k8s架构及服务详解
1.容器及其三要素
回到顶部
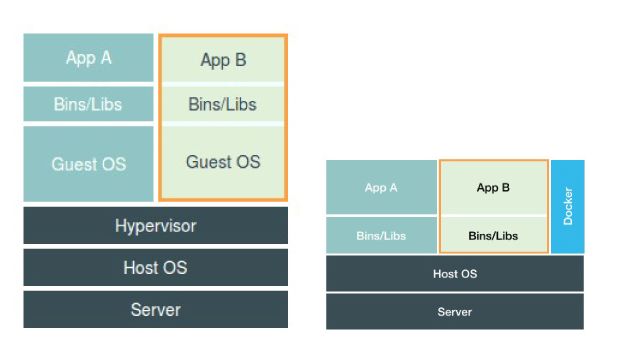
1.1.容器是什么
容器的本质是一种特殊的进程。
在linux容器中有三个重要的概念:Namespace、Cgroups、rootfs。
Namespace做隔离,让进程只能看到Namespace中的世界;
Cgroups 做限制,让这个“世界”围着一个看不见的墙。
rootfs 做文件系统,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。
这样就实现了进程在我们所看到的一个与世隔绝的房间,这个房间就是Pass项目赖以生存的"沙盒"。
回到顶部
1.2.Namespace
进入容器后,ps命令看到的容器的应用进程都是1号进程,这个其实是pid namespace导致,他其实就是个障眼法,
让你看到的是类似于一个新的虚拟机新环境,其实是不一样的,容器就是一个运行的进程,而容器中的其他进程则是pid为1的子进程。
除了刚刚pid namespace,还有其它的namespace如下:

