论文笔记:Cross-Lingual Ability of Multilingual BERT: An Empirical Study
多语种BERT跨语言能力的实证研究
- 摘要
- 介绍
- 2 BACKGROUND
-
- 2.1 BERT
- 2.2 MULTILINGUAL BERT
- 3 WHY MULTILINGUAL BERT WORKS(m-bert工作的原因)
-
- 3.1数据集和实验设置
-
- 3.1.1 跨语言自然语言推理(XNLI)
- 3.1.2 跨语言命名实体识别(NER)
- 3.1.3 符号和实验设置
- 3.2 语言特性
-
- 3.2.1 WORD-PIECE OVERLAP(词块重叠)
- 3.2.2 WORD-ORDERING SIMILARITY(词序相似性)
- 3.2.3 WORD-FREQUENCY SIMILARITY(词频相似性)
- 3.2.4 STRUCTURAL SIMILARITY(结构相似性)
- 3.3 模型架构
-
- 3.3.1 深度
- 3.3.2 多头注意力
- 3.3.3 TOTAL NUMBER OF PARAMETERS(参数总数)
- 3.3.4 GENERALIZATION TO BERT WITH MORE LANGUAGES(泛化到更多语言的 BERT)
- 3.4 INPUT AND LEARNING OBJECTIVE(输入和学习目标)
-
- 3.4.1 NEXT SENTENCE PREDICTION (NSP)(下一句预测,这个应该属于学习目标)
- 3.4.2 LANGUAGE IDENTITY MARKER (语言识别标记,这个属于输入 )
- 3.4.3 CHARACTER VS. WORD-PIECE VS. WORD(这个属于输入)
- 4 讨论和未来工作
摘要
最近的研究展示了多语言BERT(M-BERT)令人惊讶的跨语言能力-令人惊讶的是,它的训练没有任何跨语言目标,也没有对齐的数据。在这项工作中,我们对M-BERT中不同成分对其跨语言能力的贡献进行了全面的研究。我们研究了语言的语言属性、模型的体系结构和学习目标的影响。这项实验研究是在三种不同类型的语言-西班牙语、印地语和俄语-的背景下进行的,并使用了两种概念上不同的自然语言处理任务:文本蕴涵和命名实体识别。我们的主要结论之一是,语言之间的词汇重叠在跨语言成功中扮演着微不足道的角色,而网络的深度是其中不可或缺的一部分。我们的所有模型和实现都可以在我们的项目页面上找到。
介绍
近年来,通过无监督学习嵌入自然语言文本,再加上足够的监督训练数据,在 NLP 中无处不在,并在广泛的单语 NLP 任务中取得了成功,主要是英语。其他语言的训练模型已被证明更加困难,最近的方法依赖于双语嵌入,允许将高资源语言(如英语)的监督转移到低资源语言的模型;然而,诱导这些双语嵌入需要一定程度的监督(Upadhyay 等,2016)。
多语言Bert(M-Bert)是一种基于Transformer(Vaswani等人,2017)的语言模型,对104种语言的原始维基百科文本进行了培训,提出了一种完全不同的方法。模型不仅与上下文相关,而且它的培训也不需要监督–语言之间没有对齐。然而,尽管没有明确的跨语言目标,M-Bert产生的表征似乎能够很好地跨语言概括各种下游任务(Wu&Dredze,2019)。通过只涉及两种语言,我们可以研究特定目标语言的表现,确保它只受交叉语言的影响。
我们从三个方面分析了M-BERT的双语版本:(I)目标语言和源语言的语言特性和相似性;(Ii)网络结构;(Iii)输入和学习目标。
作为一种解释M-BERT成功的方法,有一个假设被讨论过,它与某种程度的语言相似性有关。这可以是词汇相似(共享单词或单词部分)或结构相似(词序或词频),或者两者兼而有之。因此,我们首先调查词块重叠的贡献–相同的词块在源语和目标语中出现的程度–并将其与其他相似性区分开来,我们将其归类为源语言和目标语之间的结构相似性。令人惊讶的是,正如我们所展示的,B-BERT是跨语言的,即使在绝对没有单词-片段重叠的情况下也是如此。也就是说,语言相似性的其他方面必须有助于该模型的跨语言能力。这与Pires等人的观点相反。(2019)假设M-BERT从共享的词块中获得权力。此外,我们还表明,B-BERT训练数据中的词块重叠量对性能改进几乎没有贡献。
们对模型体系结构的研究解决了(I)网络深度、(Ii)注意头的数量和(Iii)B-BERT中模型参数的总数的重要性。我们的结果表明,深度和参数总数对B-BERT的单语和跨语成绩都是至关重要的,而多头注意并不是一个显著的因素。一个单独的注意力头部B-BERT已经可以产生令人满意的结果。
