neo4j基本使用及其Python语言操作
文章目录
一、Neo4j的安装与启动
二、Neo4j在Pycharm中的调用
三、Neo4j指令介绍
四、Neo4j在Pycharm下的指令
五、Neo4j简介及应用场景
六、Neo4j与Python交互
1、环境与调用问题
2、版本问题
3、修改结点以及删除结点
七、结点构建方法
1、Python直接去重构建
2、运用查询语句构建
3、使用Neo4j Desktop导入csv文件构建
一、Neo4j的安装与启动
1、环境配置:JKD 11.0.12 (neo4j最新版本只支持JKD 11,JDK 9、JDK 15、JDK 16、JDK 17版本均不可使用)
2、Neo4j压缩包下载:https://neo4j.com/download-center/#enterprise
3、安装完成后,打开cmd,Neo4j启用命令:neo4j.bat console
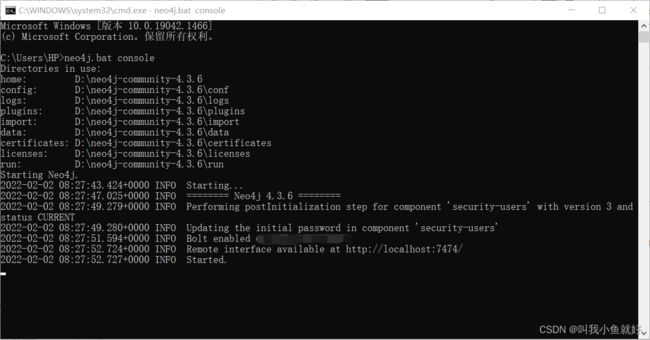
4、根据第三步命令执行后给出的链接,如:http://localhost:7474/,访问网址,打开Neo4j,期间cmd勿关闭
5、第一次使用需要重置密码(密码一定要记住,目前没看到靠谱的找回密码的方式!!!)
二、Neo4j在Pycharm中的调用
启动cmd,输入命令:pip install py2neo==4.3.0 -i https://pypi.douban.com/simple (安装py2neo)
注意:不能输入命令pip install py2neo,该命令会安装最新版本,执行Python程序时会报错“ValueError: The following settings are not supported: {‘http_port‘: 7474}”等问题,或报账号密码错误
报错原因:py2neo版本过高
from py2neo import Graph
graph = Graph('http://localhost:7474/', username='neo4j', password='******')
# '******'为您设置的密码
三、Neo4j指令介绍
![]()
(指令输入栏,如下代码为Neo4j指令代码)
1、MATCH(n) DETACH DELETE n //删除所有图
2、CREATE (n:Person {name:'John'}) RETURN n
CREATE (n:Person {name:'Mike'}) RETURN n //创建名字为John、Mike,种类为Person的结点
3、MATCH (a:Person {name:'John'}), (b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b) //建立John和Mike的friend关系
4、MATCH (a:Person {name:'Shawn'}), (b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b) //由3增加属性
5、MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'})
MERGE (a)-[:BORN_IN {year:1978}]->(b) // 设置地点和人物的关系
6、MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b //查询出生在这个地方的人(查询)
7、MATCH (a)-->() RETURN a // 查询所有对外有关系的结点
8、MATCH (a)--() RETURN a // 查询所有有关系的结点
9、MATCH (a)-[r]->() RETURN a.name, type(r) // 查询所有对外有关系的节点,以及关系类型
10、MATCH (a:Person {name:'Liz'}) SET a.age=34 // 修改结点的某个属性
11、MATCH (a:Location {city:'Portland'}) DELETE a // 删除结点(存在关联无法删除)
12、MATCH (r) WHERE id(r)=12(其他ID也可) DETACH DELETE r //删除有关系的结点
13、MATCH(p1:College{name:'计算机学院'})-[r:`所属于`]-(p2:School) DELETE r // 删除结点关系
14、MATCH (s:College{name:'计算机学院'}),(t:School{name:'内蒙古大学'}) create (s)-[r:`所属于` ]->(t) //用已有关系类别创建关系
四、Neo4j在Pycharm下的指令
构建结点代码:
from py2neo import Node, Relationship, Graph, NodeMatcher, RelationshipMatcher
graph = Graph('http://localhost:7474/', username='neo4j', password='04051835a')
Person2 = Node('Person', name='于一博')
graph.create(Person2) # 创建结点
Person3 = Node('Person', name='杨聪浩')
graph.create(Person3) # 创建结点
relation16 = Relationship(Person2,'室友',Person3)
graph.create(relation16) # 创建关系
查询结点代码:
match = nodematcher.match('Person') # 查询结点
for node in match:
print(node)
print(list(match))
删除结点代码:
graph.delete(Person3) # 删除Person3结点
graph.delete(relation3) # 删除relation3中所包含的结点及其所有关系
五、Neo4j简介及应用场景
