“分布式”学习与项目总结
点击上面  免费订阅本账号!
免费订阅本账号!
作者:wc的一些事一些情
原文地址:https://www.cnblogs.com/wcd144140/
点击阅读全文前往
1、背景
Redis的出现确实大大地提高系统大并发能力支撑的可能性,转眼间Redis的最新版本已经是3.X版本了,但我们的系统依然继续跑着2.8,并很好地支撑着我们当前每天5亿访问量的应用系统。想当年Redis的单点单线程特性无法满足我们日益壮大的系统,只能硬着头皮把Redis“集群化”负载。且这套“集群化”方案良好地运行至今。虽难度不高,胜在简单和实用。无论简单还是很简单,记录这种经历是一件非常有趣的事情。
2、问题
系统访问量日益倍增,当前的Redis单点服务确实客观存在连续可用性以及支撑瓶颈风险,这种主/备模式在服务故障突发的情况下就会被动停止服务进行Redis节点切换。针对单点问题,我们结合自身的业务应用场景对Redis“集群化”提出几个主要目标:
1、避免单点情况,确保服务高可用;
2、紧可能把数据分布式存储,降低故障影响范围,满足服务灵活伸缩;
3、控制“集群化”的复杂度,从而控制边际成本;
3、过程
以上目标1和2就是所谓的分布式集群方案,把大问题分而治之。但最难把控的是目标3的“简化”实现。基于当时开源社区的那几种Redis集群方案,对于我们“简化”的要求来说相对略显臃肿。所以还是决定结合自身的业务应用等因素打造一个“合适”的Redis集群。
初始,我们凭借自己对分布式集群的认识勾结合应用场景勾勒出一个我们觉得足够“简化”的设计图,然后在这个“简化”架构的基础上继续击破我们各种应用场景所带来的缺陷。架构图如下:
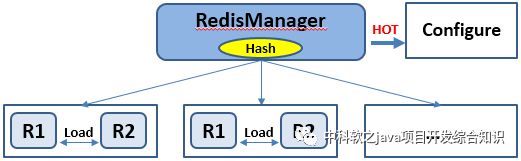
不难看出,我们想尽量通过一个RedisManager类和配置文件就能管理整个集群,不需要而外的软件支持。单例使用的时候RedisManager和配置文件就已经存在,RedisManager有各种单例操作的API重写(如get、set等),现在我们还是想保持这种模式对业务处理提供集群API,保持整个服务化应用框架(类似于今天所倡导的“微服务”)的轻量级特性。如上图所示,数据根据hash实现分成不同块放在不同的hash节点上,而每个hash节点必须存在两个Redis实例做hash节点集群支撑。为什么会是两个而不是三个或可扩展多个?我们是这样考虑的:
1、任何可持续扩展或抽象是站在规范这个巨人的肩膀上,我们秉承了整个系统架构“约定远远大于配置”的原则,适当地限制了边界范围换取控制性而又不失灵活。
2、对于我们系统目前的服务器质量来说,宕机的概率较小,双机(双实例)同时宕机的概率更小。就算这个概率出现,我们众多的业务场景还是允许这种部分间接性故障。这就是成本与质量之间的平衡和取舍。
3、由于我们没有使用额外的软件辅助,这些额外的操作都依赖了线程额外性能去弥补,例如两个Redis实例负载之间的同步等,所以我们是用性能换取部分一致性。负载节点越多性能消耗越多,所以两个实例做负载是我们“适当约束”和衡量的决策。
4、场景
4.1 场景1
在RedisManager类中有两个最基本的API,那就是c_get和c_set,其中c代表cluster。这两个API的基本实现如下:

从这两个基本操作可以看出,我们利用了遍历hash节点的所有负载实例来实现高可用性,并通过“同步写”来满足Redis数据“弱一致性”问题。而这个“同步写”就是额外的性能消耗,是依赖于双写过程中只成功写入一个实例的概率。因为Redis的稳定性,这种概率不高,所以额外性能消耗的概率也不高。以上操作几乎适用所有缓存类集群支持。这类缓存数据的强一致性更多放在数据库。数据在库表变更后,只需要把缓存数据delete即可。具体场景如下:
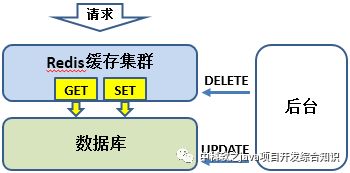
1、数据的变更通过“后台”维护,变更后同步DELETE缓存的相互数据。
2、业务线程请求缓存数据为空(c_get),则查询书库并把数据同步至缓存(c_set)。
3、Redis的hash节点集群安装集群内部实现负责和数据同步问题(c_get和c_set的实现原来)。
我们大部分业务数据缓存都是基于以上流程实现,这个流程会存在一个脏数据问题,例如当UPDATE库表成功但DELETE缓存数据不成功,就会存在脏数据。为了能尽可能降低脏数据的可能性,我们会在缓存设置缓存数据一个有效期(setex),就算脏数据出现,也只会影响seconds时间段。另外在后台变更过程如果DELETE缓存失败我们会有适当的提示语提示,好让认为发现继续进一步处理(例如重新变更)。
4.1 场景2
除了场景1的缓存用途外,还存在持久化场景。就是基于Redis做数据持久化集群,即所有操作都是基于Redis集群的。那么在数据一致性问题上就需要下点功夫了(c_set_sync),伪代码如下:
c_set_sync(key,value){
if(c_del_sync(key)){
c_set(key,value);
}
}
c_del_sync(key){
if(del(r1,key)&&del(r2,key)){
return true;
}
return false;
}通过以上伪代码可以看出,c_set_sync方法是先强制全部删除数据后再c_set,确保数据一致性。但这会出现一个数据丢失问题,就是c_del_sync后但set失败,那数据就会丢失,因为我们的数据几乎都是从后台操作的,如果出现这种数据丢失,简单的我们可以重新配置,复杂的我们可以通过日志恢复。
5 伸缩
以上两个场景更多围绕C(一致性)和A(可用性)的特性进行讨论,那么接下来再介绍一下我们“集群化”的P(分区容错性)特性。其实从我思考触发就可以看得出我们对P的权重是轻于C和A的。为什么这么说?因为我们系统架构是服务化架构(那时我还没接触到“微服务”概念),也就是从问题角度把大问题(业务统称)拆分各种小问题(服务化)逐一独立解决。各种小问题的业务复杂度我们紧可能控制到一定的轻量级程度(如果要量化解释的话那就是服务保持在10到20个API的规模,甚至小于10)。而且每个服务的承载量增长率预估值也在可控范围,所以到目前为止,极少有对Redis集群进行伸缩的需求。但少数的伸缩还是存在,但频率不高。对于一个完整的集群化方案,伸缩功能必须得有,只不过可能需要像以上两种场景那样针对不同业务使用场景在“规范化(原架构基础上)”下定制出各种场景API。
5.1 场景1
因为缓存场景相对简单,扩展或收缩hash节点后,如果在缓存中找不到数据,则会访问数据库重新Load数据到新的hash节点。伸缩期完成初期可能会对数据库带来一定的压力,这种压力的大小来源于设计hash数据的变化大小,这种数据变化大小取决于重新这个hash实现规则的变化的大小。所以,可根据具体情况来重写hash规则。
还有一个就是数据一致性问题(C和P),如何在动态伸缩过程中,确保缓存数据一致性。为了解决这个问题,我们在动态扩展过程中,停止各种更新接口操作。因为我们的数据变更都是通过管理员的,所以这个代价可以忽略不计。
5.2 场景2
此场景2对应是却却是4.2场景,如果用Redis集群做持久化工具,如果确保分区容错性(P)和数据一致性(C)。对于数据一致性问题,我们同样选择了场景1的办法,在伸缩期间停止所有更新操作,只保留读。这就避免了数据一致性问题。对于分区容错性问题,那就是如果确保重新hash后,数据能流向各种的新hash节点呢。为了继续保持这种“简化性”框架,我们继续选择了牺牲一定的性能来满足分区容错性问题,具体实现如下所示:

1、先尝试从New_Hash节点读取;
2、若不存在则继续寻找Old_Hash节点;
3、若还是不存在,则返回空;
4、若存在则c_set到New_Hash节点。
通过以上流程分析看到,我们牺牲了部分线程性能(第一次访问的变更数据的线程)的性能,可能会多2到3此的redis请求(每个Redis请求约5至10毫秒)。当伸缩完成后,重新放开数据更新API(我们服务化框架所有业务API都可以通过控制台控制并发并设置相关提示语,无需重启应用)。除了读取需要遍历新旧hash节点外,为了确保数据一致性问题,我们c_del_sync内置了一个判断是否存在旧hash节点。伪代码如下:
c_del_sync(key){
if(hash_old){
if(del(nr1,key)&&del(nr2,key) &&del(or1,key) &&del(or2,key)) {
true;
}
}else{
if(del(r1,key)&&del(r2,key)){
true;
}
}
return false;
}这种场景比较适用于set操作不多的场景,因为多set操作会多消耗约一倍的性能,如果觉得资源充足,这当然可以考虑。这种同步方式还有一个明显缺点就是短期内多次伸缩,会丢失Hash_Old_Old_....的数据,因为每次Hash_Old都无法能确保在下一次伸缩前1能00%同步所有数据(同步数据需要依赖数据访问,不排除部分数据一直没有被访问)。
6、总结
以上集群化方案已经运行约两年,系统日访问量约5亿,70%归功于Redis的支撑。以上集群方案是基于我们的行业业务场景和自身框架量身定做的,我更多地是想分享解决这个问题的思路和过程。世界上没有“绝对通用”,只有“相对通用”,通用范围越广,臃肿程度越高,可能带来的成本就会越大。我们更多的是面对如果“很好地”解决问题,这个“很好地”隐藏着各种各样的考虑因素。抉择就是一个为了能达到最佳效果而去衡量、选择、放弃的过程。
长按识别二维码关注,提升技能