为了理解学习目标和输入表示的作用,我们研究了 (i) 下一句预测目标、(ii) 训练数据中的语言标识符和 (iii) 输入表示中的标记化水平的影响(字符、单词片段或单词标记化)。我们的结果表明,下一句预测目标实际上会损害模型的性能,而识别输入中的语言不会影响 B-BERT 跨语言的性能。我们的实验还表明,输入的字符级和单词级标记化导致性能明显低于单词级标记化。
总之,我们对英语-西班牙语、英语-俄语和英语-印地语这三种源语-目标语对进行了广泛的实验,这些语言对是根据不同的脚本和类型特征而选择的。我们评估了B-BERT在两个非常不同的下游任务上的性能:跨语言命名实体识别-一种只需要局部上下文的序列预测任务-以及跨语言文本蕴涵,需要更多的文本全局表示。
我们并不是第一次对M-Bert进行研究。Wu&Dredze(2019)和Pires等人。(2019)发现了该模式的跨语言成功,并试图理解它。前者通过分层考虑M-BERT,将跨语言性能与共享词块的数量联系起来;后者通过将模型在语言之间的迁移能力作为语言中词序相似度的函数来考虑。然而,这两部作品都将M-BERT视为一个黑匣子,比较不同语言的性能。另一方面,这项工作考察了B-BERT如何通过沿多个方面探索其组件来执行交叉语言。
我们还注意到,在其他情况下,如果不进行调查,一些架构结论已经在早期观察到。刘等人。 (2019)和杨等人。 (2019)认为BERT(单语模型)的下一句预测目标不是很有用;我们表明在跨语言环境中就是这种情况。沃伊塔等人。 (2019) 为基于 Transformer 的机器翻译模型修剪注意力头,并认为大多数注意力头并不重要;在这项工作中,我们表明注意力头的数量在跨语言环境中并不重要。
我们的贡献有三方面:(i)我们首次对 M-BERT 产生跨语言能力的各个方面进行了广泛的研究; (ii) 我们开发了一种方法,有助于分析语言之间的相似性及其对跨语言模型的影响;我们通过将英语映射到一种假英语语言来做到这一点,这种语言在所有方面都与英语相同,但与任何目标语言不共享单词片段;最后,(iii)我们开发了一组对 B-BERT 的见解,以及语言、架构和学习维度,这将有助于进一步理解和开发更先进的跨语言神经模型。
2 BACKGROUND
2.1 BERT
BERT (Devlin et al., 2019) 是一种基于 Transformer (Vaswani et al., 2017) 的预训练语言表示模型,已经得到广泛使用。与在给定上下文的情况下预测下一个单词的传统语言模型目标相比,BERT 学习预测掩码单词的值(所谓的掩码语言建模或 MLM(Taylor,1953 年)),并决定两个句子是否是连续的,称为下一句预测(NSP)。 BERT 的输入是一对句子 A 和 B,这样一半的时间 B 在原始文本中出现在 A 之后,其余时间 B 是随机采样的句子。输入中的一些标记被随机屏蔽,MLM 的目标是预测被屏蔽的标记。德夫林等人。 (2019) 认为 MLM 可以从两个方向进行深度表示,而 NSP 有助于理解两个句子之间的关系,并且有利于表示。
在对大量未标记文本进行 BERT 预训练后,这些表示可以用于下游任务。通常,在 BERT 的顶部添加一个新的特定于任务的层,并且所有参数都在目标任务上进行微调。
2.2 MULTILINGUAL BERT
除了使用前104种语言中的维基百科文本外,多语言BERT的预训练方式与单语BERT相同。为了解释维基百科大小的差异,一些语言进行了亚采样,一些语言使用指数平滑法进行了超采样(Devlin等人,2018年)。值得一提的是,没有专门设计的跨语言目标,也没有使用任何跨语言数据,例如平行语料库。
3 WHY MULTILINGUAL BERT WORKS(m-bert工作的原因)
我们从三个方面分析了多语言BERT(在我们的例子中是B-BERT)的跨语言能力:(I)目标语言和源语言的语言特性和相似性;(ii)网络架构,以及(iii)输入和学习目标
3.1数据集和实验设置
在这项工作中,我们对两个概念上不同的下游任务进行了所有实验——跨语言文本蕴涵(TE)和跨语言命名实体识别(NER)。 TE 在句子和句子对级别测量自然语言理解 (NLU),而 NER 在标记级别测量 NLU。我们使用跨语言自然语言推理 (XNLI) (Conneau et al., 2018) 数据集来评估跨语言 TE 性能和 LORELEI 数据集 (Strassel & Tracey, 2016) 用于跨语言 NER。
TE致力于在给定两段文本下,判断其中的一个文本段能否在语义上推导出另外一个文本段,从而帮助计算机理解文本间的语义包含关系.
