Kaggle入门题目: 基于神经网络的Titanic disaster存活预测
Excel原始数据处理
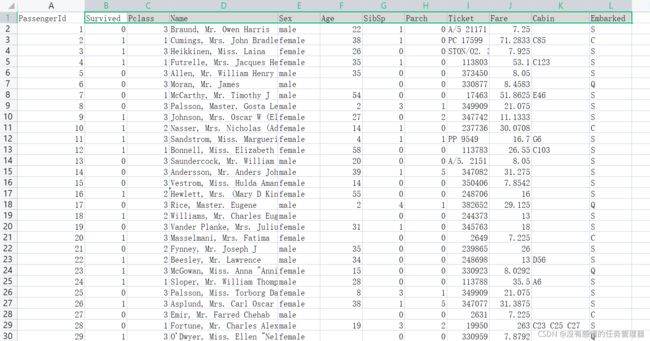
训练集原始数据(部分)
数据处理方法
(1)舍弃部分数据:无明显规律(Name),格式不统一(Ticket),大量缺失的数据(Cabin);
(2)Sex:male编码1,female编码0;
(3)Embarked :S编码1,C编码3,Q编码2;
(4)少量缺失的数据以平均值填补(Age,平均值26.273);
(5)测试集进行相同的处理。
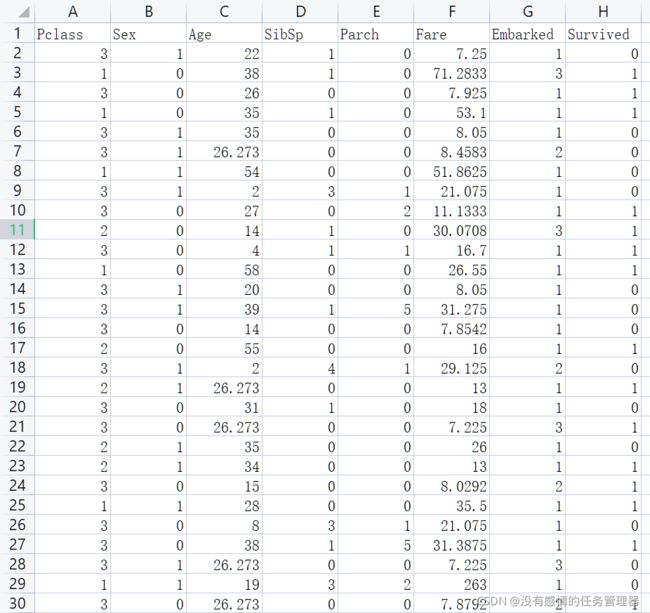
处理后的数据
神经网络搭建及代码
在完成数据的基本处理后开始模型搭建
第一次尝试搭建神经网络,一共8层,最终提交准确率在70%左右,电脑硬件较好可以增加迭代次数继续降低损失函数。
import torch
import numpy
import matplotlib.pyplot as plt
#从文件读取数据
xy=numpy.loadtxt('D:\Titanic\\train_processed.csv',delimiter=',',dtype=numpy.float32)
xz=numpy.loadtxt('D:\Titanic\\test_processed.csv',delimiter=',',dtype=numpy.float32)
x_data=torch.from_numpy(xy[:,:-1])
y_data=torch.from_numpy(xy[:,[-1]])
test_data=torch.from_numpy(xz[:,:])
#检查维度
print(test_data.shape)
print(x_data.shape,y_data.shape)
loss_list=[]
#创建模型
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1=torch.nn.Linear(7,15)
self.linear2=torch.nn.Linear(15,30)
self.linear3=torch.nn.Linear(30,100)
self.linear4=torch.nn.Linear(100,70)
self.linear5=torch.nn.Linear(70,20)
self.linear6=torch.nn.Linear(20,10)
self.linear7=torch.nn.Linear(10,1)
self.relu=torch.nn.ReLU()
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.relu(self.linear1(x))
x=self.relu(self.linear2(x))
x=self.relu(self.linear3(x))
x=self.relu(self.linear4(x))
x=self.relu(self.linear5(x))
x=self.relu(self.linear6(x))
x=self.sigmoid(self.linear7(x))
return x
#损失函数和优化器
model=LogisticRegressionModel()
criterion=torch.nn.BCELoss(reduction='sum')
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.999) #学习率衰减
#使用GPU运算
#device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#x_data,y_data=x_data.to(device),y_data.to(device)
for epoch in range(5000):
y_pre=model(x_data)
loss=criterion(y_pre,y_data)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step() #学习率衰减
epoch_list=numpy.arange(5000)
y_pred=model(test_data)
y_pred_label=torch.where(y_pred>=0.5,torch.tensor([1]),torch.tensor([0]))
#结果文件输出
y_end=y_pred_label.numpy()
numpy.savetxt('D:\Titanic\\predict.csv',y_end,delimiter=',')
#可视化训练过程
plt.plot(epoch_list,loss_list,label='loss',color='blue')
plt.show()
损失函数的下降情况:

