银行贷款预测模型项目(Loan Prediction)(下)
在上篇中主要是数据预处理,在下篇继续建模部分笔记。
建立模型(Part I)
1. 数据集切分
将目标变量和其他数据变量分开。
###model
train = train.drop('Loan_ID',axis=1)
test=test.drop('Loan_ID',axis=1)
X=train.drop('Loan_Status',1)
y=train.Loan_Status
2. 虚拟变量(dummy variables)
虚拟变量(dummy variables)又叫名义变量或哑变量。 虚拟变量将分类变量转成一系列的0和1 ,使得特征更便于量化和比较。
例如,性别变量有两个类别:‘男性’和‘女性’。
因为逻辑回归职能处理数值,所以需要将‘男性’和‘女性’转换成数字。当我们将这些特征Dummy化,性别这个变量就会转换两个变量(“性别_男性“和“性别_女性”)。
当样本(申请人)为男性时:“性别_男性“=1 ;“性别_女性”=0。
#Turn Dummy variables for the categorical variables; Gender_Male= 0 if Feamel ,and 1 for male
X=pd.get_dummies(X)
train=pd.get_dummies(train)
test=pd.get_dummies(test)
部分结果如下图:

3. 验证(validation)
在建模过程中,我们有个训练集(Train)和一个测试集(Test)。
但是如何去验证这个模型是否准确呢?
一种方法是将训练集分成两组数据:训练集和验证集;
使用训练集去训练模型,再用验证集去验证模型的准确率。
这种方法在真实的样本结果上验证模型的预测结果是否准确。
Train有真实的结果Y,即loan Status, 但是测试集test没有结果,需要我们用模型去预测。
使用train_test_split()划分验证集。
from sklearn.model_selection import train_test_split
#import LogisticReression and accuracy_score from sklearn and fit the lofistic regression model
x_train, x_cv, y_train, y_cv = train_test_split(X,y, test_size =0.3)
4. 训练模型
## build model
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model = LogisticRegression()
model.fit(x_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=1, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)

模型训练好后,在验证集算出预测结果,并与验证集的结果比较算出准确率。
5. 计算准确率
#predict the Loan_status for validation set and calculate its accuracy
pred_cv = model.predict(x_cv)
#calculate how accurate our preditionsare by calculating the acuracy
accuracy_score(y_cv,pred_cv)

最后结果,模型的准确率有81%。
Part I 总结
这一部分建立了一个基础的模型,准确率为81%。但是只划分了一次数据,这个模型的结果是否可靠呢?另外,是否还有其他方法继续优化模型提高准确性呢?
下面,会继续使用分层交叉验证、特征工程以及其他模型算法进行建模。
分层交叉验证(stratified k-folds cross validation)
分层交叉验证,就是将上面的验证步骤重复多次。避免了只划分一次数据集,会导致结果具有偶然性。
下面是k=5时分层k-fold验证的示意图:将数据划分了五次,同样的训练和验证流程做5次,得到5个评估结果。

#Validation ...Stratified K Fold
from sklearn.model_selection import StratifiedKFold
# make a cross validation logistic model with stratified 5 folds and make predictions for test dataset
i = 1
kf = StratifiedKFold(n_splits=5, random_state=1, shuffle=True)
for train_index, test_index in kf.split(X, y):
print('\n{} of kfold {}'.format(i, kf.n_splits))
xtr, xvl = X.loc[train_index], X.loc[test_index]
ytr, yvl = y[train_index], y[test_index]
model = LogisticRegression(random_state=1)
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl, pred_test)
print('accuracy_score', score)
i += 1
pred_test = model.predict(test)
pred = model.predict_proba(xvl)[:, 1]

5个评估结果在0.788-0.83范围内,取平均值为0.8077702252432362;表明这个模型的准确度在80%左右。
特征工程
根据业务经验,我们可以构造几个可能影响到目标变量的新特征:
- 总收入,这个特征我们之前有讨论过的,将申请人和共同申请人的收入加总。
- EMI,是指申请人每月为偿还贷款而支付的金额。这个变量背后的想法是,有高贷款占比的人可能会发现很难偿还贷款。我们可以通过贷款金额与贷款金额期限的比率来计算EMI。
- 剩余收入,是每月还完贷款后剩余的收入。 高剩余收入的申请人更有可能获批贷款。
新特征一:总收入
#汇总收入
#构建特征
train['Total_Income']=train['ApplicantIncome']+train['CoapplicantIncome']
test['Total_Income']=test['ApplicantIncome']+test['CoapplicantIncome']
#直方图
sns.distplot(train['Total_Income'])
#对数变换
train['Total_Income_log'] = np.log(train['Total_Income'])
sns.distplot(train['Total_Income_log']);
test['Total_Income_log'] = np.log(test['Total_Income'])

经过对数变换的总收入,分布情况更接近正态分布。
新特征二:EMI(每月还款金额)
# EMI
train['EMI']=train['LoanAmount']/train['Loan_Amount_Term']
test['EMI']=test['LoanAmount']/test['Loan_Amount_Term']
#check the distribution of EMI variable.
sns.distplot(train['EMI']);

