to learn from these mini-batches.
11. What type of learning algorithm relies on a similarity measure to make predictions?
Ans: An instance-based learning system learns the training data by heart; then, when given a new instance, it uses a similarity measure to find the most similar learned instances and uses them to make predictions.
for example: A (very basic) similarity measure between two emails could be to count
the number of words they have in common. The system would flag an email as spam if it has many words
in common with a known spam email.

12. What is the difference between a model parameter and a learning algorithm’s
hyperparameter?
Ans: A model has one or more model parameters that determine what it will predict given a new instance(e.g.,
the slope of a linear model). A learning algorithm tries to find optimal values for these parameters such that the model generalizes well to new instances. A hyperparameter is a parameter of the learning algorithm itself, not of the model(e.g., the amount of regularization to apply during learning can be controlled by a hyperparameter.). it must be set prior to training and remains constant during training.
Constraining a model to make it simpler and reduce the risk of overfitting is called regularization.

13. What do model-based learning algorithms search for? What is the most common
strategy they use to succeed? How do they make predictions?
Ans: Model-based learning algorithms search for an optimal value for the model parameters such that
the model will generalize well to new instances. We usually train such systems by minimizing a cost function
that measures how bad the system is at making predictions on the training data, plus a penalty for model
complexity if the model is regularized. To make predictions, we feed the new instance's into the model's prediction function, using the parameter values found by the learning algorithm.
14. Can you name four of the main challenges in Machine Learning?
Ans: Some of the main challenges in Machine Learning are the lack of data, poor data quality, nonrepresentative data,
uninformative features, excessively simple models that underfit the training data, and excessively complex models
that overfit the data.
15. If your model performs great on the training data but generalizes poorly to new
instances, what is happening? Can you name three possible solutions?
Ans: If a model performs great on the training data but generalizes poorly to new instances, the model is likely
overfitting the training data(or we got extremely lucky on the training data). Possible solutions to overfitting are
getting more data, simplifying the model(selecting a simpler algorithm, reducing the number of parameters or
features used, or regularizing the model), or reducing the noise in the training data.
Constraining a model to make it simpler and reduce the risk of overfitting is called regularization.
16. What is a test set and why would you want to use it?
Ans: A test set is used to estimate the generalization error that a model will make on new instances, before the model
is launched in production.
17. What is the purpose of a validation set?
Ans: A validation set is used to compare models. It makes it possible to select the best model and tune the hyperparameters.
You train multiple models with various hyperparameters using the training set, you select the model and
hyperparameters that perform best on the validation set, and when you’re happy with your model you run
a single final test against the test set to get an estimate of the generalization error.
18. What can go wrong if you tune hyperparameters using the test set?
Ans: If you tune hyperparameters using the test set, you risk overfitting the test set, and the generalization error
you measure will be optimistic(you may launch a model that performs worse than you expect).
19. What is cross-validation and why would you prefer it to a validation set?
Cross-validation is a technique that makes it possible to compare models (for model selection and hyperparameter tuning) without the need for a separate validation set. This saves precious training data.
To avoid “wasting” too much training data in validation sets, a common technique is to use crossvalidation:
the training set is split into complementary subsets, and each model is trained against a
different combination of these subsets and validated against the remaining parts. Once the model type and
hyperparameters have been selected, a final model is trained using these hyperparameters on the full
training set, and the generalized error is measured on the test set.
20. How is machine learning distinct from traditional programming?
Machine learning algorithms learn from the data.
21. Machine learning is the practice of using algorithms to analyze _data_, learn from this, and then make a determination or prediction about new data.
22. With machine learning, programmers typically write explicit code to accomplish tasks. False
23. Deep learning is a type of machine learning. True
24. Machine learning can be used to solve classification problems. True