在Kaggle平台的提交结果
![]()
模型改进
在使用mini-batch进行小批量梯度下降和学习率指数衰减后可以进一步优化,准确率在74%左右,但由于电脑性能原因只迭代了1500次,尚有进步空间,代码改进如下:
import torch
import numpy
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
loss_list=[]#记录损失函数
#构建数据集类
class TitanicDataset(Dataset):
def __init__(self):
super(TitanicDataset, self).__init__()
xy = numpy.loadtxt('D:\Titanic\\train_processed.csv', delimiter=',', dtype=numpy.float32)
xz = numpy.loadtxt('D:\Titanic\\test_processed.csv', delimiter=',', dtype=numpy.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
self.test_data=torch.from_numpy(xz[:,:])
def __getitem__(self, item):
return self.x_data[item],self.y_data[item]
def __len__(self):
return self.len
#创建模型
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1=torch.nn.Linear(7,15)
self.linear2=torch.nn.Linear(15,30)
self.linear3=torch.nn.Linear(30,100)
self.linear4=torch.nn.Linear(100,70)
self.linear5=torch.nn.Linear(70,20)
self.linear6=torch.nn.Linear(20,10)
self.linear7=torch.nn.Linear(10,1)
self.relu=torch.nn.ReLU()
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.relu(self.linear1(x))
x=self.relu(self.linear2(x))
x=self.relu(self.linear3(x))
x=self.relu(self.linear4(x))
x=self.relu(self.linear5(x))
x=self.relu(self.linear6(x))
x=self.sigmoid(self.linear7(x))
return x
data_set=TitanicDataset()
train_loader=DataLoader(dataset=data_set,batch_size=30,shuffle=True)
#损失函数和优化器
model=LogisticRegressionModel()
criterion=torch.nn.BCELoss(reduction='sum')
optimizer=torch.optim.Adam(model.parameters(),lr=0.005)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9999) #学习率衰减
#使用GPU运算
#device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#x_data,y_data=x_data.to(device),y_data.to(device)
def train():
for epoch in range(1500):
for i,data in enumerate(train_loader,0):
input,label=data
y_pre=model(input)
loss=criterion(y_pre,label)
if(i==20):
loss_list.append(loss.item())
if(loss<0.2):
return
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step() #学习率衰减
train()
epoch_list=numpy.arange(len(loss_list))
y_pred=model(data_set.test_data)
y_pred_label=torch.where(y_pred>=0.5,torch.tensor([1]),torch.tensor([0]))
#结果文件输出
y_end=y_pred_label.numpy()
numpy.savetxt('D:\Titanic\\predict.csv',y_end,delimiter=',')
#可视化训练过程
plt.plot(epoch_list,loss_list,label='loss',color='blue')
plt.show()
损失函数
损失函数如下,每个batch内周期性起伏,整体呈下降趋势

平台提交结果
提交结果:

本文章作为记录,希望进一步学习后可以搭建效果更好的网络。