命名实体识别(Named Entity Recognition,简称NER) , 是指识别文本中具有特定意义的词(实体),主要包括人名、地名、机构名、专有名词等等,并把我们需要识别的词在文本序列中标注出来。
3.1.1 跨语言自然语言推理(XNLI)
XNLI 是一个标准的跨语言文本蕴含数据集,它通过创建新的开发和测试集并手动翻译成 14 种不同的语言来扩展 MultiNLI(Williams 等人,2018)数据集。每个输入由一个前提和假设对组成,任务是将前提和假设之间的关系分类为三个标签之一:蕴涵、矛盾和中性。训练时,前提和假设都是英语,而在测试时,两者都是目标语言。 XNLI 对所有语言使用相同的前提和假设集,从而使跨语言比较成为可能。
3.1.2 跨语言命名实体识别(NER)
命名实体识别是将文本跨度识别和标记为命名实体的任务,例如人名和位置。我们使用的 NER 数据集 (Strassel & Tracey, 2016) 包含新闻和社交媒体文本,这些文本由母语人士按照相同的准则以多种语言(包括英语、印地语、西班牙语和俄语)标记。我们对 80%、10%、10% 的英语 NER 数据进行二次抽样作为训练、开发和测试。我们使用印地语、西班牙语和俄语的整个数据集进行测试。词汇量固定为 60000,并通过 SentencePiece 库 (Kudo, 2018) 中的一元语言模型估计。
3.1.3 符号和实验设置
我们将用 A 和 B 语言训练的 B-BERT 表示为 A-B,例如,用英语 (en) 和印地语 (hi) 训练的 B-BERT 表示为 en-hi,西班牙语 (es) 和俄语 (ru) 类似。对于预训练,我们将 en、es 和 ru Wikipedia 子采样到 1GB,并将整个 Wikipedia 用于印地语。除非另有说明,对于 B-BERT 训练,我们使用 32 的批大小、0.0001 的学习率和 2M 的训练步骤。对于 XNLI,我们使用与 BERT 在英语中使用的相同的微调方法并报告准确性。对于 NER,我们将 BERT 表示提取为特征并微调 Bi-LSTM CRF 模型(没有字符嵌入)并报告 5 次运行的平均 F1 分数及其标准差。
3.2 语言特性
皮雷斯等人。 (2019)假设 M-BERT 的跨语言能力是由于源语言和目标语言之间共享的单词片段而产生的。然而,我们的实验表明,即使没有词块重叠,B-BERT 也是跨语言的。同样,Wu & Dredze (2019) 假设应该选择源语言,使其与目标语言共享更多的词块,而我们的实验表明结构相似性(例如词序)更为重要。受上述假设的启发,在本节中,我们研究了词块重叠和结构相似性对 B-BERT 跨语言能力的贡献。
3.2.1 WORD-PIECE OVERLAP(词块重叠)
M-BERT是使用来自104种语言的维基百科文本进行训练的,来自不同语言的文本共享一些常见的词条词汇(如数字、链接等)。包括实际单词,如果它们有相同的字母),我们称之为单词-片段重叠。之前的工作(Pires等人,2019年)假设M-Bert跨语言泛化,因为这些共享的词片迫使其他词片映射到相同的共享空间。
在本节中,我们进行实验来比较有和没有词块重叠的跨语言性能。我们构建了一个新的语料库——假英语(enfake),通过将英语维基百科文本中每个字符的 Unicode 移动一个大常数,严格使得没有字符与任何其他维基百科文本重叠( Unicode 编码) 。我们可以将假英语视为与英语不同的语言,但除了词表形式外具有完全相同的属性。
在将文本输入到 BERT 的 Transformer 模型之前,还有一个额外的词汇嵌入步骤,以便将每个单词片段映射到某个整数(与其 unicode 无关)。因此,BERT 将无法访问 unicode 的确切值,也无法直接从我们介绍的 unicode 的线性移位中学习。
