TensorRT8+C++接口+Window10+VS2019中的使用-模型准备及其调用以及图像测试
文章目录
- 前言
- 一、如何制作tensorRT需要的uff、onnx、trt文件
-
- 1.1 keras生成的h5
- 1.2 h5转pb
- 1.3 pb转uff
-
- 1.3.1 下载你的tensorRT
- 1.3.2 解压到纯英文路径,和opencv库一个用法
- 1.3.3 在pycharm里用pip将需要的whl安装上
- 1.3.4 执行uff自带的转换脚本convert_to_uff.py
- 1.3.5 遇到的问题
- 1.3.6 成功结果
- 1.4 h5转onnx并转onnx简化版
- 1.5 onnx简化版转trt格式
- 二、使用步骤
-
- 2.1 环境配置
-
- 2.1.1 Visual Studio项目目录配置-TensorRT
-
- 2.1.1.1 VC++目录
- 2.1.1.2 C/C++
- 2.1.1.3 链接器配置:
- 2.1.2 Visual Studio项目目录配置-CUDA
-
- 2.1.2.1 VC++目录
- 2.1.2.2 C/C++
- 2.1.2.3 链接器配置:
- 2.2 简单测试
-
- 2.2.1 调试TensorRT程序,报“重写虚函数的限制性异常规范比基类虚成员函数少”的错误
- 2.2.2 引入库文件
- 2.2.3 加载引擎并测试图像
- 总结
前言
由于tensorflow-gpu在C++ vs2019 window环境下,调用此前的pb文件,识别速度大概是450ms。完全达不到我想要达到的预期速度。
为了尝试更快的识别效果,经过学习发现tensorRT可以达成我的目的。
因此,在此前代码的基础上,计划使用tensorRT来调用pb文件完成图像的识别。看看速度是否会有明显的提升。
后来,发现pb文件没法直接被调用,改成调用uff文件。结果uff文件生成以后,通过tensorRT调用还是失败,无法加载进去,引擎返回值就是null。没办法,开始考虑用onnx格式。
当用onnx格式的时候,又发现这个东西一般是pytorch使用。如果想用需要转换。那么就尝试去转换。发现onnx想转换很麻烦,对python版本,protobuf的一个解释器的版本都有要求。最终千辛万苦从h5转换成了onnx,结果发现这个玩意在vs2019的tensorRT中能识别了,但是引擎返回值还是null。以为是结构太复杂了,弄了个onnx-simplified,结果还是不行。
最终,想着反正到了tensorRT里面也是要转换成引擎,还不如直接通过tensorRT的自带的trtexec,直接将onnx转换成.engin或者.trt格式。到时候直接通过C++里的引擎一调用,是不是就行了。
经过踩了个坑,onnx复杂版转换不过去,换成了onnx-simplified转换过的版本就可以了。
请观看本文的朋友们,先看完上边这一段经历。不要盲目的直接跟着做。。。中间都是弯路。。。
总结一下就是:
keras训练-h5模型-onnx模型-onnx简化版模型-trt引擎模型-被C++的tensorRT调用的流程。
最终效果:
7ms就可以用同样的模型(resnet50为基础的一个改造模型)识别出来。
一、如何制作tensorRT需要的uff、onnx、trt文件
1.1 keras生成的h5
我用的ResNet50改了一下输入和输出层参数,别直接抄哈。
# 训练模型
def train_resnet50_128_128_1_model(class_type_get, h5_data_path, pb_model_path, save_flag=True):
# 初始化resnet50
model = ResNet50(input_shape=(128, 128, 1), classes=class_type_get)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 加载数据集
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset(h5_data_path)
# 归一化图像向量
X_train = X_train_orig / 255.
