论文阅读04:使用序列标注的方式解决实体和关系的联合抽取
Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
1.摘要
实体和关系的联合抽取是信息抽取中的一个重要任务。为了解决这个问题,我们首先提出了一种新的标签方案(tagging scheme),将联合抽取任务转换为打标签(tagging)问题。然后,基于该标签方案,我们研究了不同的端到端模型来抽取实体及实体关系,而不是分开识别实体和关系。我们在一个公开数据集上进行了实验,该数据集是通过远程监督方法产生的。实验表明基于该标签方案的方法比现在大多数pipelined和联合学习(joint learning)方法效果更好。除此之外,论文中提出的端到端模型实现了公开数据集中的最优结果。
2.引言
实体和关系的联合抽取是为了侦测实体提及并同时从非结构化文本中识别它们的语义关系,如图1所示。与开放信息抽取从给定的语句中抽取关系词不同,在实体和关系的联合抽取任务中,关系词来自于预先定义的关系集合,通常不会出现于给定语句中。联合抽取是知识抽取和知识库自动构建的一个重要问题。实体识别的结果可能影响关系分类的性能并且导致误差传递。它们需要复杂的特征工程,而且严重依赖其它的NLP工具,这些工具也可能导致误差传播。为了减少特征抽取方面的人工工作,最近,(Mi-wa and Bansal, 2016) 展示了用于端到端实体和关系抽取的基于神经网络的方法。虽然联合模型可以在单个模型中使用共享参数表示实体和关系,它们也会分开抽取实体和关系,从而产生冗余信息。
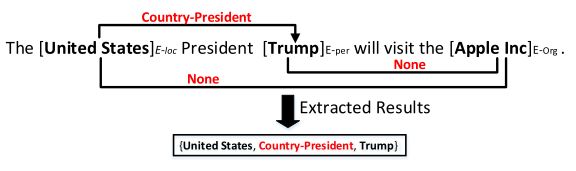
传统处理该任务的流水线方法通常先提取出实体,然后识别实体的关系。这个分离的框架让这个任务变得容易处理,每个步骤也更加灵活。但她忽略了两个子任务之间的相关性,并且每个子任务是独立的模型。
不同于pipelined的方法,联合学习框架是使用单个模型同时抽取实体和关系。它可以有效整合实体和关系的信息,并且已经证明能够取得更好的效果。然而,目前的大多数联合方法都是基于特征的结构化系统。它们需要复杂的特征工程,而且严重依赖其它的NLP工具,这些工具也可能导致误差传播。为了减少特征抽取方面的人工工作,最近,(Mi-wa and Bansal, 2016) 展示了用于端到端实体和关系抽取的基于神经网络的方法。虽然联合模型可以在单个模型中使用共享参数表示实体和关系,它们也会分开抽取实体和关系,从而产生冗余信息。
这篇论文关注三元组的抽取,三元组由两个实体和它们的关系组成。因此,我们可以直接对三元组进行建模,而不是分别抽取实体和关系。基于这个动机,我们提出了一个标签方案和一个端到端的模型来解决该问题。我们设计了一种新的标签,包含实体和关系的信息。基于该标签方案,实体和关系的联合抽取可以被转换为打标签问题。就这样,我们可以很容易使用神经网络来建模这个任务,而不需要复杂的特征工程。
最近,基于LSTM的端到端的模型已被应用于各种标注任务:命名实体识别、Chunking等。LSTM拥有学习长期依赖的能力,这有利于序列建模任务。因此,基于我们的标签方案,我们调查了不同的基于LSTM的端到端的模型来联合抽取实体和关系。我们也通过添加偏置(biased)损失来修改解码方法,从而使得模型适合我们设计的特殊标签。
我们提出的方法是一个有监督学习算法。然后,实际上,人工标注一个有大量实体和关系的训练集代价太贵且容易出错。因此,我们在一个由远程监督方法生成的公共数据集上进行实验以验证我们的方法。实验表明我们的方法在该任务上是有效的。除此之外,我们的端到端模型在这个公开数据集上能够取得最好的结果,可以增强相关实体之间的联系。
这篇论文的主要贡献是:
- (1)提出一个新的标签方案用于联合抽取实体和关系,可以轻易把抽取问题转换为标注任务。
- (2)基于该标签方案,可以学习不同的端到端模型来解决这个问题。基于该标签的方法优于目前大多数pipelined和联合学习方法。
- (3)而且,我们使用bias loss function开发了一个端到端模型以适应新的标签方案,该方法可以加强相关实体之间的联系。
3.方法