我们测量单词片段重叠的贡献,当单词片段重叠被去除时,表现下降。从表1中,我们可以看到B-BERT是跨语言的,即使没有单词重叠。我们还可以看到,词块重叠的贡献非常小,这相当令人惊讶,与之前的假设相矛盾(Pires et al .,2019;吴和德雷泽,2019)。
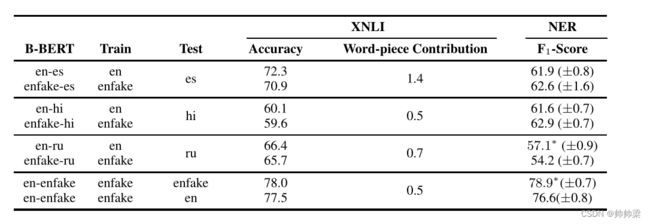
词片重叠和结构相似性的影响。对于不同的 B-BERT 语言对和两个任务(XNLI 和 NER),我们展示了单词片段对模型成功的贡献。在每两个连续的行中,我们显示一对(例如,英语-西班牙语)的结果,然后在将英语映射到一组不相交的单词片段后显示相应对的结果。每组两行中的性能差距表明由于完全消除了词片贡献而导致的损失。当结果在 0.05 水平上具有统计显着性时,我们在 NER 的数字上添加一个星号。
3.2.2 WORD-ORDERING SIMILARITY(词序相似性)
不同语言之间的单词顺序不同。例如,英语有主语-动词-宾语顺序,而印地语有主语-宾语-动词顺序。我们分析了单词排序方式的相似性是否会影响学习跨语言迁移性。我们通过在预训练期间随机排列句子中某些百分比的单词来破坏词序结构,从而研究词序相似性的影响。我们置换源语言(假英语)和目标语言(尽管置换其中任何一种也足够了)。这样,词序的相似性就对 B-BERT 隐藏了。我们通过对?L 2 ? 的 25%、50%、100% 进行采样来量化排列量。句子中的单词对与 L 个单词片段,并交换每一对(例如 wpi,…,wpj 变为 wpj,…,wpi)。这种洗牌方式绝不会在排列上产生均匀的随机分布,但提供了一种控制随机性的大致好方法。请注意,对于每个单词片段,出现在其上下文中的其他单词片段(句子中的其他单词片段)没有改变,尽管顺序发生了变化。我们也不会在微调期间进行置换,因为我们只想控制在预训练期间获得的跨语言能力。
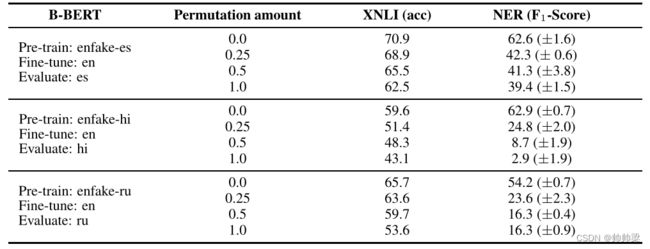
表 2:词序相似度的贡献:我们通过分析 XNLI 和 NER 在降低一定百分比的词序相似度时的性能来研究词序相似度的重要性。百分比 p 控制相似度(每个句子排列的随机程度)。我们可以看到,词序相似度是相当重要的,但是必须有其他结构相似性的组成部分可能有助于跨语言能力,因为几乎随机的性能仍然可以通过。
从表 2 可以看出,当我们减少两种语言之间的词序相似度时,性能显着下降。然而,跨语言性能仍然明显优于随机,这表明存在结构相似性的其他成分,这可能有助于 B-BERT 的跨语言能力。
3.2.3 WORD-FREQUENCY SIMILARITY(词频相似性)
我们还研究了是否只有知道单字词频才能获得良好的跨语言表征。事实上,齐普夫定律表明,单词出现的频率不同,人们可能会认为,在两种语言中,意义相似的单词以相对相似的频率出现,这有助于B-Bert进行跨语言学习。
我们收集目标语言中单词的频率,并基于频率对单词进行采样,生成新的单语语料库,即每个句子都是从原始单字频率采样的一组随机单词(从相同频率的词组中,抽取出来一个组成句子,但是这样会不会导致拼凑出来的不是一个合理的句子呢?)。B-Bert从这些语言中学到的唯一信息是它们的单字频率,也许还有子词级信息和句子长度的分布(2)。我们使用假英语和这个新生成的目标语料库来训练B-BERT。从表3可以看出,性能非常差。因此,单字频率本身并不能为跨语言学习提供足够的信息。
1、从相同频率的词组中,抽取出来一个组成句子,但是这样会不会导致拼凑出来的不是一个合理的句子呢?