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。
其图形数据结构表示为,在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
主流应用领域:
金融行业应用
反欺诈多维关联分析场景
通过图分析可以清楚地知道洗钱网络及相关嫌疑,例如对用户所使用的帐号、发生交易时的IP地址、MAC地址、手机IMEI号等进行关联分析。
社交网络图谱
在社交网络中,公司、员工、技能的信息,这些都是节点,它们之间的关系和朋友之间的关系都是边,在这里面图数据库可以做一些非常复杂的公司之间关系的查询。比如说公司到员工、员工到其他公司,从中找类似的公司、相似的公司,都可以在这个系统内完成。
企业关系图谱
图数据库可以对各种企业进行信息图谱的建立,包括最基本的工商信息,包括何时注册、谁注册、注册资本、在何处办公、经营范围、高管架构。围绕企业的经营范围,继续细化去查询企业究竟有哪些产品或服务,例如通过企业名称查询到企业的自媒体,从而给予其更多关注和了解。另外也包括对企业的产品和服务的数据关联,查看该企业有没有令人信服的自主知识产权和相关资质来支撑业务的开展。
六、Neo4j与Python交互
1、环境与调用问题
使用Python对Neo4j进行查找操作前,应匹配所有结点
代码为:
from py2neo import Graph , Node , Relationship,NodeMatcher
g = Graph('http://localhost:7474/', username='neo4j', password=’********’)
matcher = NodeMatcher(match_graph)
nodes = matcher.match('Province') # Province 可根据要求替换# 当Python环境为3.6版本,neo4j Desktop版本为1.4.8,py2neo版本为4.3.0时,不能使用matcher.match() .all()
for node in nodes:
print(node['name']) # name 根据要求替换,无该属性时会返回None2、版本问题
Neo4j版本1.4.8,Python版本3.6 的条件下 py2neo4.3.0版本无法使用
NodeMatcher(graph).match().all()
py2neo4.0.0版本可使用NodeMatcher(graph).match().all(),但无法与当前版本的Neo4j建立连接
py2neo最新版本无法直接访问Neo4j,情况同py2neo4.0.0版本近似 py2neo3.1.2版本支持Python3.5以下版本
因此推荐使用py2neo 2020.1.0版本
3、修改结点以及删除结点
修改结点
from py2neo import Graph,Node,Relationship,NodeMatcher,Subgraph
match_graph = Graph('http://localhost:7474/', username='neo4j', password=‘*******’)
matcher = NodeMatcher(match_graph)
tx = match_graph.begin()
change_Person_node = matcher.match('Person').all() # .all()注意版本问题,4.3.0可调用.first(),但无法调用.all()
print(change_Person_node)
new_Person_nodes = []
for node in change_Person_node:
node['name']='P'+node['name']
new_Person_nodes.append(node)
Sub = Subgraph(nodes=new_Person_nodes)
tx.push(Sub) # 应使用py2neo 2020.1.0版本,py2neo 4.3.0版本本条语句报错:AttributeError: 'str' object has no attribute 'graph'
tx.commit()
删除结点
matcher = NodeMatcher(match_graph)
num = len(matcher.match('Person'))
for i in range(num):
nodes = matcher.match('Person').first() # 不能使用.all()语句,显示neo4j语法错误
match_graph.delete(nodes)
# g.delete()删除关系时会连带删除与其连接的结点
# g.separate()删除关系时只删除关系
# g.separate()可进行删除关系批处理,但删除满足条件的结点,要执行上述删除代码
七、结点构建方法
1、Python直接去重构建
from py2neo import Node, Relationship, Graph
import pandas as pd
CSV_1 = pd.read_csv('text1.csv',error_bad_lines=False,encoding='GBK')
CSV_2 = pd.read_csv('text2.csv',error_bad_lines=False,encoding='GBK')
CSV_3 = pd.read_csv('text3.csv',error_bad_lines=False,encoding='GBK')
CSV_4 = pd.read_csv('text4.csv',error_bad_lines=False,encoding='GBK')
CSV_5 = pd.read_csv('text5.csv',error_bad_lines=False,encoding='GBK')
graph = Graph('http://localhost:7474/', username='neo4j', password=‘******’)
.........