X_test = X_test_orig / 255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, class_type_get).T
Y_test = convert_to_one_hot(Y_test_orig, class_type_get).T
# 训练模型
model.fit(X_train, Y_train, epochs=200, batch_size=8) # 默认迭代次数为20 修改为50
# 验证模型精度
preds = model.evaluate(X_test, Y_test)
if save_flag:
# 保存模型
mp = pb_model_path + '.h5'
model.save(pb_model_path) # 存为tf默认模型格式
model.save(mp) # 存为h5
return model, preds[0], preds[1]
1.2 h5转pb
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
def h5_2_pb(h5_save_path):
model = tf.keras.models.load_model(h5_save_path, compile=False)
model.summary()
full_model = tf.function(lambda Input: model(Input))
full_model = full_model.get_concrete_function(tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
# Save frozen graph from frozen ConcreteFunction to hard drive
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="./pb",
name="model.pb",
as_text=False) # 可设置.pb存储路径
h5_2_pb('yourmodel.h5') # 此处填入.h5路径
1.3 pb转uff
1.3.1 下载你的tensorRT
从下载链接下载你需要的tensorRT。
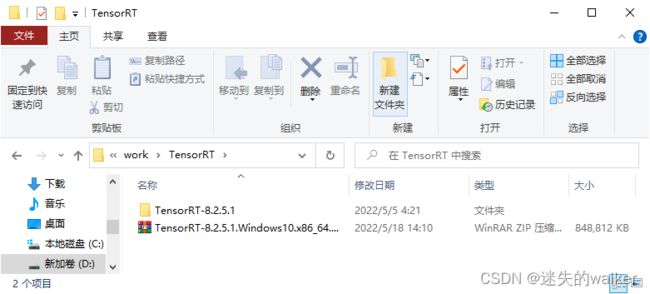
1.3.2 解压到纯英文路径,和opencv库一个用法
1.3.3 在pycharm里用pip将需要的whl安装上
分别是:uff和graphsurgeon
pip3 install .\uff-0.6.9-py2.py3-none-any.whl
pip3 install .\graphsurgeon-0.4.5-py2.py3-none-any.whl
1.3.4 执行uff自带的转换脚本convert_to_uff.py
python .\convert_to_uff.py .\pb\model.pb
1.3.5 遇到的问题
报错:AttributeError: module ‘tensorflow’ has no attribute ‘XXX’
遇到了这个问题,经过在csdn上查询,其实就是原来的代码是基于tensorflow1.x写的,而你用的是tensorflow2.x或者相比之前版本有了变化。发现有两位解决的比较好:
1.竹叶青的原文
他解决了在tensorflow2.x 下报错:
in from_tensorflow_frozen_model
with tf.gfile.GFile(frozen_file, “rb”) as frozen_pb: AttributeError: module ‘tensorflow’ has no attribute ‘gfile’
解决方法:
# graphdef = GraphDef()
# with tf.gfile.GFile(frozen_file, "rb") as frozen_pb:
# graphdef.ParseFromString(frozen_pb.read())
# return from_tensorflow(graphdef, output_nodes, preprocessor, **kwargs)
graphdef = GraphDef()
with tf.compat.v1.gfile.GFile(frozen_file, "rb") as frozen_pb:
graphdef.ParseFromString(frozen_pb.read())
return from_tensorflow(graphdef, output_nodes, preprocessor, **kwargs)
把上面注释的改为了下面的内容。再次运行。
2.后面又遇到类似的问题,最终找到了另一个哥们写的终极解法:
基本所有的module ‘tensorflow’ has no attribute 'xxx’都是由于tensorflow版本原因导致的,以上解决方法是可以推广到类似问题的,一般在出现问题的函数所在的代码行的tf后直接添加.compat.v1也可以运行成功。
例子如下:
saver = tf.train.Saver(dict(self.weights, **self.biases))
这种情况下,应该改为
saver = tf.compat.v1.train.Saver(dict(self.weights, **self.biases))