容器是怎么新建namespace的?
docker创建容器,其实就是linux系统的一次fork的调用,
在进行fork调用时,会传入一些flag参数,这个参数可以控制对linux内核调用新的namespace。
回到顶部
1.3.rootfs
挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
容器的rootfs由三部分组成,1:只读层、2:可读写层、3:init层
1.只读层:都以增量的方式分别包含了 操作系统的一部分。
2.可读写:就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处。
3.Init 层:是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
5.kubernetes Service:让客户端发现pod并与之通信
回到顶部
5.1.Service介绍
回到顶部
5.1.1.Serice简介
5.1.1.1什么是Service
service是k8s中的一个重要概念,主要是提供负载均衡和服务自动发现。
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
5.1.1.2.Service的创建
创建Service的方法有两种:
1.通过kubectl expose创建
| 1 2 3 4 5 6 7 |
|
2.通过yaml文件创建
创建一个名为hostnames-yaohong的服务,将在端口80接收请求并将链接路由到具有标签选择器是app=hostnames的pod的9376端口上。
使用kubectl creat来创建serivice
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
5.1.1.3.检测服务
使用如下命令来检查服务:
| 1 2 3 |
|
5.1.1.4.在运行的容器中远程执行命令
使用kubectl exec 命令来远程执行容器中命令
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
回到顶部
5.2.连接集群外部的服务
5.2.1.介绍服务endpoint
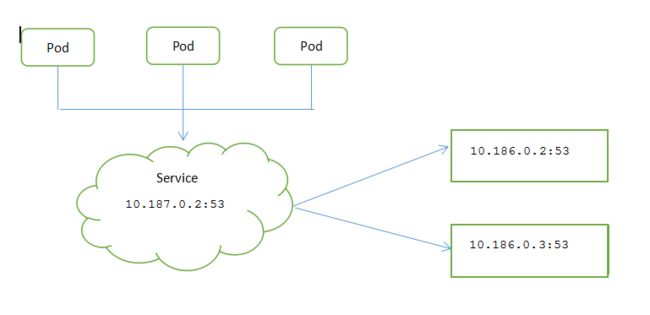
服务并不是和pod直接相连的,介于他们之间的就是Endpoint资源。
Endpoint资源就是暴露一个服务的IP地址和端口列表。
通过service查看endpoint方法如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
直接查看endpoint信息方法如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
5.2.2.手动配置服务的endpoint
如果创建pod时不包含选择器,则k8s将不会创建endpoint资源。这样就需要创建endpoint来指的服务的对应的endpoint列表。
service中创建endpoint资源,其中一个作用就是用于service知道包含哪些pod。
5.2.3.为外部服务创建别名
除了手动配置来访问外部服务外,还可以使用完全限定域名(FQDN)访问外部服务。
| 1 2 3 4 5 6 |
|
| 1 |
|
服务创建完成后,pod可以通过external-service.default.svc.cluster.local域名(甚至是external-service)连接外部服务。
回到顶部
5.3.将服务暴露给外部客户端
有3种方式在外部访问服务:
1.将服务的类型设置成NodePort;
2.将服务的类型设置成LoadBalance;
3.创建一个Ingress资源。
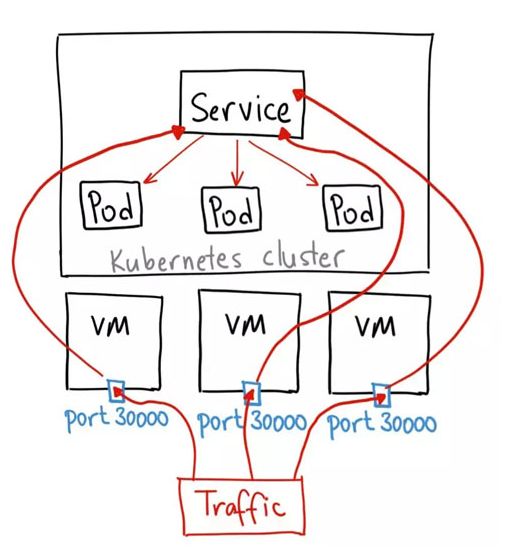
5.3.1.使用nodeport类型的服务
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
YAML 文件类似如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
这种方法有许多缺点:
1.每个端口只能是一种服务
2.端口范围只能是 30000-32767
如果节点/VM 的 IP 地址发生变化,你需要能处理这种情况
基于以上原因,我不建议在生产环境上用这种方式暴露服务。如果你运行的服务不要求一直可用,或者对成本比较敏感,你可以使用这种方法。这样的应用的最佳例子是 demo 应用,或者某些临时应用。
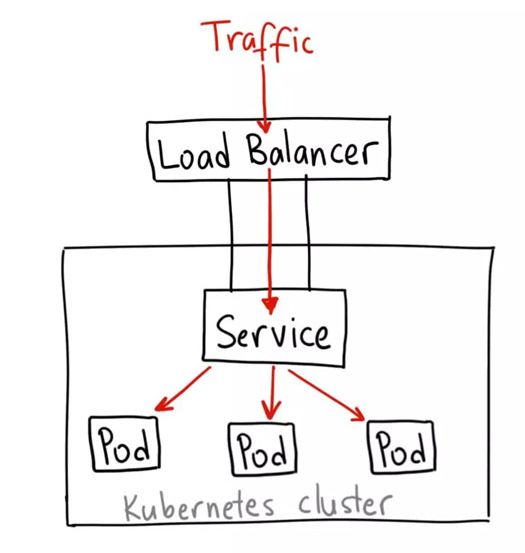
5.3.2.通过Loadbalance将服务暴露出来
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE 上,这种方式会启动一个 Network Load Balancer[2],它将给你一个单独的 IP 地址,转发所有流量到你的服务。
通过如下方法来定义服务使用负载均衡
| 1 2 3 4 5 6 7 8 9 10 11 |
|
何时使用这种方式?
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它没有过滤条件,没有路由等。这意味着你几乎可以发送任何种类的流量到该服务,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意种类。
这个方式的最大缺点是每一个用 LoadBalancer 暴露的服务都会有它自己的 IP 地址,每个用到的 LoadBalancer 都需要付费,这将是非常昂贵的。
回到顶部
5.4.通过Ingress暴露服务
为什么使用Ingress,一个重要的原因是LoadBalancer服务都需要创建自己的负载均衡器,以及独有的公有Ip地址,而Ingress只需要一个公网Ip就能为许多服务提供访问。
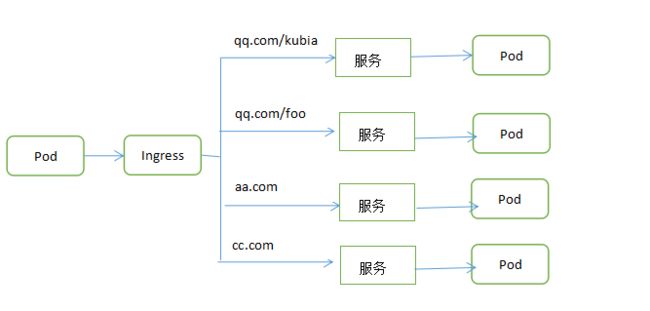
5.4.1.创建Ingress资源
Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 来做许多不同的事情,各种不同类型的 Ingress 控制器也有不同的能力。
编写如下ingress.yml文件
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
通过如下命令进行查看ingress
| 1 |
|