# 直接通过pandas导入我的CSV文件,在pycharm中对数据进行分类建立结点
# 定义一个空集合,添加新建的结点,添加时判断该结点是否存在,若不存在再进行添加
# 在建立关系时,调用集合,找出.__name__属性分别等于关系两端数据名的数据建立关系
for i in range(Listnum_5):
for j in range(Cows_n):
if str(CSV_5.iloc[i][6])==str(Cows_sum_list[j].__name__):
Node_1 = Cows_sum_list[j]
pass
for k in range(Name_n):
if str(CSV_5.iloc[i][4])==str(Name_sum_list[k].__name__):
Node_2 = Name_sum_list[k]
pass
graph.create(Relationship(Node_2,"奶畜品种",Node_1))
2、运用查询语句构建
调用并使用matcher查询语句进行构建
读取csv数据表中的数据,同时构建结点与关系
构建结点前使用matcher语句进行查询,判断当前关系所连接结点是否构建
若构建,调用结点;若没有构建,构建结点,再进行关系的连接
3、使用Neo4j Desktop导入csv文件构建
(1)数据预处理
# coding:utf-8
# coding=gbk
import pandas as pd
import os
import numpy as np
file = 'new_train.csv'
data = pd.read_csv(file,error_bad_lines=False,encoding='GBK',chunksize=48)
for_data = data.iterrows()
def save_data(index,data,base_path):
if not os.path.exists(base_path):
os.mkdir(base_path)
line_count = data.shape[0]
entity_df = pd.DataFrame()
relationship_df = pd.DataFrame()
for _,line in for_data:
entity0 = line.名称
label = line.属性
entity1 = line.值
entity_df = entity_df.append({
":ID":hash(entity0),
"name":entity0,
"LABEL":'ENTITY'
},ignore_index=True)
entity_df = entity_df.append({
":ID":hash(entity1),
"name":entity1,
"LABEL":'ENTITY'
},ignore_index=True)
relationship_df = relationship_df.append({
':START_ID':hash(entity0),
'name':label,
'END_ID':hash(entity1),
':TYPE':'RELATIONSHIP'
},ignore_index=True)
# 实体去重
entity_df = entity_df.drop_duplicates(subset=':ID')
entity_df = entity_df[[':ID','name',':LABEL']]
entity_df.to_csv('{}/entity{}.csv'.format(base_path,index),index=None)
relationship_df.to_csv('{}/relationship{}.csv',format(base_path,index),index=None)
for index,d in enumerate(data):
save_data(index,d,'out')
if index == 4:
break(2)数据导入

启动Terminal,查询项目位置,再处理好后生成的csv文件复制到项目目录的import文件中,如: D:\neo4j-community-4.3.6\data\relate-data\dbmss\dbms-cd27d62c-2fe1-4a94-8768-1ccf36006049\import
构建结点,neo4j中执行该语句,{}中写出结点各个属性
![]()
构建关系
![]()
注意!!!csv数据打开方式用记事本打开,另存编码改为utf-8,否则报错!!!
如果能解决您的问题,记得收藏+关注呀!!!
创作时间:2022.2.2
文章编号YU.NO.1