我们提出了一个新的标签方案和带有偏置目标函数(biased objective function)的端到端模型来联合抽取实体它们的关系。这一节:首先介绍怎么基于我们的打标签方法把抽取问题转为标注问题。然后阐述我们用于抽取结果的模型。
3.1 标签方案
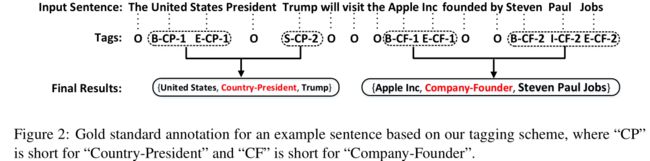
图2的例子展示了怎么打标签。每个词都有一个标签。标签"O"表示“Other“标签,表示与抽取结果不相关。除了”O“外,其它标签包含三个部分:实体中词位置,关系类型以及关系角色。使用BIES表示实体中词的位置信息。关系类型信息可以从一个预定义的关系集合中获取,关系角色信息使用数字"1"和”2“表示。抽取的结果使用三元组(Entity1,RelationType,Entity2)表示。"1"表示这个词属于实体1,”2“表示这个词属于实体2.因此,总的标签数量为 N = 2 ∗ 4 ∗ ∣ R ∣ + 1 N=2*4*|R|+1 N=2∗4∗∣R∣+1,|R|是预定义的关系集大小。
图2中输入语句包含2个三元组:{United States, Country-President,Trump} and {Apple Inc, Company-Founder,Steven Paul Jobs},其中,“Country-President"和"Company-Founder"是预定义的关系类型;“United”,“States”,“
Trump”,“Apple”,“Inc”,“Steven”,“Paul”and“Jobs” 是要抽取的实体。它们都使用我们的特殊标签进行标注。比如,单词"United"是实体“United States”的第一个词,与“Country-President”相关,所以它的标签是"B-CP-1”.另一个实体“ Trump”被标注为 “S-CP-2”。除此之外,那些与最终结果不相关的单词标注为"O"。
3.2 从标签序列到抽取的结果
根据图2中的标签序列,我们知道“ Trump” 和 “United States”共享同样的关系类型"Country-President",“Apple Inc” 和“Steven Paul Jobs” 共享同样的关系类型“Company-Founder”。我们把具有相同关系类型的实体放到一个三元组以获取最终结果。因此,“ Trump” 和 “United States”被放到同一个三元组,他们的关系类型是“Country-President”,在这个关系中,“ Trump”是"2",United States”是"1",所以最终的结果是 {United States, Country-President, Trump}。同样,另一个结果是{AppleInc, Company-Founder, Steven Paul Jobs}.
此外,如果一个语句包含两个或者更多拥有同样关系类型的三元组,我们使用最近邻原则把每两个实体组合进三元组。比如,图2中关系类型“Country-President”是“Company-Founder”,那么图中四个实体将有用相同的关系类型。“U-
nited States”与实体“ Trump”更近,“Apple Inc” 与“Jobs”更近,所以最终的结果是{United States, Company-Founder,Trump} 和{Apple Inc, Company-Founder,
Steven Paul Jobs}.
在这篇论文中,近考虑一个实体只属于一个三元组的情况,不考虑关系重叠的情况。
3.3 端到端的模型
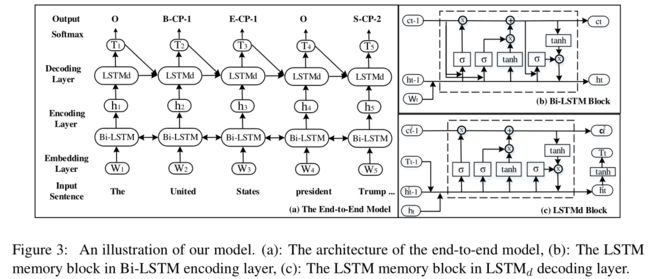
最近几年,基于神经网络的端到端的模型被广泛运用到序列标注任务上。这篇论文调查了一个端到端的模型来进行序列标注,如图2所示。它包含用于编码输入序列的BiLSTM层、使用biased loss的用于解码的LSTM层。biased loss可以加强实体标签的关系。
-
BiLSTM编码层