5.4.2.通过Ingress访问服务
通过kubectl get ing命令进行查看ingress
| 1 2 3 |
|
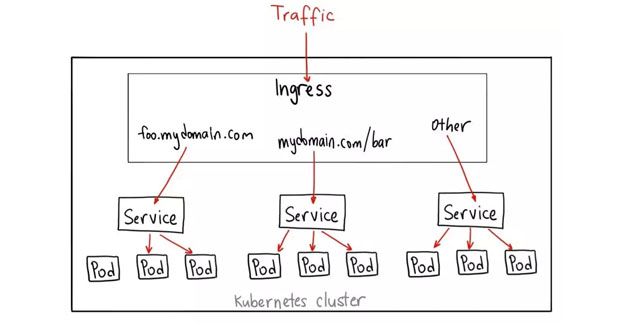
了解Ingress的工作原理
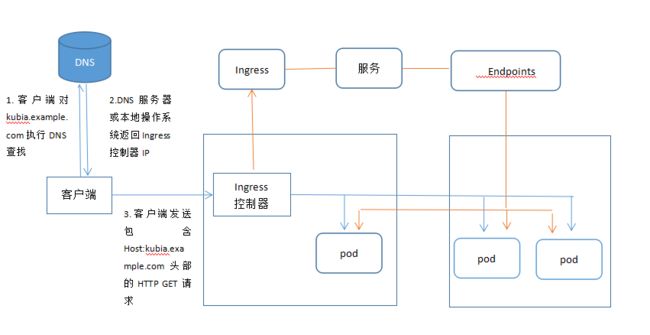
何时使用这种方式?
Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager[5],它可以为你的服务自动提供 SSL 证书。
如果你想要使用同一个 IP 暴露多个服务,这些服务都是使用相同的七层协议(典型如 HTTP),那么Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要为一个负载均衡器付费,且由于 Ingress是“智能”的,你还可以获取各种开箱即用的特性(比如 SSL、认证、路由等等)。
5.4.3.通过相同的Ingress暴露多少服务
1.将不同的服务映射到相同的主机不同的路径
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
2.将不同的服务映射到不同的主机上
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
5.4.4.配置Ingress处理TLS传输
客户端和控制器之间的通信是加密的,而控制器和后端pod之间的通信则不是。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
回到顶部
5.5.pod就绪后发出信号
5.5.1.介绍就绪探针
就绪探针有三种类型:
1.Exec探针,执行进程的地方。容器的状态由进程的退出状态代码确定。
2.HTTP GET探针,向容器发送HTTP GET请求,通过响应http状态码判断容器是否准备好。
3.TCP socket探针,它打开一个TCP连接到容器的指定端口,如果连接建立,则认为容器已经准备就绪。
启动容器时,k8s设置了一个等待时间,等待时间后才会执行一次准备就绪检查。之后就会周期性的进行调用探针,并根据就绪探针的结果采取行动。
如果某个pod未就绪成功,则会从该服务中删除该pod,如果pod再次就绪成功,则从新添加pod。
与存活探针区别:
就绪探针如果容器未准备就绪,则不会终止或者重启启动。
存活探针通过杀死异常容器,并用新的正常的容器来替代他保证pod正常工作。
就绪探针只有准备好处理请求pod才会接收他的请求。
重要性;
确保客户端只与正常的pod进行交互,并且永远不会知道系统存在问题。
5.5.2.向pod添加就绪探针
添加的yml文件如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
相关参数解释如下:
- initialDelaySeconds:容器启动和探针启动之间的秒数。
- periodSeconds:检查的频率(以秒为单位)。默认为10秒。最小值为1。
- timeoutSeconds:检查超时的秒数。默认为1秒。最小值为1。
- successThreshold:失败后检查成功的最小连续成功次数。默认为1.活跃度必须为1。最小值为1。
- failureThreshold:当Pod成功启动且检查失败时,Kubernetes将在放弃之前尝试failureThreshold次。放弃生存检查意味着重新启动Pod。而放弃就绪检查,Pod将被标记为未就绪。默认为3.最小值为1。
HTTP探针在httpGet上的配置项:
- host:主机名,默认为pod的IP。
- scheme:用于连接主机的方案(HTTP或HTTPS)。默认为HTTP。
- path:探针的路径。
- httpHeaders:在HTTP请求中设置的自定义标头。 HTTP允许重复的请求头。
- port:端口的名称或编号。数字必须在1到65535的范围内
模拟就绪探针
| 1 2 3 4 |
|
回到顶部
5.6.使用headless服务发现独立的pod
5.6.1.创建headless服务
Headless Service也是一种Service,但不同的是会定义spec:clusterIP: None,也就是不需要Cluster IP的Service。
顾名思义,Headless Service就是没头的Service。有什么使用场景呢?
-
第一种:自主选择权,有时候
client想自己来决定使用哪个Real Server,可以通过查询DNS来获取Real Server的信息。 -
第二种:
Headless Services还有一个用处(PS:也就是我们需要的那个特性)。Headless Service的对应的每一个Endpoints,即每一个Pod,都会有对应的DNS域名;这样Pod之间就可以互相访问。
6.kubernetes 磁盘、PV、PVC
回到顶部
6.1.介绍卷
6.1.1.卷的类型
emptyDir-用于存储临时数据的简单空目录
hostPath-用于将目录从工作节点的文件系统挂载到pod
nfs-挂载到pod中的NFS共享卷。
还有其他的如gitRepo、gcepersistenDisk
回到顶部
6.2.通过卷在容器间共享数据
6.2.1.使用emptyDir卷
卷的生命周期与pod的生命周期项关联,所以当删除pod时,卷的内容就会丢失。
使用empty示例代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
回到顶部
6.3.访问工作节点文件系统上的文件
6.3.1.hostPath卷
hostPath是持久性存储,emptyDir卷的内容随着pod的删除而删除。
使用hostPath会发现当删除一个pod,并且下一个pod使用了指向主机上相同路径的hostPath卷,则新pod将会发现上一个pod留下的数据,但前提是必须将其调度到与第一个pod相同的节点上。
所以当你使用hostPath时请务必考虑清楚,当重新起一个pod时候,必须要保证pod的节点与之前相同。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
回到顶部
6.4.使用持久化存储
怎样保证pod重新启动后调度到任意一个节点都有相同的数据可用,这就需要做到持久化存储。
因此必须要将数据存储在某种类型的网络存储(NAS)中。
各种支持的方式不尽相同,例如 GlusterFS 需要创建 Endpoint,Ceph/NFS 之流就没这么麻烦了。
6.4.1.使用NFS存储
以NFS为例,yml代码如下:

6.4.2.configmap和secert
secret和configmap可以理解为特殊的存储卷,但是它们不是给Pod提供存储功能的,而是提供了从集群外部向集群内部的应用注入配置信息的功能。ConfigMap扮演了K8S集群中配置中心的角色。ConfigMap定义了Pod的配置信息,可以以存储卷的形式挂载至Pod中的应用程序配置文件目录,从configmap中读取配置信息;也可以基于环境变量的形式,从ConfigMap中获取变量注入到Pod容器中使用。但是ConfigMap是明文保存的,如果用来保存数据库账号密码这样敏感信息,就非常不安全。一般这样的敏感信息配置是通过secret来保存。secret的功能和ConfigMap一样,不过secret是通过Base64的编码机制保存配置信息。
从ConfigMap中获取配置信息的方法有两种:
- 一种是利用环境变量将配置信息注入Pod容器中的方式,这种方式只在Pod创建的时候生效,这就意味着在ConfigMap中的修改配置信息后,更新的配置不能被已经创建Pod容器所应用。
- 另一种是将ConfigMap做为存储卷挂载至Pod容器内,这样在修改ConfigMap配置信息后,Pod容器中的配置也会随之更新,不过这个过程会有稍微的延迟。
ConfigMap当作存储卷挂载至Pod中的用法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
secert的方法类似,只是secert对数据进行了加密
回到顶部
6.5.从底层存储技术解耦pod
6.5.1.介绍持久卷和持久卷声明
当集群用户需要在其pod中使用持久化存储时,他们首先创建持久化声明(PVC)清单,指定所需要的最低容量要求,和访问模式,然后用户将持久卷声明清单提交给kubernetes API服务器,kubernetes将找到可以匹配的持久卷并将其绑定到持久卷声明。
持久卷声明可以当做pod中的一个卷来使用,其他用户不能使用相同的持久卷,除非先通过删除持久卷声明绑定来释放。
6.5.2.创建持久卷
下面创建一个 PV mypv1,配置文件pv1.yml 如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
1.accessModes 指定访问模式为 ReadWriteOnce,支持的访问模式有:
ReadWriteOnce – PV 能以 read-write 模式 mount 到单个节点。
ReadOnlyMany – PV 能以 read-only 模式 mount 到多个节点。
ReadWriteMany – PV 能以 read-write 模式 mount 到多个节点。
2.persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle,支持的策略有:
Retain – 需要管理员手工回收。
Recycle – 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*。
Delete – 删除 Storage Provider 上的对应存储资源,例如 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
创建 pv:
| 1 2 |
|
查看pv:
| 1 2 3 |
|
STATUS 为 Available,表示 yh-pv1就绪,可以被 PVC 申请。
6.5.3.通过持久卷声明来获取持久卷
接下来创建 PVC mypvc1,配置文件 pvc1.yml 如下:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
PVC 就很简单了,只需要指定 PV 的容量,访问模式和 class。
执行命令创建 mypvc1:
| 1 2 |
|
查看pvc
| 1 2 3 |
|
从 kubectl get pvc 和 kubectl get pv 的输出可以看到 yh-pvc1 已经 Bound 到yh- pv1,申请成功。
| 1 2 3 |
|
6.5.4.在pod中使用持久卷声明
上面已经创建好了pv和pvc,pod中直接使用这个pvc即可
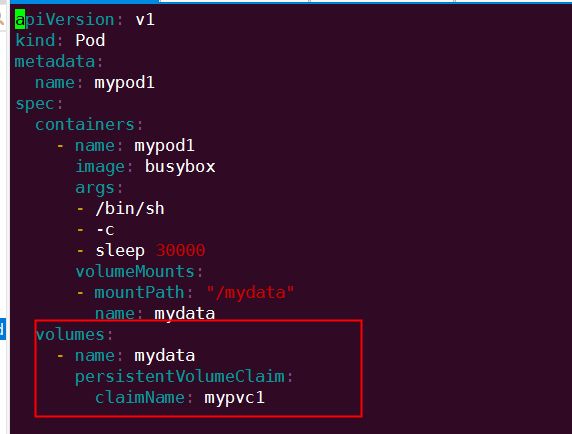
与使用普通 Volume 的格式类似,在 volumes 中通过 persistentVolumeClaim 指定使用 mypvc1 申请的 Volume。
通过命令创建mypod1:

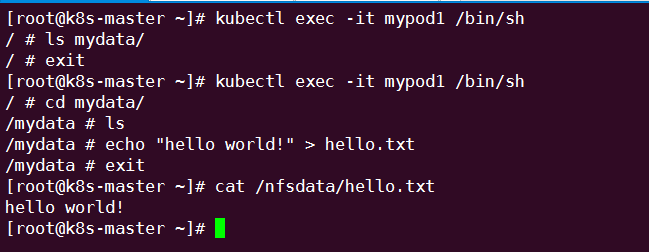
可见,在 Pod 中创建的文件 /mydata/hello 确实已经保存到了 NFS 服务器目录 /nfsdata中。
如果不再需要使用 PV,可用删除 PVC 回收 PV。
6.5.5.回收持久卷
当 PV 不再需要时,可通过删除 PVC 回收。
![]()
未删除pvc之前 pv的状态是Bound
![]()
![]()
删除pvc之后pv的状态变为Available,,此时解除绑定后则可以被新的 PVC 申请。
/nfsdata文件中的文件被删除了

![]()
因为 PV 的回收策略设置为 Recycle,所以数据会被清除,但这可能不是我们想要的结果。如果我们希望保留数据,可以将策略设置为 Retain。
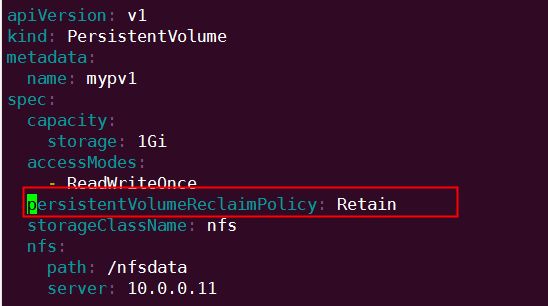
通过 kubectl apply 更新 PV:

回收策略已经变为 Retain,通过下面步骤验证其效果:

① 重新创建 mypvc1。
② 在 mypv1 中创建文件 hello。
③ mypv1 状态变为 Released。
④ PV 中的数据被完整保留。
虽然 mypv1 中的数据得到了保留,但其 PV 状态会一直处于 Released,不能被其他 PVC 申请。为了重新使用存储资源,可以删除并重新创建 mypv1。删除操作只是删除了 PV 对象,存储空间中的数据并不会被删除。

