Datawhale - Hello Transformer
文章目录
- 模型结构概览
- 模型输入
- Encoder
- Decoder
- 代码
- 自己碰到的问题
李宏毅老师的transformer讲解的非常细致,可以看这个视频入门
模型结构概览
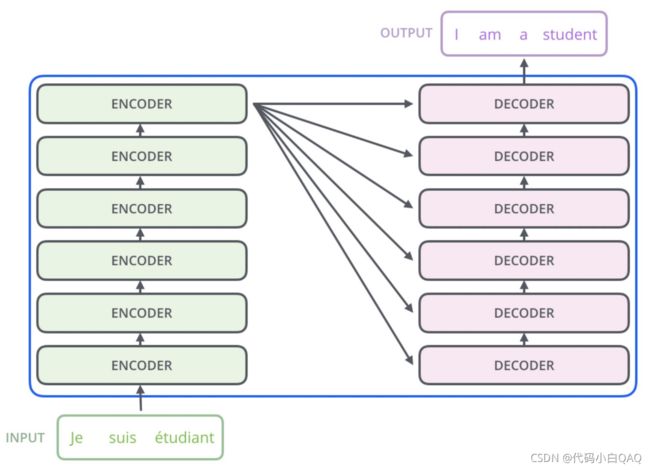

模型输入

Encoder
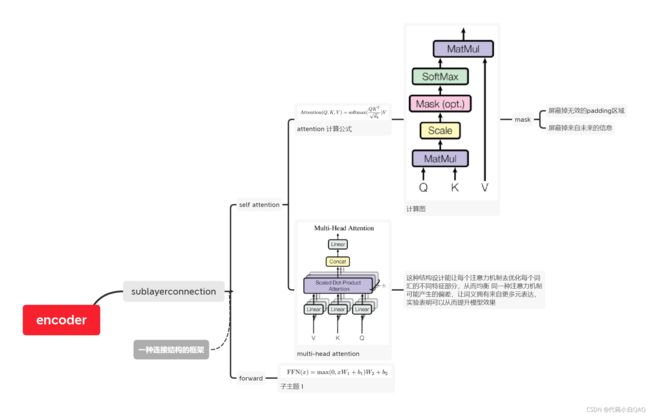
Decoder
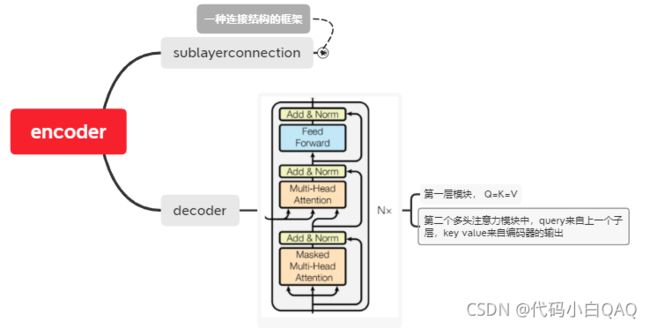
代码
# -*- coding: utf-8 -*-
"""
transformer 网络结构
@author: [email protected]
modified from a great tutorial: http://nlp.seas.harvard.edu/2018/04/03/attention.html
"""
import math
import copy
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
# Model Architecture
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture.
Base for this and many other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed # input embedding module(input embedding + positional encode)
self.tgt_embed = tgt_embed # ouput embedding module
self.generator = generator # output generation module
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
memory = self.encode(src, src_mask)
res = self.decode(memory, src_mask, tgt, tgt_mask)
return res
def encode(self, src, src_mask):
src_embedds = self.src_embed(src)
return self.encoder(src_embedds, src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
target_embedds = self.tgt_embed(tgt)
return self.decoder(target_embedds, memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"""
Encoder
The encoder is composed of a stack of N=6 identical layers.
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# We employ a residual connection around each of the two sub-layers, followed by layer normalization
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, feature_size, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(feature_size))
self.b_2 = nn.Parameter(torch.zeros(feature_size))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
实现子层连接结构的类
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
# 原paper的方案
#sublayer_out = sublayer(x)
#x_norm = self.norm(x + self.dropout(sublayer_out))
# 稍加调整的版本
sublayer_out = sublayer(x)
sublayer_out = self.dropout(sublayer_out)
x_norm = x + self.norm(sublayer_out)
return x_norm
class EncoderLayer(nn.Module):
"EncoderLayer is made up of two sublayer: self-attn and feed forward"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size # embedding's dimention of model, 默认512
def forward(self, x, mask):
# attention sub layer
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# feed forward sub layer
z = self.sublayer[1](x, self.feed_forward)
return z
# Decoder
# The decoder is also composed of a stack of N=6 identical layers.
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
# Attention
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
# Embeddings and Softmax
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
embedds = self.lut(x)
return embedds * math.sqrt(self.d_model) # TODO 这里的归一化操作的目的?
# Positional Encoding
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
"""
位置编码器类的初始化函数
共有三个参数,分别是
d_model:词嵌入维度
dropout: dropout触发比率
max_len:每个句子的最大长度
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings
# 注意下面代码的计算方式与公式中给出的是不同的,但是是等价的,你可以尝试简单推导证明一下。
# 这样计算是为了避免中间的数值计算结果超出float的范围,
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
# Full Model
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
构建模型
params:
src_vocab:
tgt_vocab:
N: 编码器和解码器堆叠基础模块的个数
d_model: 模型中embedding的size,默认512
d_ff: FeedForward Layer层中embedding的size,默认2048
h: MultiHeadAttention中多头的个数,必须被d_model整除
dropout:
"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
if __name__ == "__main__":
print("\n-----------------------")
print("test subsequect_mask")
temp_mask = subsequent_mask(4)
print(temp_mask)
print("\n-----------------------")
print("test build model")
tmp_model = make_model(10, 10, 2)
print(tmp_model)
自己碰到的问题
- register_buffer: 在内存中定一个常量,模型保存和加载的时候可以写入和读出。
- torch.unsqueeze: 对数据维度进行扩充
- 在代码里,self_attention层处理decoder的第二个multi-head attention层输入Q!=K=V之外,其他的Q=K=V. 但是在李宏毅的课程里, Q,K,V都是由输入X经过某个变换得到的。