在序列标注问题上,BiLSTM编码层已经被证明能够有效捕获每个词的语义信息。BilSTM包括前向LSTM层、后向LSTM层和合并层。Embedding层把one hot表示转换成Embedding向量。因此,一个单词序列可以被表示为 W = { w 1 , … , w t , w t + 1 , w n } W=\{w_1,\dots,w_t,w_{t+1},w_n\} W={w1,…,wt,wt+1,wn},其中 w t ∈ R d w_t \in R^d wt∈Rd是d维词向量,是输入序列中的第t个单词, n n n是给定序列的长度。EMbedding层后是两个并行的LSTM层:前向LSTM层和后向LSTM层。LSTM架构由一系列记忆模块组成,每个时间步是一个LSTM记忆模块。BilSTM编码层中的记忆模块用于计算当前的隐藏向量 h t h_t ht,基于前一个隐藏向量 h t − 1 h_{t-1} ht−1,前一个cell 向量 c t − 1 c_{t-1} ct−1和当前的输入 w t w_t wt。结构图如图3(b),具体的计算细节如下:
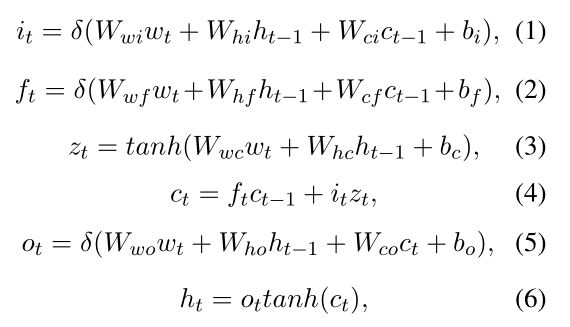
其中, i , f i,f i,f和 o o o是输入门,遗忘门和输出门, b b b是偏置项, c c c是记忆单元(cell), w w w是参数。对于每个单词 w t w_t wt,前向LSTM通过考虑从单词 w 1 w_1 w1到 w t w_t wt的上下文信息来编码 w t w_t wt,记作 h → t \overrightarrow h_t ht。同样后向LSTM层使用从 w n w_n wn到 w t w_t wt的上下文信息来编码 w t w_t wt,标记为 h ← t \overleftarrow h_t ht.最后,合并 h → t \overrightarrow h_t ht和 h ← t \overleftarrow h_t ht来表示 w t w_t wt的编码信息,标记为[ h → t \overrightarrow h_t ht, h ← t \overleftarrow h_t ht]
-
LSTM解码层
采用LSTM结构来产生标记序列,当检测到单词 w t w_t wt的标签,解码层的输入是BiLSTM编码曾的输出 h t h_t ht、前一个预测标签的embedding T t − 1 T_{t-1} Tt−1、前一个记忆单元值 c t − 1 ( 2 ) c_{t-1}^{(2)} ct−1(2)、解码层的前一个隐藏向量 h t − 1 ( 2 ) h_{t-1}^{(2)} ht−1(2)。LSTM解码层的记忆单元结构图如图3©所示,详细的计算如下:
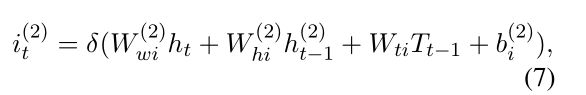
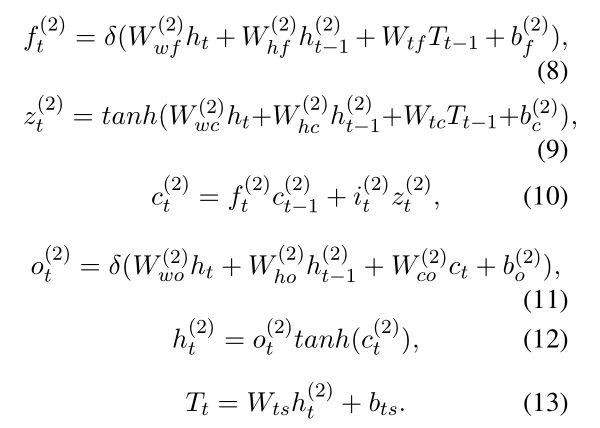
最后的softmax层基于预测的标签向量 T t T_t Tt计算归一化后的实体标签概率:
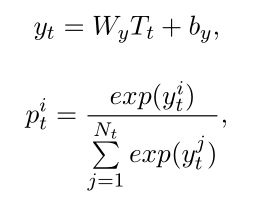
W y W_y Wy是softmax矩阵, N t N_t Nt是总的标签数量。因为 T T T与标签的embedding相似以及LSTM有学习长时依赖的能力,上述解码行为能够建模标签之间的相互作用。
-
偏置目标函数 (Bias Object Function)
最大化训练数据的对数似然概率来训练模型,使用RMSprop优化方法。目标函数定义为:
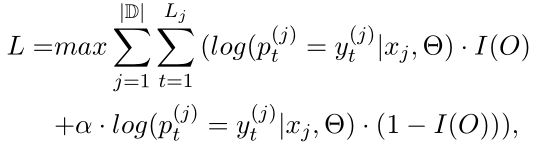
其中 ∣ D ∣ |D| ∣D∣是训练集的大小, L j L_j Lj是输入序列 x j x_j xj的长度, y t ( j ) y_t^{(j)} yt(j)是输入序列的标签, p t ( j ) p_t^{(j)} pt(j)是归一化的标签概率。 I ( O ) I(O) I(O)是指示函数,用于区分标签’O’和其他的标签。
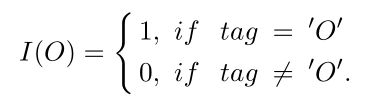
α \alpha α是偏置权重, α \alpha α越大,对相关标签的影响也越大。
4.实验
4.1 实验设置
-
数据集
公共数据集 N Y T 2 NYT^2 NYT2是通过远程监督方法产生的。训练数据集使用远程监督产生,测试数据集人工标注以确保质量。训练集包括353k个三元组,测试集包括3880个三元组。关系数量为24.