新特征二:Balance Income(剩余收入)
#Balance Income
train['Balance Income']=train['Total_Income']-(train['EMI']*1000)
# Multiply with 1000 to make the units equal test['Balance Income']=test['Total_Income']-(test['EMI']*1000)
sns.distplot(train['Balance Income']);
test['Balance Income']=test['Total_Income']-(test['EMI']*1000)
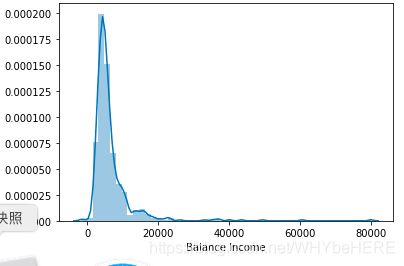
最后,删掉原来的变量,旧特征和新特征会高度相关,所以需要移除就特征降低噪音。
train=train.drop(['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term'], axis=1)
test=test.drop(['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term'], axis=1)
建立模型(Part II)
构建了新特征后,重新建立模型,这次使用更多更加复杂的模型:
- Logistic Regression
- Decision Tree
- Random Forest
- XGBoost
#prepare the data for feeding into the models.
X = train.drop('Loan_Status',1)
y = train.Loan_Status # Save target variable in separate dataset
Logistic Regression
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = LogisticRegression(random_state=1) ######
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)
pred=model.predict_proba(xvl)[:,1]

LR平均值是0.7214314274290283
Decision Tree
from sklearn import tree
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = tree.DecisionTreeClassifier(random_state=1)
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)

决策树平均值是0.7149140343862455
Random Forest
from sklearn.ensemble import RandomForestClassifier
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = RandomForestClassifier(random_state=1, max_depth=10)
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)

平均值是0.7947221111555378
Grid Search (网格搜索)
可以看到,三种模型的效果都不是很好,可以进一步使用grid search给随记森林模型调参。
这里选择用来调优的参数是:
max_depth:决定了树的深度
n_estimators:决定了随记森林里建立几棵树模型。
from sklearn.model_selection import GridSearchCV
# 设置max_depth 测试的区间是1-20,间隔是2;
# 设置n_estimators 测试的区间是1-200,间隔为20
paramgrid = {'max_depth': list(range(1, 20, 2)), 'n_estimators': list(range(1, 200, 20))}
grid_search=GridSearchCV(RandomForestClassifier(random_state=1),paramgrid)
from sklearn.model_selection import train_test_split
x_train, x_cv, y_train, y_cv = train_test_split(X,y, test_size =0.3, random_state=1)
# Fit the grid search model
grid_search.fit(x_train,y_train)
结果输出:

# 选择效果最好的
grid_search.best_estimator_

最新结果,最佳深度max_depth variable为5; n_estimator 是41.
将最佳的参数放入模型中:
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = RandomForestClassifier(random_state=1, max_depth=5, n_estimators=41) #is 5 and 41.
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)
pred2=model.predict_proba(test)[:,1]

随机森林模型的平均值是0.8012794882047182
Xgboost
from xgboost import XGBClassifier
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = XGBClassifier(n_estimators=41, max_depth=5)
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)
pred3=model.predict_proba(test)[:,1]

XGBoost平均数是0.7866320138611222
同样用Grid Search
#依旧用之前设置的参数paramgrid,这里不用重新设置
grid_search=GridSearchCV(XGBClassifier(random_state=1),paramgrid)
#训练模型
grid_search.fit(x_train,y_train)
#grid_search.best_estimator_

最佳参数:max_depth=1,n_estimators=81
i=1
kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
for train_index,test_index in kf.split(X,y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
xtr,xvl = X.loc[train_index],X.loc[test_index]
ytr,yvl = y[train_index],y[test_index]
model = XGBClassifier(n_estimators=81,max_depth=1) #max_depth=1,n_estimators=81
model.fit(xtr, ytr)
pred_test = model.predict(xvl)
score = accuracy_score(yvl,pred_test)
print('accuracy_score',score)
i+=1
pred_test = model.predict(test)
pred3=model.predict_proba(test)[:,1]

XGBoost平均准确值为0.806157536985206
总结
特征重要性feature_importances_
最后我们总结一下特征的重要程度:使用feature_importances_评估哪一个特征是最重要的。
importances=pd.Series(model.feature_importances_, index=X.columns)
importances.plot(kind='barh', figsize=(12,8))
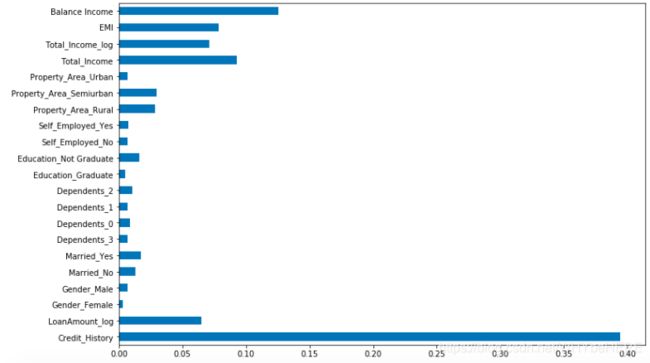
由图可见,信贷历史是最重要的特征,其次是剩余收入、总收入、EMI。
模型评估
各个模型的准确值如下:
- LR平均值是72%
- 决策树平均值是71%
- 随机森林模型的平均值是80%
- XGBoost平均数是81%(目前最佳)
参考链接:Loan Prediction Practice Problem