原文出处
1.3.6 成功结果
在pb文件目录下,生成了一个同样名字的.uff文件。
(最后试了,确实生成了,但是通过tensorRT导入后,没法正常读入模型,如果你能正常读入,那么恭喜,后面不用看了。如果不行的话,还有onnx试一试,如果还不行,再试试简化版,如果还不行,试试trt直接读入。反正不同的格式,理论上tensorRT都能读,可惜我一路踩坑一路失败。)
1.4 h5转onnx并转onnx简化版
我的环境是python3.9.0其他的都是下的最新的,比如tensorflow,tf2onnx,onnx,onnx-simplifier这些东西。如果有我没提到的,你就pip一下或者用pycharm配一下。我一开始用的python3.10结果没法下载安装onnx相关的所有东西,也不知道因为啥。后面查了查好像和protobuf版本有关系,反正在3.9的时候,protobuf版本不够新也会出现没法正常转换的情况。你们如果遇到问题了,嗯,也正常。不好用的话,记得在评论区说一下,然后让别的大佬教一教,我是菜鸡。
# 读取h5模型转换为onnx模型
import tensorflow as tf
import tf2onnx
import onnx
from onnxsim import simplify
# 读取h5模型
model = tf.keras.models.load_model("./pb/model.h5")
# 定义模型转onnx的参数
spec = (tf.TensorSpec((None, 128, 128, 1), tf.float32, name="Input"),)
output_path = model.name + "_o.onnx" # 输出路径
# 转换并保存onnx模型,opset决定选用的算子集合
model_proto, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13, output_path=output_path)
output_names = [n.name for n in model_proto.graph.output]
print(output_names) # 查看输出名称,后面C++推理用的到 也就是要知道你的模型的输入输出名字
# 加载生成的onnx模型
model_onnx = onnx.load(output_path)
onnx.checker.check_model(model_onnx)
onnx.save(model_onnx, 'out.onnx')
# 简化onnx模型
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, 'out_simplified.onnx')
1.5 onnx简化版转trt格式
- 找到你安装的TensorRT目录,比如我的是D:\work\TensorRT\TensorRT-8.2.5.1\
- 找到里面的trtexec工程,比如我的是D:\work\TensorRT\TensorRT-8.2.5.1\samples\trtexec
- 打开trtexec.sln项目,先看看能不能直接运行,不行的话就配置一下环境,看第二章
- 运行完成后,在TensorRT目录下的bin目录下会生成trtexec.exe程序,比如我的就在:D:\work\TensorRT\TensorRT-8.2.5.1\bin\trtexec.exe
- 打开cmd或者pycharm的终端到此路径,我的是D:\work\TensorRT\TensorRT-8.2.5.1\bin\
- 执行:
trtexec --onnx=youronnxname.onnx --saveEngine=yourtrtname.trt --workspace=4096 --fp16 --verbose --plugins=ScatterND.so - 如果一切顺利,那么就完成了,你能看到同目录下会有一个trt文件。
- 如果不顺利,那么我相信凭你聪明的头脑也能解决,毕竟踩坑才有意思。
二、使用步骤
2.1 环境配置
建议在visual studio里新建个属性页,未来好多项目使用
2.1.1 Visual Studio项目目录配置-TensorRT
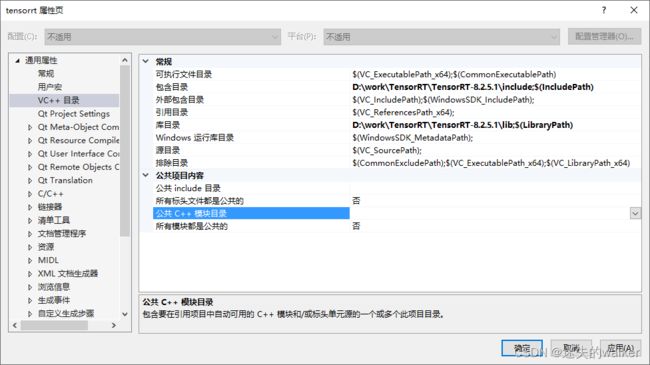
2.1.1.1 VC++目录
包含目录添加:D:\work\TensorRT\TensorRT-8.2.5.1\include
库目录添加:D:\work\TensorRT\TensorRT-8.2.5.1\lib
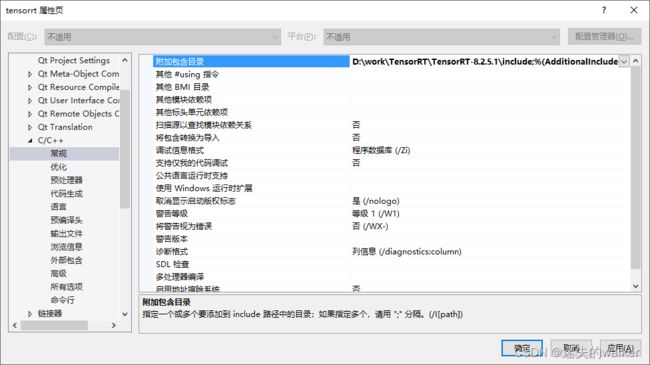
2.1.1.2 C/C++
附加包含目录:D:\work\TensorRT\TensorRT-8.2.5.1\include
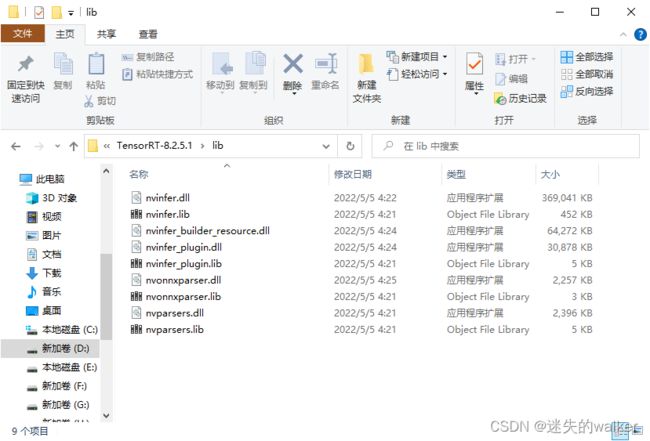
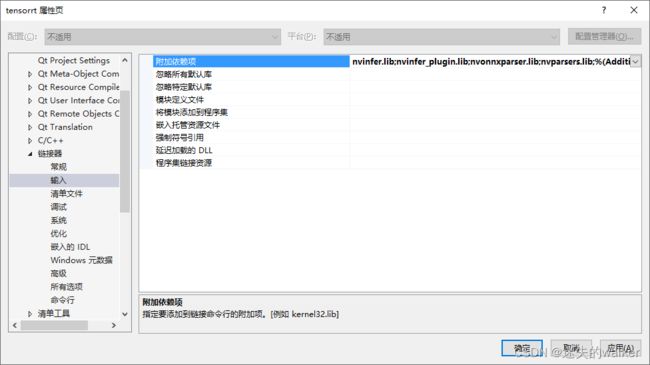
2.1.1.3 链接器配置:
-输入:
–附加依赖项:
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
2.1.2 Visual Studio项目目录配置-CUDA
由于网上都是这样读图存储调用的,我也就入乡随俗了。
前提是你装了cuda,cudnn这些东西,怎么装可以看我其他几个文章。