2、为什么学到了单字频率,如是频率都一样的话,那么学到的应该是没有频率信息的啊,因为都一样。
3、这样拼装出来的句子,跟我之前的句子有啥太大差别吗,不就是换了一个句子吗?为什么性能直接跨了呢?
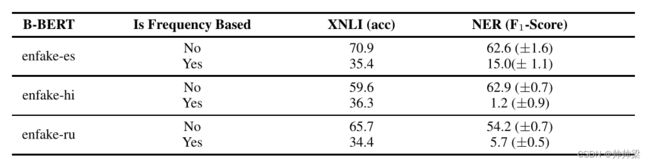
表3:单语言频率的跨语言能力:我们研究单语言频率是否有助于跨语言迁移。Enfake-es表示用假英语和新创建的语料库训练的B-BERT,其中每个句子都是从与ES相同的一元语法分布中抽样的一组随机单词。结果表明,仅有单字频率是不足以达到合理的跨语言表现的。
3.2.4 STRUCTURAL SIMILARITY(结构相似性)
我们将语言的结构定义为单个语言的每个属性,这些属性对于语言的字母是不变的(例如,形态、词序、词频都是语言结构的一部分)。从表 1 中,我们可以看到 BERT 从 Fake-English 到英语的转换非常好。另请注意,尽管不共享任何词汇,但假英语几乎可以像英语一样转换为西班牙语、印地语、俄语。在可以比较语言之间分数的 XNLI 上,从假英语到西班牙语的跨语言可迁移性比从假英语到印地语/俄语要好得多。由于它们不共享任何单词片段,因此这种更好的可转移性来自西班牙语和假英语之间的结构相似性更接近。
通过第3.2.2节我们知道,在两种语言之间,即使没有词块重叠,也没有句子中任何特定的单词顺序,B-BERT仍然可以学习一些跨语言特征。第3.2.3节从另一方面显示,如果B-BERT只获得很少的信息(单码频率),它几乎不会学习任何跨语言特征。 这些结果表明,我们应该更多地研究语言之间的结构相似性,这些结果表明我们应该更多地研究语言之间的结构相似性,例如,更高阶的 k-gram 或 k-共现频率(请注意,词序实验可以看作是给 B-BERT k-共现词频,其中 k 是语料库中最长句子的长度)。在这项研究中,我们不会进一步剖析语言的结构。尽管其定义不明确,但我们的实验清楚地表明,结构相似性对于跨语言迁移至关重要。
3.3 模型架构
从第 3.2 节中,我们观察到 B-BERT 有效地识别语言结构。在本节中,我们假设这种能力是模型架构的一个新兴属性。我们研究了 B-BERT 架构的不同组件的贡献,即 (i) 深度、(ii) 多头注意力和 (iii) 参数总数。其动机是了解哪些组件对其跨语言能力至关重要。
我们在 XNLI 数据集上执行所有跨语言实验,以假英语作为源语言,俄语作为目标语言;我们通过假英语和俄语的表现之间的差异来衡量跨语言能力(差异越小,跨语言能力越好)。
3.3.1 深度
我们假设 B-BERT 提取良好语义和结构特征的能力是其跨语言有效性的关键原因,而 B-BERT 的深度有助于它提取良好的语言特征。在本节中,我们研究了深度对 B-BERT 的单语和跨语言性能的影响。我们固定注意头的数量并改变隐藏单元和中间单元的大小,使得参数总数几乎相同(中间单元的大小始终是隐藏单元大小的 4 倍)。
从表 4 中,我们可以看到更深层次的模型不仅在英语上表现更好,而且在跨语言上也表现更好。我们还可以看到英语表现与跨语言能力(Δ)之间存在很强的相关性,这进一步支持了我们的假设,即提取良好语义和结构特征的能力是其跨语言有效性的关键原因。