新建的 mypv1 状态为 Available,已经可以被 PVC 申请。
PV 还支持 Delete 的回收策略,会删除 PV 在 Storage Provider 上对应存储空间。NFS 的 PV 不支持 Delete,支持 Delete 的 Provider 有 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
回到顶部
6.6.持久卷的动态配置
6.6.1.通过StorageClass资源定义可用存储类型
前面的例子中,我们提前创建了 PV,然后通过 PVC 申请 PV 并在 Pod 中使用,这种方式叫做静态供给(Static Provision)。
与之对应的是动态供给(Dynamical Provision),即如果没有满足 PVC 条件的 PV,会动态创建 PV。相比静态供给,动态供给有明显的优势:不需要提前创建 PV,减少了管理员的工作量,效率高。
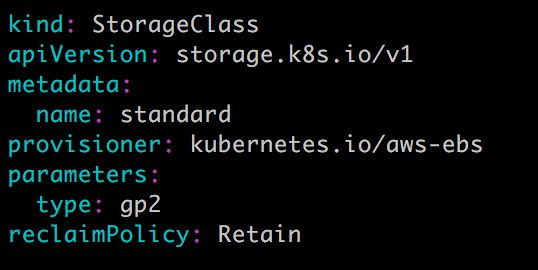
动态供给是通过 StorageClass 实现的,StorageClass 定义了如何创建 PV,下面是两个例子。
StorageClass standard:
StorageClass slow:
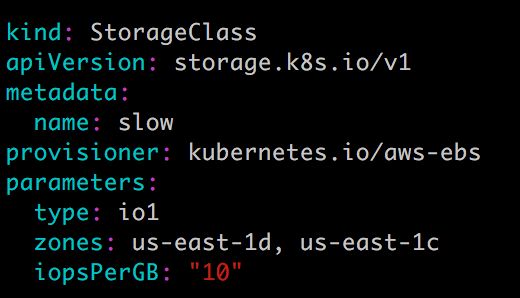
这两个 StorageClass 都会动态创建 AWS EBS,不同在于 standard 创建的是 gp2 类型的 EBS,而 slow 创建的是 io1 类型的 EBS。不同类型的 EBS 支持的参数可参考 AWS 官方文档。
StorageClass 支持 Delete 和 Retain 两种 reclaimPolicy,默认是 Delete。
与之前一样,PVC 在申请 PV 时,只需要指定 StorageClass 和容量以及访问模式,比如:
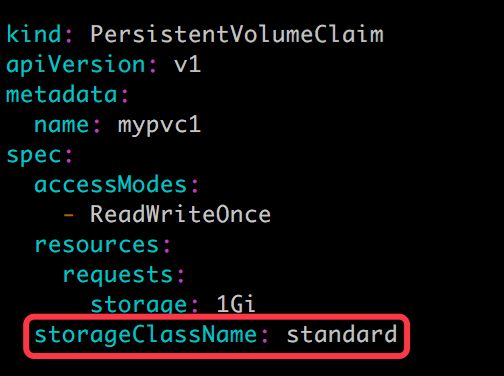
除了 AWS EBS,Kubernetes 支持其他多种动态供给 PV 的 Provisioner,完整列表请参考 Storage Classes | Kubernetes
6.6.2.PV&&PVC在应用在mysql的持久化存储
下面演示如何为 MySQL 数据库提供持久化存储,步骤为:
-
创建 PV 和 PVC。
-
部署 MySQL。
-
向 MySQL 添加数据。
-
模拟节点宕机故障,Kubernetes 将 MySQL 自动迁移到其他节点。
-
验证数据一致性。
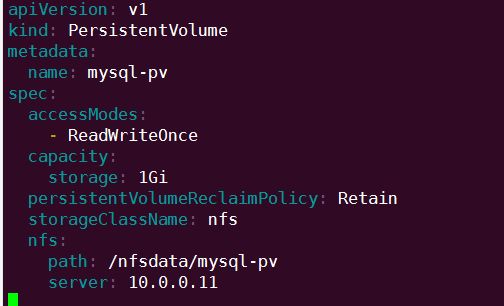
首先创建 PV 和 PVC,配置如下:
mysql-pv.yml
mysql-pvc.yml
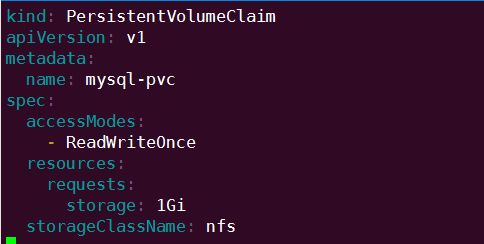
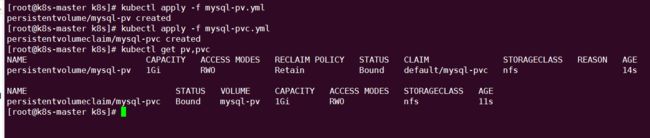
创建 mysql-pv 和 mysql-pvc:
接下来部署 MySQL,配置文件如下:
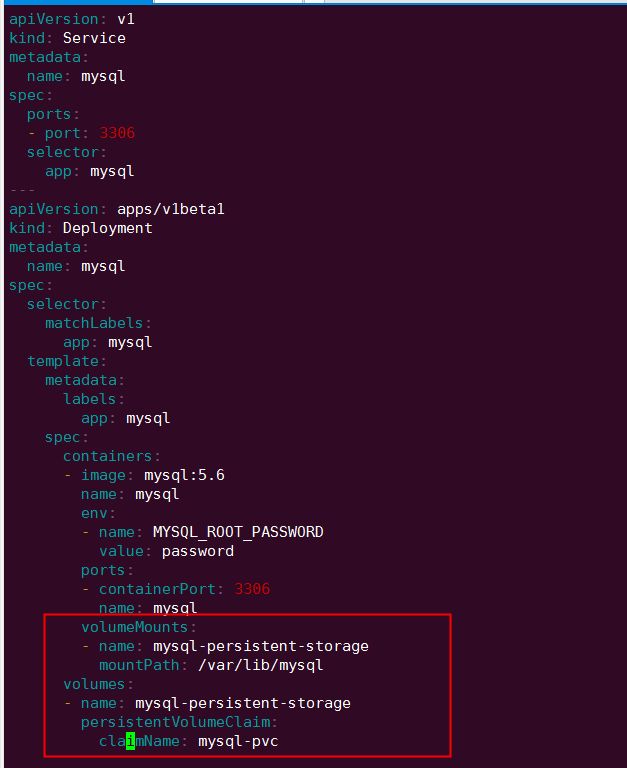
PVC mysql-pvc Bound 的 PV mysql-pv 将被 mount 到 MySQL 的数据目录 var/lib/mysql。

MySQL 被部署到 k8s-node2,下面通过客户端访问 Service mysql:
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword

更新数据库:
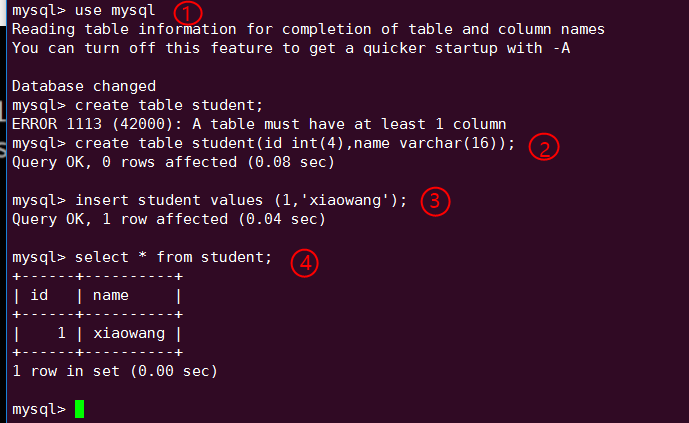
① 切换到数据库 mysql。
② 创建数据库表 my_id。
③ 插入一条数据。
④ 确认数据已经写入。
关闭 k8s-node2,模拟节点宕机故障。
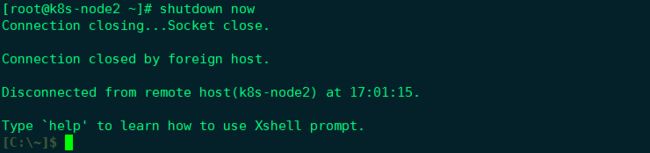
验证数据的一致性:
由于node2节点已经宕机,node1节点接管了这个任务。

通过kubectl run 命令 进入node1的这个pod里,查看数据是否依旧存在


MySQL 服务恢复,数据也完好无损。
7.kubernetes ConfigMap和Secret:配置应用程序
回到顶部
7.1.配置容器化应用程序
7.2.向容器传递命令行参数
7.2.1.待Docker中定义命令与参数
1.了解ENTRYPOINT与CMD
ENTRYPOINT定义容器启动时被调用的可以执行程序
CMD指定传递给ENTRYP的参数
dockerfile 内容如下
| 1 2 3 4 5 6 |
|
当启动镜像时,容器启动时执行如下命令:tail -f /var/log/aa.log
或者在docker run
7.2.2.在kubernetes中覆盖命令行和参数
在k8s中定义容器时,镜像的ENTRYPOINT和CMD都可以被覆盖,仅需在容器定义中设置熟悉command和args的值
对应参数如下:
| Docker | kubernetes | 描述 |
| ENTRYPOINT | command | 容器中运行的可执行文件 |
| CMD | args | 传给可执行文件的参数 |
相关yml代码如下:
| 1 2 3 4 5 6 |
|
回到顶部
7.3.为容器设置环境变量
7.3.1.在容器定义中指定环境变量
与容器的命令和参数设置相同,环境变量列表无法在pod创建后被修改。
在pod的yml文件中设置容器环境变量代码如下:
| 1 2 3 4 5 6 7 8 |
|
7.3.2.在环境变量值中引用其他环境变量
使用$( VAR )引用环境变量,
相关ym代码如下:
| 1 2 3 4 5 |
|
回到顶部
7.4.利用ConfigMap解耦配置
7.4.1.ConfigMap介绍
kubernetes允许将配置选项分离到独立的资源对象ConfigMap中,本质上就是一个键/值对映射,值可以是短字面变量,也可以是完整的配置文件。
应用无须直接读取ConfigMap,甚至根本不需要知道其是否存在。
映射的内容通过环境变量或者卷文件的形式传递给容器,而并非直接传递给容器,命令行参数的定义中也是通过$(ENV_VAR)语法变量
7.4.2.创建ConfigMap
使用kubectl creat configmap创建ConfigMap中间不用加-f。
1.使用指令创建ConfigMap
| 1 |
|
2.从文件内容创建ConfigMap条目
| 1 |
|
使用如下命令,会将文件内容存储在自定义的条目下。与字面量使用相同
| 1 |
|
3.从文件夹创建ConfigMap
| 1 |
|
4.合并不同选项
| 1 2 3 4 |
|
5.获取ConfigMap
| 1 |
|
7.4.3.给容器传递ConfigMap条目作为环境变量
引用环境变量中的参数值给当前变量
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
7.4.4.一次性传递ConfigMap的所有条目作为环境变量
| 1 2 3 4 5 6 7 8 9 10 11 |
|
7.4.5.使用ConfigMap卷将条目暴露为文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
可以使用如下命令查看到/etc/nginx/conf.d文件下面包含fortune-config
| 1 |
|
回到顶部
7.5.使用Secert给容器传递敏感数据
7.5.1.介绍Secert
Secret结构和ConfigMap类似,均是键/值对的映射。
使用方法也和ConfigMap一样,可以:
1.将Secret条目作为环境变量传递给容器,
2.将Secret条目暴露为卷中文件
ConfigMap存储非敏感的文本配置数据,采用Secret存储天生敏感的数据
7.5.2.默认令牌Secret
1.查看secret
| 1 2 3 |
|
2.描述secret
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
7.5.3.创建Secret
1.创建一个名为https-yh的generic secret
| 1 |
|
2.创建一个secret.yaml文件,内容用base64编码
$ echo -n 'admin' | base64 YWRtaW4= $ echo -n '1f2d1e2e67df' | base64 MWYyZDFlMmU2N2Rm
yaml文件内容:
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: username: YWRtaW4= password: MWYyZDFlMmU2N2Rm
创建:
$ kubectl create -f ./secret.yaml secret "mysecret" created
解析Secret中内容
$ kubectl get secret mysecret -o yaml apiVersion: v1 data: username: YWRtaW4= password: MWYyZDFlMmU2N2Rm kind: Secret metadata: creationTimestamp: 2016-01-22T18:41:56Z name: mysecret namespace: default resourceVersion: "164619" selfLink: /api/v1/namespaces/default/secrets/mysecret uid: cfee02d6-c137-11e5-8d73-42010af00002 type: Opaque
base64解码:
$ echo 'MWYyZDFlMmU2N2Rm' | base64 --decode 1f2d1e2e67df
7.5.4.对比ConfigMap与Secret
Secret的条目内容会进行Base64格式编码,而ConfigMap直接以纯文本展示。
1.为二进制数据创建Secret
Base64可以将二进制数据转换为纯文本,并以YAML或Json格式进行展示
但要注意Secret的大小限制是1MB
2.stringDate字段介绍
Secret可以通过StringDate字段设置条目的纯文本
| 1 2 3 4 5 6 7 |
|
7.5.5.在pod中使用Secret
secret可以作为数据卷挂载或者作为环境变量暴露给Pod中的容器使用,也可以被系统中的其他资源使用。比如可以用secret导入与外部系统交互需要的证书文件等。
在Pod中以文件的形式使用secret
- 创建一个Secret,多个Pod可以引用同一个Secret
- 修改Pod的定义,在
spec.volumes[]加一个volume,给这个volume起个名字,spec.volumes[].secret.secretName记录的是要引用的Secret名字 - 在每个需要使用Secret的容器中添加一项
spec.containers[].volumeMounts[],指定spec.containers[].volumeMounts[].readOnly = true,spec.containers[].volumeMounts[].mountPath要指向一个未被使用的系统路径。 - 修改镜像或者命令行使系统可以找到上一步指定的路径。此时Secret中
data字段的每一个key都是指定路径下面的一个文件名
下面是一个Pod中引用Secret的列子:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
每一个被引用的Secret都要在spec.volumes中定义
如果Pod中的多个容器都要引用这个Secret那么每一个容器定义中都要指定自己的volumeMounts,但是Pod定义中声明一次spec.volumes就好了。
映射secret key到指定的路径
可以控制secret key被映射到容器内的路径,利用spec.volumes[].secret.items来修改被映射的具体路径
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
发生了什么呢?
- username被映射到了文件
/etc/foo/my-group/my-username而不是/etc/foo/username - password没有变
Secret文件权限
可以指定secret文件的权限,类似linux系统文件权限,如果不指定默认权限是0644,等同于linux文件的-rw-r--r--权限
设置默认权限位
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 256
上述文件表示将secret挂载到容器的/etc/foo路径,每一个key衍生出的文件,权限位都将是0400
由于JSON不支持八进制数字,因此用十进制数256表示0400,如果用yaml格式的文件那么就很自然的使用八进制了
同理可以单独指定某个key的权限
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 511
从volume中读取secret的值
值得注意的一点是,以文件的形式挂载到容器中的secret,他们的值已经是经过base64解码的了,可以直接读出来使用。
$ ls /etc/foo/ username password $ cat /etc/foo/username admin $ cat /etc/foo/password 1f2d1e2e67df
被挂载的secret内容自动更新
也就是如果修改一个Secret的内容,那么挂载了该Secret的容器中也将会取到更新后的值,但是这个时间间隔是由kubelet的同步时间决定的。最长的时间将是一个同步周期加上缓存生命周期(period+ttl)
特例:以subPath形式挂载到容器中的secret将不会自动更新
以环境变量的形式使用Secret
- 创建一个Secret,多个Pod可以引用同一个Secret
- 修改pod的定义,定义环境变量并使用
env[].valueFrom.secretKeyRef指定secret和相应的key - 修改镜像或命令行,让它们可以读到环境变量
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
restartPolicy: Never
容器中读取环境变量,已经是base64解码后的值了:
$ echo $SECRET_USERNAME admin $ echo $SECRET_PASSWORD 1f2d1e2e67df
使用imagePullSecrets
创建一个专门用来访问镜像仓库的secret,当创建Pod的时候由kubelet访问镜像仓库并拉取镜像,具体描述文档在 这里
设置自动导入的imagePullSecrets
可以手动创建一个,然后在serviceAccount中引用它。所有经过这个serviceAccount创建的Pod都会默认使用关联的imagePullSecrets来拉取镜像,
9.deployment:声明式的升级应用
Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。
而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。
通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。

