关于天池赛中零基础入门推荐系统 - 新闻推荐Task02数据分析
文章目录
- 前言
- 一、关于数据分析
-
-
-
- 数据分析的目的:
- 数据分析的作用:
-
-
- 二、实现步骤
-
- 1.引入库
- 2.读取数据:
- 3.数据预处理:
- 4.数据浏览:
-
-
- 4.1用户点击日志文件_训练集
- 4.2测试集用户点击日志
- 4.3新闻文章信息数据表
- 4.4新闻文章embedding向量表示
-
- 5.数据分析:
-
-
- 5.1用户重复点击
- 5.2用户点击环境变化分析
- 5.3用户点击新闻数量的分布
- 5.4新闻点击次数分析
- 5.5两篇新闻连续出现的次数
-
- 总结
前言
经过上一篇依据Datawhale的针对天池赛中零基础入门推荐系统 - 新闻推荐Task01的文章,接下来本文将对此次赛题中的数据进行分析,希望能够加深对推荐算法的一些认知。
| 打卡记录NO.2
一、关于数据分析
数据分析的目的:
- 熟悉整个数据集的基本情况及其特征之间的相关性;
- 熟悉文件中包含的数据及文件中每个字段的含义;
数据分析的作用:
- 在推荐场景下,分析用户和文章的基本属性,以及用户和文章交互的一些分布,这些都有利于后面的召回策略的选择,以及特征工程;
- 当特征工程和模型调参已经很难继续提高分数时,可以试着从新的角度去分析这些数据。
二、实现步骤
1.引入库
代码如下:
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc('font', family='SimHei', size=13)
import os,gc,re,warnings,sys
warnings.filterwarnings("ignore")
2.读取数据:
其中,path为保存原数据的存储路径。
path = './data_raw/'
#####train
trn_click = pd.read_csv(path+'train_click_log.csv')
item_df = pd.read_csv(path+'articles.csv')
item_df = item_df.rename(columns={'article_id': 'click_article_id'}) #重命名,方便后续match
item_emb_df = pd.read_csv(path+'articles_emb.csv')
#####test
tst_click = pd.read_csv(path+'testA_click_log.csv')
3.数据预处理:
计算用户点击时间戳:
# 对每个用户的点击时间戳进行降序排序
trn_click['rank'] = trn_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
tst_click['rank'] = tst_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
计算用户点击次数:
#计算用户点击文章的次数,并添加新的一列count
trn_click['click_cnts'] = trn_click.groupby(['user_id'])['click_timestamp'].transform('count')
tst_click['click_cnts'] = tst_click.groupby(['user_id'])['click_timestamp'].transform('count')
4.数据浏览:
4.1用户点击日志文件_训练集
(1)将用户点击日志文件item_df与训练集文件trn_click通过主键“click_article_id"合并:
#合并文件
trn_click = trn_click.merge(item_df, how='left', on=['click_article_id'])
(2)查看合并之后的用户点击日志信息:
#查看用户点击日志信息
trn_click.info()

(3)查看合并之后的用户数量:
#查看训练数据集中的用户数量
trn_click.user_id.nunique()
unique():是数组形式返回所有唯一值,并按照从小到大排序
nunique() :即返回的是唯一值的个数
(4)查看合并之后每个用户最少点击文章数:
# 训练集里面用户至少点击的文章数
trn_click.groupby('user_id')['click_article_id'].count().min()
(5)画直方图大体看一下基本的属性分布:
plt.figure()
plt.figure(figsize=(15, 20))
i = 1
for col in ['click_article_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country',
'click_region', 'click_referrer_type', 'rank', 'click_cnts']:
plot_envs = plt.subplot(5, 2, i)
i += 1
v = trn_click[col].value_counts().reset_index()[:10]
fig = sns.barplot(x=v['index'], y=v[col])
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(col)
plt.tight_layout()
plt.show()

分析图像:
从点击时间click_article_id来看,排名前10的用户中,编号为’234698‘的用户点击文章数目最多,’124749‘用户点击文章数目最少,为最大的1/2。
从点击时间clik_timestamp来看,分布较为平均,可不做特殊处理。由于时间戳是13位的,后续将时间格式转换成10位方便计算。
从点击环境click_environment来看,仅有1922次(占0.1%)点击环境为1;仅有24617次(占2.3%)点击环境为2;剩余(占97.6%)点击环境为4。
从点击设备组click_deviceGroup来看,设备1占大部分(60.4%),设备3占36%。
从点击设备组click_os来看,操作系统17占大部分,操作系统2排名第二。
4.2测试集用户点击日志
(1)将用户点击日志文件item_df与测试集文件tst_click通过主键“click_article_id"合并:
#合并文件
tst_click = tst_click.merge(item_df, how='left', on=['click_article_id'])
(2)描述合并之后的测试集文件tst_click:
tst_click.describe()
将得出的结果与4.1的训练集进行比较,我们可以看出二者的用户是完全不一样的:
训练集的用户ID由0 ~ 199999,而测试集A的用户ID由200000 ~ 249999。
(3)查看合并之后的用户数量:
#测试集里面每个用户至少点击的文章数
tst_click.user_id.nunique()
(4)查看合并之后每个用户最少点击文章数:
# 注意测试集里面用户至少点击的文章数
tst_click.groupby('user_id')['click_article_id'].count().min()
4.3新闻文章信息数据表
#浏览新闻文章数据集前五条和后五条
item_df.head().append(item_df.tail())
#查看某一字数范围内的文章浏览数量
item_df['words_count'].value_counts()
4.4新闻文章embedding向量表示
#浏览新闻文章中前五条数据集的embedding向量
item_emb_df.head()
5.数据分析:
5.1用户重复点击
(1)将训练集文件trn_click与测试集文件tst_click合并:
#合并文件
user_click_merge = trn_click.append(tst_click)
(2)查看合并之后的用户重复点击文章的次数:
#用户重复点击
user_click_count = user_click_merge.groupby(['user_id', 'click_article_id'])['click_timestamp'].agg({'count'}).reset_index()
user_click_count[:10]
(3)查看重复点击文章的次数大于7的用户:
user_click_count[user_click_count['count']>7]
(4)查看用户点击新闻次数:
#用户点击新闻次数
user_click_count.loc[:,'count'].value_counts()