-
评估
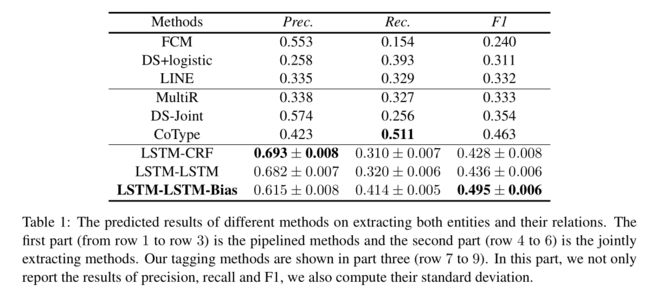
使用标准的Precision(Prec),Recall(Rec)和F1得分来评估结果。当关系类型和两个相关的实体都正确,则认为该三元组抽取正确。从测试集中随机采样10%作为验证集,剩下的作为测试集。结果如表1所示。
-
超参数
使用预训练的Word2vec词向量,维度为300.dropout比例为0.5.Bilstm编码层的神经元数量为300,解码层是600. α = 10 \alpha=10 α=10
-
Baselines
将我们的方法与几个经典的三元组抽取方法进行比较,包括:pipelined 方法,联合抽取方法,基于我们的标签方案的端到端的方法。各方法效果见表1.
4.2 实验结果
5. 分析与讨论
5.1 误差分析
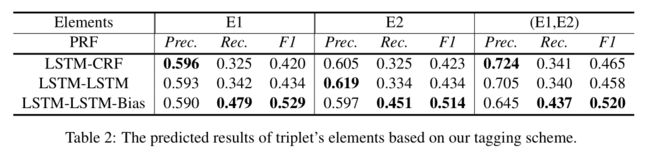
为了找出影响端到端模型结果的因素,我们分析了基于特定标签方法的模型预测三元组中每个元素的性能,如表2所示。
5.2 偏置损失(Biased Loss)分析
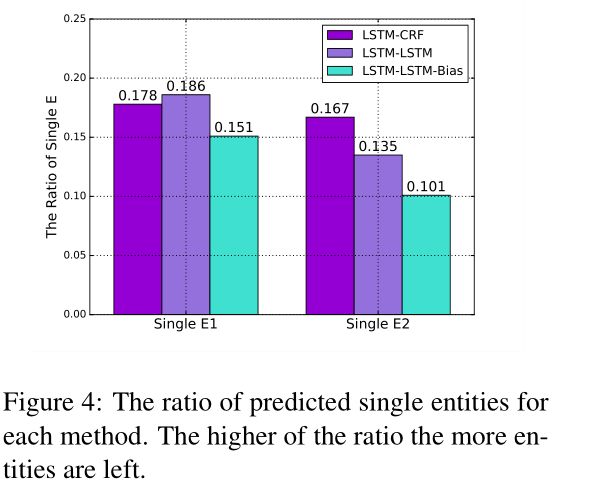
不同于LSTM-CRF和LSTM-LSTM,我们的方法添加了偏置损失来加强实体之间的联系。为了进一步分析偏置目标函数的影响,我们可视化了端到端模型预测的单个实体的比例,如图4所示。单个实体指的是那些没有相应实体的实体,就是无法找到成对实体的实体。图4中,不管是E1还是E2,我们的模型的单个实体比例均较低。意味着我们的方法能够有效联系两个实体。
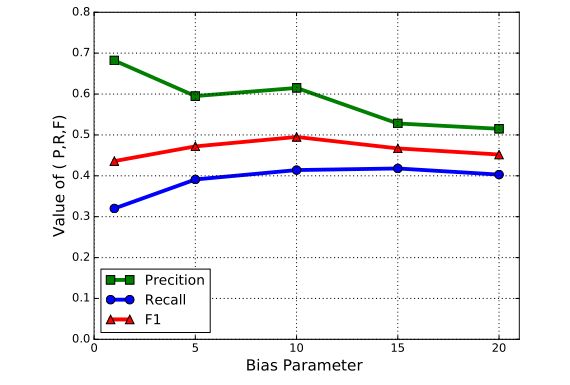
除此之外,通过改变偏置参数 α \alpha α从1到20,预测结果如图5所示。
5.3 案例研究

