播放器实战22 解决花屏与卡顿问题
1.内存对齐
1.1什么是内存对齐
在C语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。在结构中,编译器为结构的每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
为了使CPU能够对变量进行快速的访问,变量的起始地址应该具有某些特性,即所谓的”对齐”. 比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除.
举个例子,理论上,32位系统下,int占4byte,char占一个byte,那么将它们放到一个结构体中应该占4+1=5byte;但是实际上,通过运行程序得到的结果是8 byte,这就是内存对齐所导致的。
#include1.2为什么要内存对齐
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的.它一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度.
现在考虑4字节存取粒度的处理器取int类型变量(32位系统),该处理器只能从地址为4的倍数的内存开始读取数据。
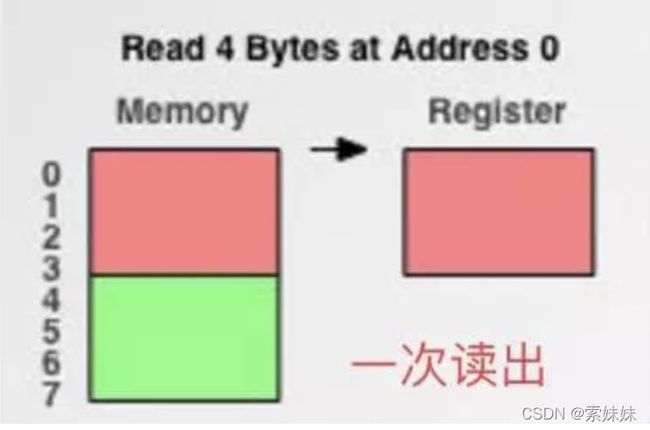
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器.这需要做很多工作.

现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存(存取粒度的整数倍)。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率,是通过是空间来节省时间的例子。
若降低存取粒度,看上去不需要做内存对齐了,但读取速度大大减慢反而得不尝试,因此通过内存对齐技术使得存取粒度尽量大进而加快读取速度;其次对于嵌入式设备来说,可以通过使用内存对齐来充分利用其宝贵的内存资源。
参考:https://zhuanlan.zhihu.com/p/30007037
2.YUV与linesize
引入stride
stride:指在内存中每行像素所占的空间。为了实现内存对齐每行像素在内存中所占的空间并不一定是像素的宽度,可能要在每行末尾加一些字节的数据来做内存对齐
查看ffmpeg结构体AVFrame中的三个成员:
01.uint8_t *data[AV_NUM_DATA_POINTERS];
data存储原始的音视频数据(视频为YUV,音频为PCM)。有两种存储音视频的方式,plannar方式和packet方式
plannar方式:通道n的数据分别存储在data[n]中;拿YUV视频来说,就是data[0],data[1],data[2]分别存储Y,U,V的数据。拿双声道的音频来说,就是data[0],data[1]分别存储左声道,右声道数据;对于音频,声道数有可能大于AV_NUM_DATA_POINTERS,那么多出来的将存储在extended_data字段中
packet方式:所有数据都存储在data[0]中(RGB)
02.int linesize[AV_NUM_DATA_POINTERS];
表示每一行数据的大小;对于plannar(内存对齐1)格式和packet(内存对齐后通道数)格式,这里的取值也不一样
03.uint8_t **extended_data;
存放data存放不下的数据
比如分辨率638480的RGB24图像,我们在内存处理的时候如果要以16字节对齐,则6383/16=119.625不能整除,因此不能16字节对齐,我们需要在每行尾部填充6个字节,就是640*3/16=120.此时该图片的stride为1920字节,如下图所示:

什么是YUV
YUV是编译true-color颜色空间(color space)的种类,Y’UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。“Y”表示明亮度(Luminance或Luma),也就是灰阶值,“U”和“V”表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。 [1]
planar 平面格式
指先连续存储所有像素点的 Y 分量,然后存储 U 分量,最后是 V 分量。
packed 打包模式
指每个像素点的 Y、U、V 分量是连续交替存储的。
视频编码为什么要采用YUV格式数据?
之所以采用YUV,是因为它的亮度信号Y和色度信号U、V是分离的。如果只有Y信号分量而没有U、V分量,那么这样表示的图像就是黑白灰度图像。彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的兼容问题,使黑白电视机也能接收彩色电视信号。与RGB视频信号传输相比,YUV最大的优点在于只需要占用极少的频宽(RGB要求三个独立的视频信号同时传输)。其中“Y”表示明亮度(Luminance或Luma),也称灰阶值;“U”和“V”表示的则是色度(Chrominance或Chroma),它们的作用是描述影像的色彩及饱和度,用于指定像素的颜色。因此如果只有Y数据,那么表示的图像就是黑白的。在编码时使用YUV格式能极大去除冗余信息,因为人眼对亮点信息的敏感度远高于色度敏感度,如果压缩UV数据,人眼对其感知较弱,所以压缩算法的第一步,往往先把RGB数据转换成YUV数据,对Y压缩一点,对UV多压缩一点,以平衡图像效果和压缩率。
比如一个RGB格式的像素点R,G,B各为1比特,一共3比特,而使用YUV,(比如YUV422),每两个像素点共用1个U与V,一共2比特,节省了三分之一的存储空间
链接:https://www.zhihu.com/question/538985600/answer/2540194144
ffmpeg编码或者解码为什么非要yuv而不是rgb
h264的帧格式就是YUV, YUV的优点是可以对其中两个分量CbCr进行采样而不太破坏图像的显示, rgb就不行会导致图像严重失真, 所以设计h264的编码器的时候就考虑用YUV做帧格式。
如果你非要rgb,那么用sws_scale转换为RGB.
H.264算法,算法要对每个亮度块和色度块进行计算,并根据相邻块查找相关性.
https://www.csdn.net/tags/NtTacg3sMTUxOTgtYmxvZwO0O0OO0O0O.html
h264的帧格式就是YUV, YUV的优点是可以对其中两个分量CbCr进行采样而不太破坏图像的显示, rgb就不行会导致图像严重失真, 所以设计h264的编码器的时候就考虑用YUV做帧格式。
如果你非要rgb,那么用sws_scale转换为RGB.
H.264算法,算法要对每个亮度块和色度块进行计算,并根据相邻块查找相关性.
指每个像素点的 Y、U、V 分量是连续交替存储的。
YUV 4:4:4采样,每一个Y对应一组UV分量,一个YUV占8+8+8 = 24bits 3个字节。
YUV 4:2:2采样,每两个Y共用一组UV分量,一个YUV占8+4+4 = 16bits 2个字节。
YUV 4:2:0采样,每四个Y共用一组UV分量,一个YUV占8+2+2 = 12bits 1.5个字节。
 在存储时按照plannar格式存储,先存Y,再存U,最后存V在显示时,亮度的紫框(Y0,Y1,Y4,Y5)与色度的紫框(U0,V0)组合,Y:U:V=4:1:1
在存储时按照plannar格式存储,先存Y,再存U,最后存V在显示时,亮度的紫框(Y0,Y1,Y4,Y5)与色度的紫框(U0,V0)组合,Y:U:V=4:1:1
4:2:0采样有YUV420P和YUV420SP两种格式
yuv420的两种格式:I420,NV12
YUV420P(YU12和YV12)格式
YUV420P又叫plane平面模式,Y , U , V分别在不同平面,也就是有三个平面,它是YUV标准格式4:2:0,主要分为:YU12和YV12
YU12:

YV12

YUV420SP格式的图像阵列,首先是所有Y值,然后是UV或者VU交替存储,NV12和NV21属于YUV420SP格式,是一种two-plane模式,即Y和UV分为两个plane,但是UV(CbCr)为交错存储,而不是分为三个平面。
NV21
android手机从摄像头采集的预览数据一般都是NV21,存储顺序是先存Y,再VU交替存储,NV21存储顺序是先存Y值,再VU交替存储:YYYYVUVUVU,以 4 X 4 图片为例子,占用内存为 4 X 4 X 3 / 2 = 24 个字节

NV12
也属于YUV420SP格式,NV12存储顺序是先存Y值,再UV交替存储:YYYYUVUVUV,以 4 X 4 图片为例子,占用内存为 4 X 4 X 3 / 2 = 24 个字节

当轮廓不变,颜色显示错位,可能就是UV排序错位了(采用了NV12)

来源:https://www.bilibili.com/video/BV1kL4y1G74m?from=search&seid=2376940568801521762&spm_id_from=333.337.0.0


3.花屏与解决
播放一个.MP4文件出现如下画面:

通过断点可以查看AVFrame中的linesize:

由于采用的是yuv420p plannar格式,linesize[0]=1024存放的是Y,应该和width相等,但可以看到width为1000

因为为了字节对齐,假设为32字节对齐(它是根据cpu来对齐的,可能是16或32的整数倍,不同的cpu有不同的对齐方式),1000/32=31.25,因此每行补充了24个字节的无效数据补充到1024,1024/32=32,frame中的data[0]数据存放是这样的:解码器将码流解码出来后的数据保存在内存中时每存1000个真正的像素数据就补24个为了字节对齐的无效数据,此时通过以下方法进行拷贝时:
memcpy(datas[0], frame->data[0], width * height);
memcpy(datas[1], frame->data[1], width * height / 4);
memcpy(datas[2], frame->data[2], width * height / 4);
将frame中的data[0]前1000个字节的数据传给显卡来显示第一行数据时没有问题,给显卡传第二行用来显示的数据时会从第1001个字节开始,此时会将24个无效字节当做第二行数据的起点,然后拼接上第二行的前976字节的数据,往后的行将会导致连锁反应的错乱,从而导致花屏
解决措施如下:
for (int i = 0; i < height; i++)//Y
memcpy(datas[0] + width * i, frame->data[0] + frame->linesize[0]* i, width);
for (int i = 0; i < height / 2; i++)//U
memcpy(datas[1] + width / 2 * i, frame->data[1] + frame->linesize[1] * i, width);
for (int i = 0; i < height / 2; i++)//V
memcpy(datas[2] + width / 2 * i, frame->data[2] + frame->linesize[2] * i, width);
以Y为例,因为Y的数据在一行中,每次在frame中读linesize的大小,每次只取linesize大小中width放在data中,循环height次,即可解决花屏:

虽然显示没问题了,但是在运行时仍然会有bug:

因为材质的内存空间在分配时:
datas[0] = new unsigned char[width * height]; //Y
datas[1] = new unsigned char[width * height / 4]; //U
datas[2] = new unsigned char[width * height / 4]; //V
data[1]与data[2]的空间大小为堆上new出来的wh/4空间
但是在上面从frame中赋值时,datas[1]/datas[2]共赋了wh/4+(linsize-width)*height/2,对于该媒体文件linsize>width,因此会导致有大量的数据被放在了未被定义的空间,也就是内存越界,具体的说是会导致堆上写内存越界,堆上开辟的内存空间的首尾空间是用来该堆的空间的,因此最后多出来的width/2个数据将会给写到这个存放内存管理的代码上,当要清理这块内存调用delete时,由于delete属于对堆上内存的管理代码,因此delete的调用可能会出现问题,

而堆中正确的代码应该如下:
内存越界一定会导致程序崩溃吗?详解内存越界
for (int i = 0; i < height; i++)//Y
memcpy(datas[0] + width * i, frame->data[0] + frame->linesize[0]* i, width);
for (int i = 0; i < height / 2; i++)//U
memcpy(datas[1] + width / 2 * i, frame->data[1] + frame->linesize[1] * i, width);
for (int i = 0; i < height / 2; i++)//V
memcpy(datas[2] + width / 2 * i, frame->data[2] + frame->linesize[2] * i, width);
小插曲:不小心写错了frame->data[]的下标:
for (int i = 0; i < height; i++)//Y
memcpy(datas[0] + width * i, frame->data[0] + frame->linesize[0]* i, width);
for (int i = 0; i < height / 2; i++)//U
memcpy(datas[1] + width / 2 * i, frame->data[0] + frame->linesize[1] * i, width);
for (int i = 0; i < height / 2; i++)//V
memcpy(datas[2] + width / 2 * i, frame->data[0] + frame->linesize[2] * i, width);
可以看到,能看到一些形状,但还是有花屏幕,并且颜色偏绿:

有待具体分析ing
4.解决卡顿问题
在Qt 5的GUI程序中,主线程也叫GUI线程,因为它是唯一被允许执行GUI相关操作的线程。对于一些计算量比较大的非常耗时的操作,如果放在主线程中,就是出现界面无法响应的问题。这种问题的解决一种方式是,把这些耗时操作放到次线程中,还有一种比较简单的方法:在处理耗时操作中加入一个延时,并调用QCoreApplication::processEvents()。这个函数告诉Qt去处理那些还没有被处理的各类核心事件,然后再把控制权返还给调用者。QElapsedTimer的成员函数elapsed()函数会返回自上次启动QElapsedTimer以来的毫秒数。如下代码就是加入一个25毫秒的延时去处理核心事件。
QT中线程qthread运行导致卡顿解决办法:
要把无限循环的函数放到run函数里面,同时 msleep 几毫秒。
在解封装的run中的无限循环每次循环完解锁之后msleep几(3)毫秒(在视频线程run的无限循环中也可以同样操作,但效果没有在解封装中做好)
void xdemuxthread::run()
{
while (!isexit)
{
mux.lock();
if (!demux)
{
mux.unlock();//若demux未打开则解锁让其他线程进来,等待5毫秒盼望demux能打开,然后再进行下次判断,判断demux是否打开
msleep(5);
continue;
}
if (vt && at)
{
vt->synpts = at->pts;
}
AVPacket* pkt = demux->readfz();
if (!pkt)
{
//读到结尾了
mux.unlock();
msleep(5);
continue;
}
if (demux->isvideo(pkt))
{
if (vt)vt->push(pkt);
}
else
{
if (at)at->push(pkt);
}
mux.unlock();
msleep(3);
}
}
即可解决问题
推测原因:
解封装线程需要获取mux,解码线程也需要这个mux,当解封装线程先获得这把锁后每次while循环完了由于CPU很难刚好调度到解码线程,于是解封装线程又立马获得了这把锁,导致解码线程很难获得这把锁,导致解码出的frame很少,于是会播放卡顿。
补充:为什么这两个线程要同一把锁?
比如当重新打开一个多媒体文件时,会调用视频音频线程的open(),open中第一步就是对缓冲队列进行清理,若不是同一把锁,解封装线程可能在清理的途中又把上一个多媒体文件中解封装出来的packet压进缓冲队列,这些packet有可能不会被清理掉,在播放新多媒体文件时就会出现问题。