由图可知,有1605541(约占99.2%)的用户未重复阅读过文章,仅有极少数用户重复点击过某篇文章。 这个也可以单独制作成特征。
5.2用户点击环境变化分析
(1)随机采样10个用户来分析用户点击环境变化是否明显:
sample_user_ids = np.random.choice(tst_click['user_id'].unique(), size=10, replace=False)
sample_users = user_click_merge[user_click_merge['user_id'].isin(sample_user_ids)]
cols = ['click_environment','click_deviceGroup', 'click_os', 'click_country', 'click_region','click_referrer_type']
for _, user_df in sample_users.groupby('user_id'):
plot_envs(user_df, cols, 2, 3)
从得出的结果可以看出:绝大多数数的用户的点击环境是比较固定的。
因此:可以根据这些环境的统计特征来代表该用户本身的属性
5.3用户点击新闻数量的分布
(1)查看用户点击新闻数量的分布:
user_click_item_count = sorted(user_click_merge.groupby('user_id')['click_article_id'].count(), reverse=True)
plt.plot(user_click_item_count)
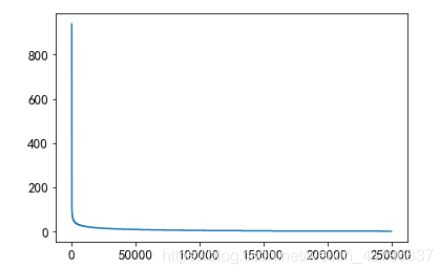
横坐标为用户编号,纵坐标为用户点击文章数目。由图可以看出,用户编号0点击文章数目是最多的,可以根据用户的点击文章次数看出用户的活跃度。
(2)查看点击次数在前50的用户
plt.plot(user_click_item_count[:50])
思路:
如果这50名用户的点击次数都在100次以上,则可以定义点击其为活跃用户。
(3)查看点击次数排名在[25000:50000]之间的用户数:
plt.plot(user_click_item_count[25000:50000])

由图可以看出,点击次数小于等于2次的用户非常多,可以把这些用户可以认为是非活跃用户。
5.4新闻点击次数分析
(1)查看新闻点击次数的分布:
item_click_count = sorted(user_click_merge.groupby('click_article_id')['user_id'].count(), reverse=True)
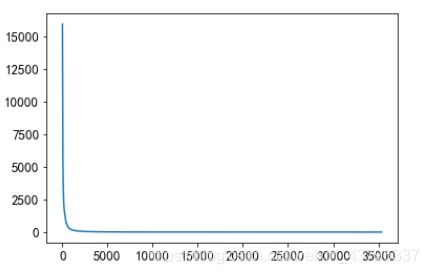
横坐标为文章编号,纵坐标为文章被点击数目。由图可以看出,文章编号0浏览次数是最多的。
(2)查看被点击次数在前20的文章
plt.plot(item_click_count[:20])
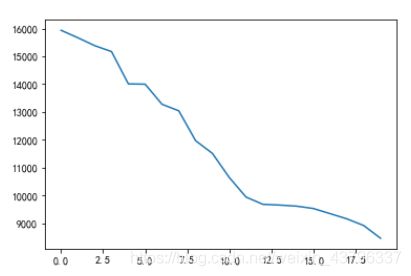
思路:
由图可以看出,点击次数最多的前20篇文章,点击次数均大于2500。
因此,可以定义这些新闻为热门新闻。
5.5两篇新闻连续出现的次数
tmp = user_click_merge.sort_values('click_timestamp')
tmp['next_item'] = tmp.groupby(['user_id'])['click_article_id'].transform(lambda x:x.shift(-1))
union_item = tmp.groupby(['click_article_id','next_item'])['click_timestamp'].agg({'count'}).reset_index().sort_values('count', ascending=False)
union_item[['count']].describe()

由上图数据可以看出,平均共现次数3.18,最高为2202。说明用户看的新闻,相关性是比较强的。
| 未完待续…
总结
通过此次文章中对数据分析的大致理解,目前可以得到以下几点重要的信息:
- 通过.nunique()的方法得到了训练集和测试集的user_id的数目,通过.count()的方法求解了用户至少点击的文章数目和文章至少被点击的数目。
- 通过统计分析的方法,得到用户点击文章的环境、用户点击文章时的操作系统及用户点击文章时所在的区域等对文章点击的影响。
- 根据统计结果可以发现,用户看的新闻之间的相关性是比较强的,所以往往我们判断用户是否对某篇文章感兴趣的时候, 在很大程度上会和他历史点击过的文章有关。