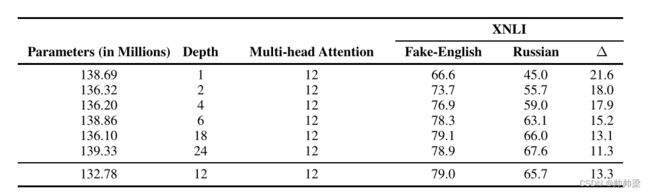
表 4:B-BERT 架构深度的影响:我们使用 Fake-English 和俄语 B-BERT,研究 B-BERT 深度对 XNLI 的影响。我们改变深度并固定注意力头的数量和参数的数量——隐藏单元和中间单元的大小发生了变化,使得参数的总数几乎保持不变。我们只训练假英语,测试假英语和俄语,并报告他们的测试准确性。 Fake-English 和 Russian (Δ) 的性能差异是我们衡量跨语言能力的指标(差异越小,跨语言能力越好)。
3.3.2 多头注意力
在本节中,我们研究了多头注意力对 B-BERT 跨语言能力的影响。我们固定了深度和参数总数——它是隐藏层和中间层的深度和大小的函数,并研究了不同数量的注意力头的性能。从表 5 可以看出,注意力头的数量对跨语言能力(Δ)没有显着影响。即使只有一个注意力头,B-BERT 也能令人满意地跨语言,这与最近关于单语 BERT 的研究一致(Voita 等人,2019;Clark 等人,2019)。
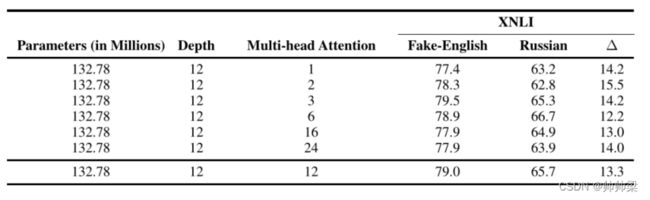
表 5:多头注意力的影响:我们研究了 B-BERT 的注意力头数对假英语和俄语在 XNLI 数据上的性能的影响。我们固定了 B-BERT 的深度数量和参数数量,并改变了注意力头的数量。假英语和俄语(Δ)的表现之间的差异是我们衡量跨语言能力的指标。
3.3.3 TOTAL NUMBER OF PARAMETERS(参数总数)
与深度类似,我们还预计大量参数可能有助于 B-BERT 提取良好的语义和结构特征。我们通过固定注意力头的数量和深度来研究参数总数对跨语言性能的影响;我们通过改变隐藏单元和中间单元的大小来改变参数的数量(中间单元的大小总是隐藏单元的 4 倍)。从表 6 可以看出,参数的总数不如深度显着;然而,低于阈值,参数的数量似乎很大,这表明 B-BERT 需要一定的最小参数数量来提取良好的语义和结构特征。
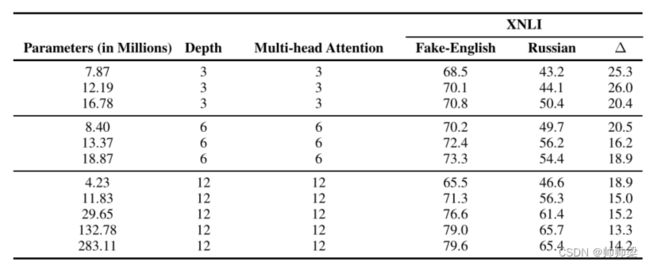
表 6:参数总数的影响:我们研究了 B-BERT 的参数总数对假英语和俄语在 XNLI 数据上的性能的影响。我们固定了 B-BERT 的深度数和注意力头数,并通过改变隐藏单元和中间单元的大小来改变参数的总数。假英语和俄语(Δ)的表现之间的差异是我们衡量跨语言能力的指标。
3.3.4 GENERALIZATION TO BERT WITH MORE LANGUAGES(泛化到更多语言的 BERT)
在这里,我们表明模型结构的结果也适用于更多语言的案例;为了进一步说明这一点,我们对四种语言 BERT(en、es、hi、ru)进行了实验。从表 7 中,我们可以看到即使只有 15% 的参数,当深度足够好时,只有 1 或 3 个注意力头,XNLI 的性能也是相当的,这与我们在正文中的观察结果一致。
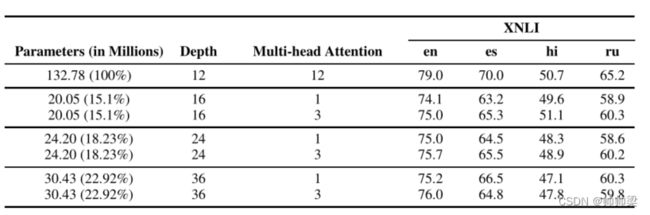
