9.23 深度学习微调
- 深度学习中最重要的一个技术
标注一个数据集很贵
- ImageNet 标注了一千多万张图片,但是实际使用的只有 120 万张图片,类别数是 1000 ,它算是一个比较大的数据集
- Fashion-MNIST 一共有 6 万张图片,类别数是 10 , 算是一个比较小的数据集
- 通常自己的数据集规模通常在这两者之间,大概在 5 万张图片左右,类别数大概是 100 左右,平均下来每一类物体大概有 500 张图片左右
适合 ImageNet 的复杂模型可能会在自己的数据集上过拟合,另外由于训练样本有限,训练模型的准确性可能无法满足实际要求,解决以上问题有两种解决方案:
1、收集更多的数据。数据集越大越好,但是收集和标记数据可能需要大量的时间和金钱。
2、应用迁移学习(transfer leanring)。将从源数据集学到的知识迁移到目标数据集,通常来说希望在大数据集上训练好的模型能够提取到更通用的图像特征,有助于识别边缘、纹理、形状和对象组合,从而帮助提升在自己数据集上的精度,核心思想是假设模型对整个物体识别有一定的基础的情况下,不需要自己提供太大的数据集就能够获得很好的识别精度,这也是人工智能所追求的目标
网络架构
一个神经网络一般可以分为两块,一部分做特征提取,一部分做线性分类
- 假设将一张图像输入到模型中,可以认为最下面的一部分是在进行特征提取(特征抽取就是将原始像素变成容易线性分割的特征,深度学习的突破性进展就在于特征提取是可以学习的,而不用人工思考如何提供特征)
- 最后一部分就是一个全连接层和 softmax 来进行分类(可以认为是一个简单的线性分类器:Softmax 回归)

微调

- 假设在源数据集(一个比较大的数据集)上已经训练好了一个模型,模型中特征提取的部分对源数据集是有效的,那么它对目标数据集也应该是有效的,这样做是优于随机生成提取特征的
- 最后一部分是不能直接使用的,因为标号发生了改变,所以最后一部分难以进行重用
- 微调的核心思想是:在一个比较大的源数据集上训练好的模型中用于特征提取的部分,在目标数据集上提取特征时进行重用
微调中的权重初始化
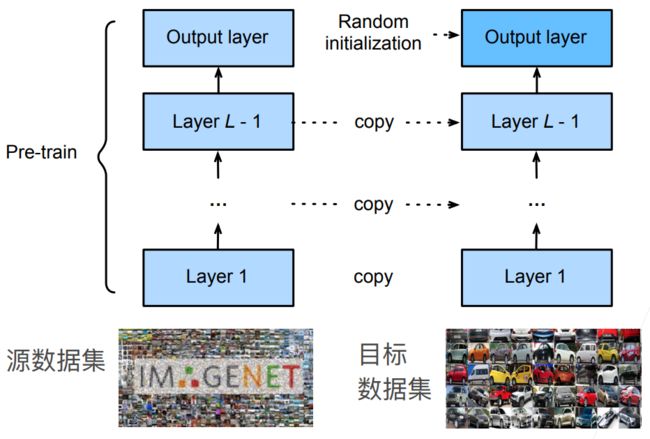
微调包括四个步骤:
- 在源数据集(例如 ImageNet 数据集)上预训练神经网络模型,即源模型(pre-train model)
- 创建一个新的神经网络模型,即目标模型。新模型的初始化不再是随机的初始化,而是复制源模型上的所有模型设计及其参数(输出层除外)。假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集,使得新模型在一开始就能很好地提取特征;同时假设源模型的输出层与源数据集的标签密切相关,因此不在目标模型中使用该层
- 向目标模型添加输出层,其输出数是目标数据集中的类别数,然后随机初始化该层的模型参数(最后的分类部分由于标号不同,因此还是做随机初始化)
- 在目标数据集上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调
- 因为损失 Loss 是从后往前进行传递的,所以最后的分类部分训练比较快,进行随机初始化也不会有太大的影响;而前面的特征提取的部分本身已经具备很好的特征提取效果,只是根据源数据集和目标数据集的差异进行微调,可能在最开始训练的时候就已经比较接近最终的结果,所以不用做过多的训练和变动
训练
是一个目标数据集上的正常训练任务,但使用更强的正则化(如果不使用预训练模型,直接在自己的数据集上正常训练,在时间足够的情况下也是可以从随机初始化训练到完全 fitting 自己的数据集,但是可能会导致 Overfitting ,这是没有必要的,不如对预训练模型进行微调)
- 使用更小的学习率(已经比较接近最优解了,因此不需要太大的学习率)
- 使用更少的数据迭代
源数据集远远复杂于目标数据集,通常微调的效果更好
- 源数据集的类别数、图片数量、样本个数通常是目标数据集的 10 倍或者 100 倍,才能达到很好的微调效果,否则微调的效果不如直接在目标数据集上进行重新训练
重用分类器权重
- 源数据集中可能也有目标数据中的标号
- 可以使用预训练好的模型分类器中对应标号对应的向量来做初始化
固定一些层
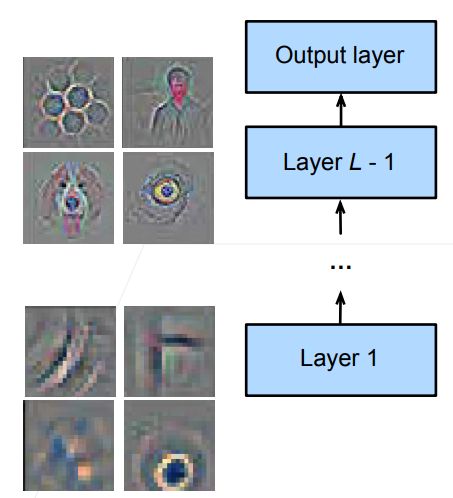
神经网络通常学习有层次的特征表示
- 低层次的特征更加通用(越低层次学习的是一些底层的细节)
- 高层次的特征则更跟数据集相关(越高层次则更加语义化)
- 可以认为越到后面和标号的关联度越大,约到前面则越低层,所以底层的特征更加通用,高层的特征和数据的关联度更大
可以固定底部一些层的参数,不参与更新(不做优化,在微调的时候不改变底层类别的权重,因为这些参数不再发生变化,所以模型的复杂度变低了,可以认为是更强的正则的效果)
- 更强的正则