回到顶部
9.1.使用RC实现滚动升级
| 1 |
|
使用kubia-v2版本应用来替换运行着kubia-v1的RC,将新的复制控制器命名为kubia-v2,并使用luksa/kubia:v2最为镜像。
升级完成后使kubectl describe rc kubia-v2查看升级后的状态。
为什么现在不再使用rolling-update?
1.直接更新pod和RC的标签并不是一个很的方案;
2.kubectl只是执行升级中的客户端,但如果执行kubectl过程中是去了网络连接,升级将会被中断,pod和RC将会处于一个中间的状态,所以才有了Deployment资源的引入。
回到顶部
9.2.使用Deployment声明式的升级应用
Rs替代Rc来复制个管理pod。
创建Deployment前确保删除所有的RC和pod,但是暂时保留Service,
kubectl delete rc --all
创建Deployment
| 1 2 3 4 5 6 7 8 |
|
回到顶部
9.3.触发deployment升级
| 1 2 3 4 |
|
修改configmap并不会触发升级,如果想要触发,可以创建新的configmap并修改pod模板引用新的configmap。
回到顶部
9.4.回滚deployment
在上述升级deployment过程中可以使用如下命令来观察升级的过程
| 1 |
|
如果出现报错,如何进行停止?可以使用如下命令进行回滚到先前部署的版本
| 1 |
|
如何显示deployment的历史版本?
| 1 |
|
如何回滚到特定的版本?
| 1 |
|
回到顶部
9.5.控制滚动升级的速率
在deployment的滚动升级过程中,有两个属性决定一次替换多少个pod:maxSurge、maxUnavailable,可以通过strategy字段下的rollingUpdate的属性来配置,
maxSurge:决定期望的副本数,默认值为25%,如果副本数设置为4个,则在滚动升级过程中,不会运行超过5个pod。
maxUnavaliable: 决定允许多少个pod处于不可用状态,默认值为25%,如果副本数为4,那么只能有一个pod处于不可用状态,
默认情况下如果10分钟内没有升级完成,将被视为失败,如果要修改这个参数可以使用kubectl describe deploy kubia 查看到一条ProgressDeadline-Exceeded的记录,可以修改此项参数修改判断时间。
回到顶部
9.6.金丝雀发布和蓝绿发布
金丝雀部署:优先发布一台或少量机器升级,等验证无误后再更新其他机器。优点是用户影响范围小,不足之处是要额外控制如何做自动更新。
蓝绿部署:2组机器,蓝代表当前的V1版本,绿代表已经升级完成的V2版本。通过LB将流量全部导入V2完成升级部署。优点是切换快速,缺点是影响全部用户。
10.Statefulset:部署有状态的多副本应用
回到顶部
10.1.什么是Statefulset
StatefulSet是Kubernetes提供的管理有状态应用的负载管理控制器API。
特点:
1.具有固定的网络标记(主机名)
2.具有持久化存储
3.需要按顺序部署和扩展
4.需要按顺序终止和删除
5.需要按顺序滚动和更新
有状态应用:这种实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,就被称为“有状态应用”(Stateful Application)。
回到顶部
10.2.statefulset的创建
statefulset的创建顺序从0到N-1,终止顺序则相反,如果需要对satateful扩容,则之前的n个pod必须存在,如果要终止一个pod,则他的后续pod必须全部终止。
创建statefulset
| 1 |
|
查看statefulset
| 1 |
|
statefulset会使用一个完全一致的pod来替换被删除的pod。
statefulset扩容和缩容时,都会删除最高索引的pod,当这个pod完全被删除后,才回删除拥有次高索引的pod。
回到顶部
10.3.statefulset中发现伙伴的节点
通过DNS中SRV互相发现。
回到顶部
10.4.更新statefulset
| 1 |
|
但修改后pod不会自动 被更新,需要手动delete pod后会重新调度更新。
回到顶部
10.5.statefulset如何处理节点失效
11.Kubernetes架构及相关服务详解
回到顶部
11.1.了解架构
K8s分为两部分:
1.Master节点
2.node节点
Master节点组件:
1.etcd分布式持久化存储
2.api服务器
3.scheduler
4.controller
Node节点:
1.kubelet
2.kube-proxy
3.容器运行时(docker、rkt及其它)
附加组件:
1.Dns服务器
2.仪表板
3.ingress控制器
4.Heapster控制器
5.网络容器接口插件
回到顶部
11.2.k8s组件分布式特性
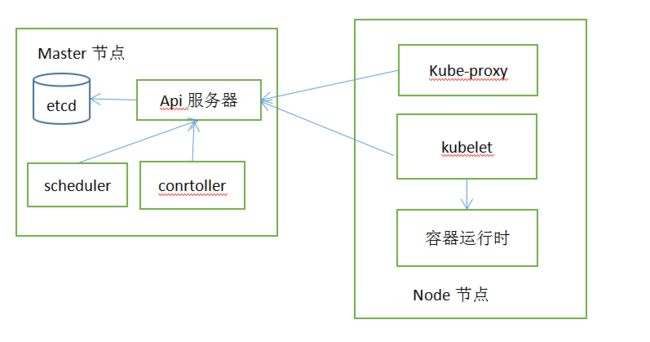
k8s系统组件之间通信只能通过API服务器通信,他们之间不会之间进行通信。
API服务器是和etcd通信的唯一组件,其他组件不会直接和etcd进行通信。
API服务器与其他组件之间的通信基本上是由其他组件发起的,
| 1 2 |
|
回到顶部
11.3.k8s如何使用etcd
etcd是一个响应快,分布式,一致的key-value存储。
是k8s存储集群状态和元数据唯一的地方,具有乐观锁特性,
| 1 2 3 |
|
资源如何存储在etcd中
flannel操作etcd使用的是v2的API,而kubernetes操作etcd使用的v3的API,所以在下面我们执行etcdctl的时候需要设置ETCDCTL_API环境变量,该变量默认值为2。
etcd是使用raft一致性算法实现的,是一款分布式的一致性KV存储,主要用于共享配置和服务发现。
Etcd V2和V3之间的数据结构完全不同,互不兼容。
确保etcd集群一致性
一致性算法要求大部分节点参与,才能进行到下一个状态,需要有过半的节点参与状态的更新,所以导致etcd的节点必须为奇数个。
回到顶部
11.4.API服务器
Kubernetes API服务器为API对象验证和配置数据,这些对象包含Pod,Service,ReplicationController等等。API Server提供REST操作以及前端到集群的共享状态,所有其它组件可以通过这些共享状态交互。
1.API提供RESTful API的形式,进行CRUD(增删查改)集群状态
2.进行校验
3.处理乐观锁,用于处理并发问题,
4.认证客户端
(1)通过认证插件认证客户端
(2)通过授权插件认证客户端
(3)通过准入插件验证AND/OR修改资源请求
API服务器如何通知客户端资源变更
API服务器不会去创建pod,同时他不会去管理服务的端点,
它做的是,启动控制器,以及一些其他的组件来监控一键部署的资源变更,是得组件可以再集群元数据变化时候执行任何需要做的任务,
回到顶部
11.5.了解调度器
调度器指定pod运行在哪个集群节点上。
调度器不会命令选中节点取运行pod,调度器做的就是通过api服务器更新pod的定义。然后api服务器再去通知kubelet该pod已经被调用。当目标节点的kubelet发现该pod被调度到本节点,就会创建并运行pod容器。
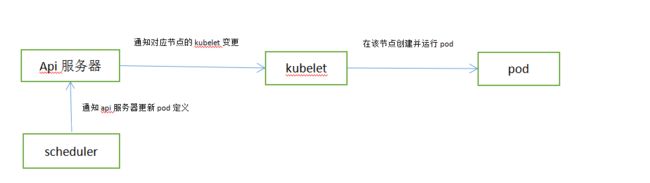
调度方法:
1.通过算法过滤所有节点,找到最优节点
2.查找可用节点
(1)是否满足对硬件的资源要求
(2)节点是否资源耗尽
(3)pod是否要求被调度到指定的节点、
(4)是否和要求的lable一致
(5)需求端口是否被占用
(6)是否有符合要求的存储卷
(7)是否容忍节点的污染
回到顶部
11.6.介绍控制器管理器中运行的控制器
(1)RC控制器
启动RC资源的控制器叫做Replication管理器。
RC的操作可以理解为一个无限的循环,每次循环,控制器都会查找符合其pod选择器的pod数量,并且将该数值和期望的复制集数量做比较。
(2)RS控制器
与RC类似
(3)DaemonSet以及job控制器
从他们各自资源集中定义pod模板创建pod资源,
(4)Deployment控制器
Deployment控制器负责使deployment的实际状态与对应的Deployment API对象期望状态同步。
每次Deployment对象修改后,Deployment控制器会滚动升级到新的版本。通过创建ReplicaSet,然后按照Deployment中定义的策略同时伸缩新、旧RelicaSet,直到旧pod被新的替代。
(5)StatefulSet控制器
StatefulSet控制器会初始化并管理每个pod实例的持久声明字段。
(6)Node控制器
Node控制器管理Node资源,描述了集群的工作节点。
(7)Service控制器
Service控制器就是用来在loadBalancer类型服务被创建或删除,从基础设施服务请求,释放负载均衡器的。
当Endpoints监听到API服务器中Aervice资源和pod资源发生变化时,会对应修改、创建、删除Endpoints资源。
(8)Endpoint资源控制器
Service不会直接连接到pod,而是通过一个ip和端口的列表,EedPoint管理器就是监听service和pod的变化,将ip和端口更新endpoint资源。
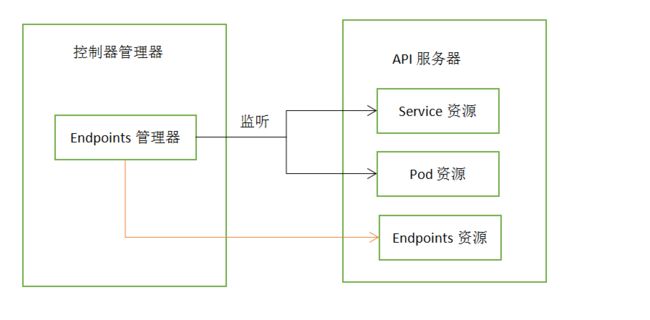
(9)Namespace控制器
当收到删除namespace对象的通知时,控制器通过API服务群删除后所有属于该命名空间的资源。
(10)PV控制器
创建一个持久卷声明时,就找到一个合适的持久卷进行绑定到声明。
回到顶部
11.7.kubelet做了什么
了解kubelet的工作内容
简单来说,就是负责所有运行在工作节点上的全部内容。
第一个任务,在api服务器中创建一个node资源来注册该节点;第二任务,持续监控api服务器是否把该节点分配给pod;第三任务,启动pod;第四任务,持续监控运行的容器,向api服务器报告他们的状态,事件和资源消耗。
第五任务,kubelet也是运行容器的存活探针的组件,当探针报错时,他会重启容器;第六任务,当pod从api服务器删除时,kubelet终止容器,并通知服务器pod已经终止。
11.1.7.kube-proxy的作用
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。
kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
kube-proxy有两种代理模式,userspace和iptables,目前都是使用iptables。
12.kubernetes API服务器的安全防护
回到顶部
12.1.了解认证机制
启动API服务器时,通过命令行选项可以开启认证插件。
12.1.1.用户和组
了解用户:
分为两种连接到api服务器的客户端:
1.真实的人
2.pod,使用一种称为ServiceAccount的机制
了解组:
认证插件会连同用户名,和用户id返回组,组可以一次性给用户服务多个权限,不用单次赋予,
system:unauthenticated组:用于所有认证插件都不会认证客户端身份的请求。
system:authenticated组:会自动分配给一个成功通过认证的用户。
system:serviceaccount组:包含 所有在系统中的serviceaccount。
system:serviceaccount:
12.1.2 ServiceAccount介绍
每个pod中都包含/var/run/secrets/kubernetes.io/serviceaccount/token文件,如下图所示,文件内容用于对身份进行验证,token文件持有serviceaccount的认证token。