表 7:在四种语言的 M-BERT 上的类似结果:我们表明,从双语 BERT 得出的见解在多语言 BERT(4 语言 BERT)的情况下也是有效的。此外,我们还表明,如果有足够的深度,我们只需要较少数量的参数和注意力头即可获得可比较的结果。
3.4 INPUT AND LEARNING OBJECTIVE(输入和学习目标)
在本节中,我们研究了输入表示和学习目标对 B-BERT 跨语言能力的影响。回想一下,BERT 是使用掩码语言建模 (MLM) 和下一句预测 (NSP) 目标进行训练的。我们研究了 NSP 的影响,因为最近的工作(Conneau & Lample,2019;Joshi 等人,2019;Liu 等人,2019)表明 NSP 目标会损害几个单语任务的性能。为了验证 B-BERT 是否可以在与语言无关的环境中学习,我们还研究了语言身份标记的使用。我们也有兴趣研究标记化和语言表示的效果,使用字符和单词词汇而不是单词片段。
3.4.1 NEXT SENTENCE PREDICTION (NSP)(下一句预测,这个应该属于学习目标)
BERT 的输入是一对由特殊标记分隔的句子,这样第二个句子的一半时间是下一个句子,其余一半时间是一个随机句子。 BERT (B-BERT) 的 NSP 目标是预测原文中的第二个句子是否出现在第一个句子之后。我们通过比较有和没有这个目标的预训练 B-BERT 的性能来研究 NSP 目标的效果。从表 8 中,我们可以看到 NSP 目标对跨语言性能的影响甚至超过了单语性能。
(的确是,没有效果更好)
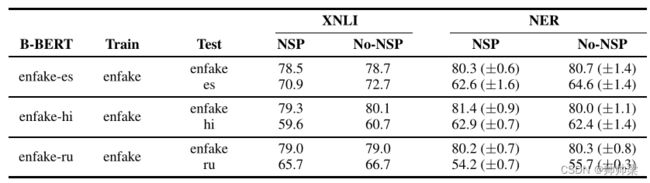
表8:下一句预测目标的影响:我们研究了NSP目标对XNLI和NER的影响。NSP和No NSP列分别显示了在有和无NSP目标的情况下训练B-BERT时的表现(XNLI的准确性和NER的平均(stdev)F1分数)。NSP和非NSP之间的差异表明,NSP目标会损害绩效。
3.4.2 LANGUAGE IDENTITY MARKER (语言识别标记,这个属于输入 )
在第 3.2 节中,我们认为 B-BERT 是跨语言的,因为它能够识别语言结构的相似性,因此我们假设添加语言标识标记不会影响其跨语言能力。即使我们不添加语言身份标记,BERT 也会学习语言身份(Wu & Dredze,2019)。为了在输入中加入语言标识,我们为不同的语言添加不同的字符串标记([SEP])结尾(即,我们的输入格式是 [CLS] SENT1 [SEP-A] SENT2 [SEP-B],其中 A 和 B是分别对应于 SENT1 和 SENT2 的语言)。从表 9 中,我们可以看到添加语言标识标记不会影响跨语言性能。

表 9:输入中语言标识标记的效果:我们研究了在输入数据中添加语言标识符的效果。我们为不同的语言使用不同的字符串结尾 ([SEP]) 标记作为语言身份标记。 “With Lang-id”和“No Lang-id”列显示了在输入中使用和不使用语言标识标记训练 B-BERT 时的性能。
3.4.3 CHARACTER VS. WORD-PIECE VS. WORD(这个属于输入)