装好以后,开始仿照上面那个,配置cuda的环境。也可以另起一个props环境配置。
这个不装后面的测试代码肯定跑不通,毕竟要用到cuda往显存里放东西。
2.1.2.1 VC++目录
包含目录添加:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include
库目录添加:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\x64
你按你自己的写,别就直接抄,这个就不多说了。
2.1.2.2 C/C++
附加包含目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include
2.1.2.3 链接器配置:
-输入:
–附加依赖项:
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart_static.lib
cudart.lib
cudnn_adv_infer.lib
cudnn_adv_infer64_8.lib
cudnn_adv_train.lib
cudnn_adv_train64_8.lib
cudnn_cnn_infer.lib
cudnn_cnn_infer64_8.lib
cudnn_cnn_train.lib
cudnn_cnn_train64_8.lib
cudnn_ops_infer.lib
cudnn_ops_infer64_8.lib
cudnn_ops_train.lib
cudnn_ops_train64_8.lib
cudnn.lib
cudnn64_8.lib
cufft.lib
cufftw.lib
cufilt.lib
curand.lib
cusolver.lib
cusolverMg.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvjpeg.lib
nvml.lib
nvptxcompiler_static.lib
nvrtc.lib
OpenCL.lib
2.2 简单测试
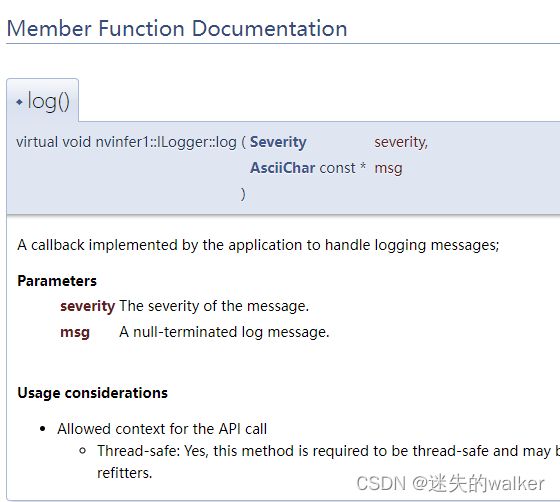
2.2.1 调试TensorRT程序,报“重写虚函数的限制性异常规范比基类虚成员函数少”的错误
报错:严重性 代码 说明 项目 文件 行 禁止显示状态
错误 C2694 “void Logger::log(nvinfer1::ILogger::Severity,const char *)”: 重写虚函数的限制性异常规范比基类虚成员函数“void nvinfer1::ILogger::log(nvinfer1::ILogger::Severity,const nvinfer1::AsciiChar *) noexcept”少
//实例化 ILogger 接口
class Logger : public ILogger
{
//void log(Severity severity, const char* msg) override
void log(Severity severity, const AsciiChar const* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
qDebug() << "kWARNING" << msg;
if (severity <= Severity::kVERBOSE)
qDebug() << "kVERBOSE" << msg;
}
}logger;
将void log(Severity severity, const char* msg) override改为void log(Severity severity, AsciiChar const* msg) noexcept override
主要原因就是版本问题吧,tensorflow和tensorRT的版本问题。
参考博客传送门
2.2.2 引入库文件
#include "NvOnnxParser.h"
#include "NvInfer.h"
#include 2.2.3 加载引擎并测试图像
我读入的是灰度图,识别模型也改过了,你们自己是什么就怎么弄。输入输出是多少就写多少。
我用的是qt环境,里面一些q开头的,你用了发现报错就删掉或者换成你喜欢的就行了,我懒得改了。
// 加载引擎文件
std::string engine_name = "yourtrtname.trt";
std::ifstream file(engine_name, std::ios::binary);
if (!file.good())
std::cerr << "文件无法打开,请确定文件是否可用!" << std::endl;
size_t size = 0;
file.seekg(0, file.end); // 将读指针从文件末尾开始移动0个字节
size = file.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file.seekg(0, file.beg); // 将读指针从文件开头开始移动0个字节
char* modelStream = new char[size];
file.read(modelStream, size);
file.close();
// 创建引擎对象
IRuntime* runtime = createInferRuntime(logger);