应用程序使用token去连接api服务器时,认证插件会对serviceaccount进行身份认证,并将serviceaccount的用户名传回到api服务器内部。
serviceaccount的用户名格式如下:
system:serviceaccount:
ServiceAccount是运行在pod中的应用程序,和api服务器身份认证的一中方式。
了解ServiceAccount资源
ServiceAcount作用在单一命名空间,为每个命名空间创建默认的ServiceAccount。

多个pod可以使用相同命名空间下的同一的ServiceAccount,
ServiceAccount如何与授权文件绑定
在pod的manifest文件中,可以指定账户名称的方式,将一个serviceAccount赋值给一个pod,如果不指定,将使用该命名空间下默认的ServiceAccount.
可以 将不同的ServiceAccount赋值给pod,让pod访问不同的资源。
12.1.3创建ServiceAccount
为了集群的安全性,可以手动创建ServiceAccount,可以限制只有允许的pod访问对应的资源。
创建方法如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
使用describe来查看ServiceAccount。
| 1 2 3 4 5 6 7 8 9 |
|
查看该token,
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
12.1.4将ServiceAccount分配给pod
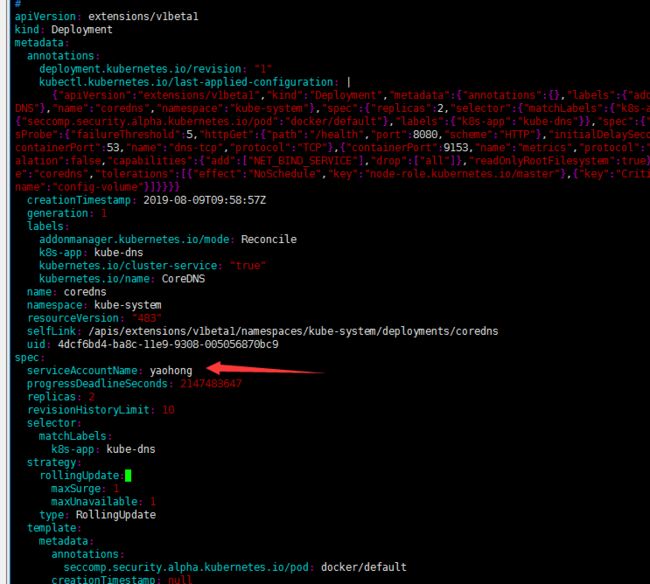
在pod中定义的spec.serviceAccountName字段上设置,此字段必须在pod创建时设置后续不能被修改。
自定义pod的ServiceAccount的方法如下图
回到顶部
12.2通过基于角色的权限控制加强集群安全
12.2.1.介绍RBAC授权插件
RBAC授权插件将用户角色作为决定用户能否执行操作的关机因素。
12.2.2介绍RBAC授权资源
RBAC授权规则通过四种资源来进行配置的,他们可以分为两组:
Role和ClusterRole,他们决定资源上可执行哪些动词。
RoleBinding和ClusterRoleBinding,他们将上述角色绑定到特定的用户,组或者ServiceAccounts上。
Role和RoleBinding是namespace级别资源
ClusterRole和ClusterRoleBinding是集群级别资源
12.2.3使用Role和RoleBinding
Role资源定义了哪些操作可以在哪些资源上执行,
创建Role
service-reader.yml
| 1 2 3 4 5 6 7 8 9 |
|
在kube-system中创建Role
| 1 |
|
查看该namespace下的role
| 1 2 3 4 5 6 7 8 9 10 |
|
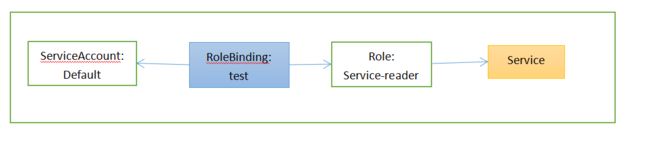
绑定角色到ServiceAccount
将service-reader角色绑定到default ServiceAccount
| 1 2 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
12.2.4使用ClusterRole和ClusterRoleBinding
查看集群ClusterRole
| 1 2 3 4 5 6 7 8 9 |
|
创建ClusterRole
| 1 |
|
查看yaml文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
创建clusterRoleBinding
| 1 2 |
|

12.2.5了解默认的ClusterRole和ClusterRoleBinding
如下所示使用kubectl get clusterroles和kubectl get clusterrolesbinding可以获取k8s默认资源。
用edit ClusterRole允许对资源进行修改
用admin ClusterRole赋予一个命名空间全部的权限
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
13.Kubernetes-保障集群内节点和网络安全
回到顶部
13.1.在pod中使用宿主节点的Linux命名空间
13.1.1.在pod中使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.hostNetwork: true
这个时候pod使用宿主机的网络,如果设置了端口,则使用宿主机的端口。
| 1 2 3 4 5 6 7 8 9 |
|
13.1.2.绑定宿主节点上的端口而不使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.containers.ports字段来设置
在ports字段中可以使用
containerPorts设置通过pod 的ip访问的端口
container.hostPort设置通过所在节点的端口访问
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
13.1.3.使用宿主节点的PID与IPC
PID是进程ID,PPID是父进程ID。
在linux下的多个进程间的通信机制叫做IPC(Inter-Process Communication),它是多个进程之间相互沟通的一种方法。
| 1 2 3 4 5 6 7 8 9 10 11 |
|
回到顶部
13.2.配置节点的安全上下文
13.2.1.使用指定用户运行容器
查看某个pod运行的用户
| 1 2 |
|
容器的运行用户再DockerFile中指定,如果没有指定则为root
指定pod的运行的用户方法如下
| 1 2 3 4 5 6 7 8 9 10 11 |
|
13.2.2.阻止容器以root用户运行
runAsNonRoot来设置
| 1 2 3 4 5 6 7 8 9 10 11 |
|
13.2.3.使用特权模式运行pod
为了获得宿主机内核完整的权限,该pod需要在特权模式下运行。需要添加privileged参数为true。
| 1 2 3 4 5 6 7 8 9 10 11 |
|
13.2.4.为容器单独添加内核功能
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
13.2.5.在容器中禁止使用内核功能
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
13.2.6.阻止对容器根文件系统的写入
securityContext.readyOnlyFilesystem设置为true来实现阻止对容器根文件系统的写入。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
回到顶部
13.3.限制pod使用安全相关的特性
13.3.1.PodSecurityPolicy资源介绍
PodSecurityPolicy是一种集群级别(无命名空间)的资源,它定义了用户能否在pod中使用各种安全相关的特性。
13.3.2.了解runAsUser、fsGroups和supplementalGroup策略
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
13.3.3.配置允许、默认添加、禁止使用的内核功能
三个字段会影响容器的使用
allowedCapabilities:指定容器可以添加的内核功能
defaultAddCapabilities:为所有容器添加的内核功能
requiredDropCapabilities:禁止容器中的内核功能
| 1 2 3 4 5 6 7 8 9 |
|
回到顶部
13.4.隔离pod网络
13.4.1.在一个命名空间中使用网络隔离
podSelector进行对一个命名空间下的pod进行隔离
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
13.4.2.在 不同的kubernetes命名空间之间进行网络隔离
namespaceSelector进行对不同命名空间间进行网络隔离
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
13.4.3.使用CIDR网络隔离
| 1 2 3 4 |
|
13.4.4.限制pod对外访问流量
使用egress进行限制
| 1 2 3 4 5 6 7 8 9 |
|