感觉是词汇表的选择不通
我们将 B-BERT 的性能与字符、单词片段和单词标记化输入进行比较。对于字符 B-BERT,我们使用所有字符作为词汇表,对于单词 B-BERT,我们使用最频繁的 100000 个单词作为词汇表。从表 10 中我们可以看出,词片标记化的 B-BERT 的跨语言性能(源语言和目标语言性能之间的差异)与词标记化的相似,但都优于字符标记化。我们认为这是因为单词片段和单词比字符携带更多的信息,使 B-BERT 更容易学习两种语言之间的相似性。
(感觉需要看一下bert的源输入)
值得注意的是,模型是无法处理文本字符的,所以不管是英文还是中文,我们都需要通过预训练模型BERT自带的字典vocab.txt将每一个字或者单词转换成字典索引(即id)输入。
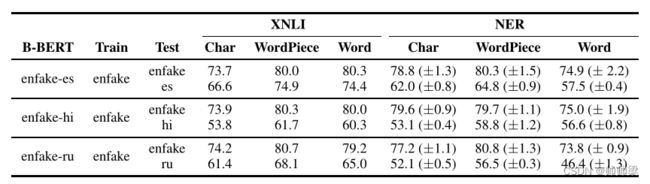
表 10:Character vs Word-Piece vs Word tokenization 的效果。我们在 XNLI 和 NER 数据上比较了 B-BERT 与不同标记化输入的性能。 Char、Word-Piece、Word 列分别报告了 B-BERT 在字符、词块和工作标记化输入的性能。我们使用 2k 批大小和 500k epoch
4 讨论和未来工作
本文对 B-BERT 的跨语言能力进行了系统的实证研究。分析涵盖三个维度: (i) 目标语言和源语言的语言特性和相似性; (ii) 网络架构,以及 (iii) 输入和学习目标。
为了衡量使 B-BERT 成功所需的语言相似性方面,我们创建了一种新语言——假英语——这使我们能够研究单词重叠的影响,同时保持源语言的所有其他属性。我们的实验揭示了一些有趣和令人惊讶的结果。最显著的发现是词片重叠和多头注意都不显著,而结构相似性和深度对B-BERT的跨语言能力至关重要。
虽然为了更好地控制语言之间的干扰,我们研究了 B-BERT 而不是 M-BERT 的跨语言能力,但现在扩展这项研究会很有趣,允许更多语言之间的交互。我们将其留给未来的工作来研究这些相互作用。特别是,一个重要的问题是了解添加与目标语言相关的 M-BERT 语言在多大程度上有助于模型的跨语言能力。
我们引入了结构相似性这个术语,尽管它的定义模糊不清,并展示了它在跨语言能力中的重要性。另一个有趣的未来工作可能是开发一个更好的定义,并因此进行更精细的实验,以更好地理解结构相似性并研究其各个组成部分。
最后,我们注意到表 11 中的一个有趣观察。当前提和假设使用不同的语言时,我们观察到 B-BERT 的蕴涵性能急剧下降。 (此数据是使用 XNLI 创建的,在原始形式中,语言包含相同的前提和假设对)。一种可能的解释可能是 BERT 正在学习通过将前提中的单词或短语与假设中的单词或短语匹配来做出文本蕴涵决定。这个问题也留作未来的方向。

表11:不同语言中的前提和假设:使用XNLI测试集,我们构建了不同语言中带有前提和假设的文本蕴涵数据。A-B栏(例如Enfake-Target)指的是A语言中的前提(Enfake)和B语言中的假设(Target)的测试数据。我们总是训练假英语,并报告测试的准确性。