ICudaEngine* engine = runtime->deserializeCudaEngine(modelStream, size);
if (!engine)
{
qDebug() << "config Failure";
}
else
{
// Prepare input_data
int32_t inputIndex = engine->getBindingIndex("Input");//你的网络模型输入名称
int32_t outputIndex = engine->getBindingIndex("Output"); //你的输出名称,前面的输出用上了
cv::Mat input_mat = cv::imread("./pb/input/img512.jpg", cv::IMREAD_GRAYSCALE);
std::vector<float> input(128 * 128, 1.0); //输入图像是128 * 128的图
cv::resize(input_mat, input_mat, cv::Size(128, 128)); //需要和训练模型时图像resize大小保持一致
input_mat.convertTo(input_mat, CV_32F);
input_mat /= 255.0;
input = convertMat2Vector(input_mat);
std::vector<float> output(1 * 5, 1.0);//1* 5一般就是分5类
void* GPU_input_Buffer_ptr; // a host ptr point to a GPU buffer
void* GPU_output_Buffer_ptr; // a host ptr point to a GPU buffer
cudaMalloc(&GPU_input_Buffer_ptr, sizeof(float) * 128 * 128); //malloc gpu buffer for input
cudaMalloc(&GPU_output_Buffer_ptr, sizeof(float) * 1 * 5); //malloc gpu buffer for output
cudaMemcpy(GPU_input_Buffer_ptr, input.data(), input.size() * sizeof(float), cudaMemcpyHostToDevice); // copy input data from cpu to gpu
//设置一个缓冲区数组,指向 GPU 上的输入和输出缓冲区
void* buffers[2];
buffers[inputIndex] = static_cast<void*>(GPU_input_Buffer_ptr);
buffers[outputIndex] = static_cast<void*>(GPU_output_Buffer_ptr);
// Performing Inference 管理中间激活的额外状态
QTime start_time = QTime::currentTime();
IExecutionContext* context = engine->createExecutionContext();
context->executeV2(buffers);
// copy result data from gpu to cpu
cudaMemcpy(output.data(), GPU_output_Buffer_ptr, output.size() * sizeof(float), cudaMemcpyDeviceToHost);
QTime end_time = QTime::currentTime();
int time_gap = start_time.msecsTo(end_time);
// display output
qDebug() << "output is :";
for (auto i : output)
qDebug() << i << " ";
double minValue, maxValue;
cv::Point minLoc, maxLoc;
minMaxLoc(output, &minValue, &maxValue, &minLoc, &maxLoc);
qDebug() << QString::fromLocal8Bit("所属类别") << maxLoc.x;
qDebug() << QString::fromLocal8Bit("置信值") << maxValue;
qDebug() << QString::fromLocal8Bit("识别耗时") << time_gap << QString::fromLocal8Bit("ms");
// 释放资源和空间
runtime->destroy();
cudaFree(buffers[inputIndex]);
cudaFree(buffers[outputIndex]);
}
delete[] modelStream;
总结
请观看本文的朋友们,先看完前言所述经历。不要盲目的直接跟着做。。。中间都是弯路。。。
总结一下就是:
keras训练-h5模型-onnx模型-onnx简化版模型-trt引擎模型-被C++的tensorRT调用的流程。
最终效果:
7ms就可以用同样的模型(resnet50为基础的一个改造模型)识别出来