通常来说,假设数据集很小,直接训练很容易过拟合的情况下,可以固定底部的一些参数不参与更新
总结
1、微调通过使用在大数据上得到的预训练好的模型来初始化目标数据集上的模型权重来完成提升精度
2、预训练模型质量很重要
3、微调通常速度更快,精度更高(可以借助在大数据集上所获得的先验知识)
4、建议尽量从微调开始训练,不要直接从目标数据集上从零开始进行训练
- 未来从原始数据集上进行训练的会越来越少,主要是学术界或者大公司在很大的数据集上进行重新训练
- 对于个人或者实际应用来讲,通常是使用微调
5、迁移学习将从源数据集中学到的知识“迁移”到目标数据集,微调迁移学习的常见技巧
6、除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调,但是目标模型的输出层需要从头开始训练
7、通常微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率
代码:
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir,'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir,'test'))
# 图片的大小和纵横比各有不同
hotdogs = [train_imgs[i][0] for i in range(8)]
print(train_imgs[0]) # 图片和标签,合为一个元组
print(train_imgs[0][0]) # 元组第一个元素为图片
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)
# 定义和初始化模型
pretrained_net = torchvision.models.resnet18(pretrained=True) # 把模型和在ImageNet上定义好的参数拿过来
pretrained_net.fc # full connection全连接层,最后一层,查看最后一层的输入和输出结构
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features,2) # 最后一层修改为输出类别数为2
nn.init.xavier_uniform_(finetune_net.fc.weight) # 只对最后一层的weight做随即初始化
# 微调座位
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5, param_group=True):
train_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir,'train'),transform=train_augs),
batch_size = batch_size,shuffle=True)
test_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir,'test'),transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
# 除了最后一层的learning rate外,用的是默认的learning rate
# 最后一层的learning rate用的是十倍的learning rate
params_lx = [
param for name, param in net.named_parameters()
if name not in ["fc.weight","fc.bias"] ]
trainer = torch.optim.SGD([
{'params': params_lx},
{'params': net.fc.parameters(), 'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(),lr=learning_rate,weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
# 使用较小的学习率
train_fine_tuning(finetune_net,6e-6) 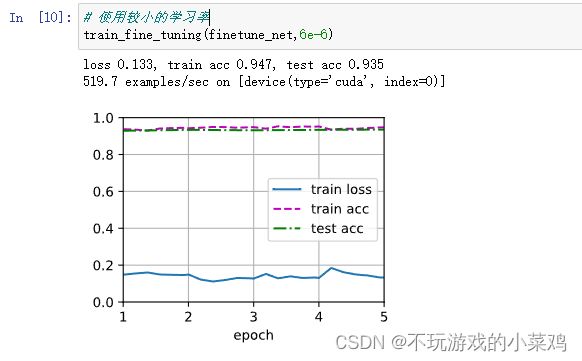
# 为了进行比较,所有模型参数初始化为随机值
scratch_net = torchvision.models.resnet18() # 这里没有pretrained=True,没有拿预训练的参数
scratch_net.fc = nn.Linear(scratch_net.fc.in_features,2)
train_fine_tuning(scratch_net,5e-4,param_group=False) # param_group=False使得所有层的参数都为默认的学习率 