联邦学习中非独立同分布(No I.I.D.)几种情况
好久没有发文章了,之前发了一篇个性化联邦综述的内容,但是自己也没完全太理解几种非独立同分布情况,这篇文章重新探究了一下几种情况的区别,希望对大家有所帮助。
目录
前言
Dataset Shift
协变量偏移(Covariate Shift)
先验概率偏移(Prior Probability Shift)
概念偏移(Concept Shift):
联邦学习中的非独立同分布
Advances and Open Problems in Federated Learning
Towards Personalized Federated Learning
区别
Federated Learning on Non-IID Data Silos: An Experimental Study
总结
前言
在横向联邦学习中,终端设备往往是PC、手机以及各种LoT设备等,是无法保证获得的数据为独立同分布的,所以如何解决联邦学习中的非独立同分布情况变得十分重要,本文主要介绍了联邦学习中可能出现的几种非独立同分布情况
Dataset Shift
在介绍非独立同分布之前,我们需要先了解Dataset Shift的概念。
联邦学习中客户端之间Non-IID分布和我们在做机器学习任务时可能遇到的训练集与测试集分布不一致其实是一个道理(因为你可以把训练集想象成客户端1,测试集想象成客户端2)。
训练集和测试集分布不一致被称作数据集偏移(Dataset Shift)。西班牙格拉纳达大学Francisco Herrera教授在他PPT《Dataset Shift in Classification: Approaches and Problems》里提到数据集偏移有三种类型:
-
Covariate Shift 协变量偏移
-
Prior Probability Shift 先验概率偏移
-
Concept Shift 概念偏移
协变量偏移(Covariate Shift)
独立变量的偏移,指训练集和测试集的输入服从不同分布,但是服从同一个函数关系。

通俗的解释就是:训练集训练出一个模型,在测试集使用模型时效果不够好,因为测试集的协变量(x)分布与训练集不同,下面这两张图可以很直观的说明这一现象:

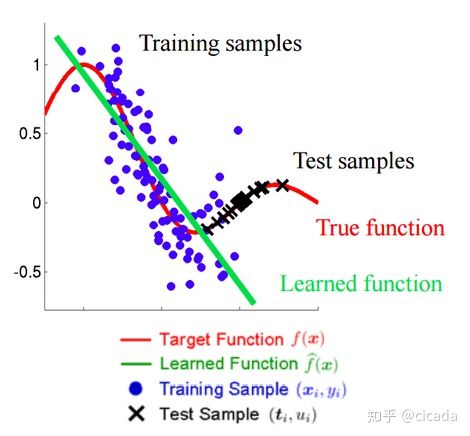
先验概率偏移(Prior Probability Shift)
目标变量的偏移。

举个例子来解释这种现象吧:
比如垃圾邮件的分类,很可能在实际场景中邮件样本绝大多数都是垃圾邮件,只有少部分不是垃圾邮件,但是我们的训练集的数据类别占比是50%,50%,这就形成了先验偏移问题。
概念偏移(Concept Shift):
独立变量和目标变量之间关系的偏移。

概念漂移是指目标变量(模型试图预测的内容)的统计特性随时间以不可预见的方式发生变化的情况。
举个例子:季节虽然没有在温度数据中被明确说明,但是可能会影响温度的数据。另一个例子,消费者购买行为随时间的变化可能是受经济增强所影响,但是经济增强并没有显示的在数据中说明。
可能不够直观,再举几个比较直观的:
-
突然漂移:一个新概念在短时间内出现(例如,在 2020 年 3 月 COVID-19 开始时,股价突然变化)。
-
逐渐漂移:一个新概念会在很长一段时间内逐渐取代旧概念(例如,您会看到越来越少的新石油公司和越来越多的新技术公司)。
-
增量漂移:旧概念在一段时间内逐渐变为新概念(例如,股票价格逐渐稳定上涨)
联邦学习中的非独立同分布
现在也有很多论文写了联邦学习中的非独立同分布,但是他们的分类也是有略微区别的,下面我们分别来看看他们是怎么区分的。
Advances and Open Problems in Federated Learning
最新在2021年修订,其中的第3章第1节, Non-IID Data in Federated Learning 介绍了联邦学习中的非独立同分布情况。

这篇文章介绍了五种no I.I.D.的情况:协变量偏移、先验概率偏移各一种,将概念漂移拆分成了两种情况,以及数据的数量倾斜共五种情况
1、Feature distribution skew 特征分布偏差(协变量偏移)
即使P(y|x)是共享的,边际分布Pi(x)可能因不同的客户而不同。
e.g. 在手写识别领域中,写相同单词的用户可能仍然有不同的笔画宽度、倾斜度等。
2、Lable distribution skew 标签分布偏差(先验概率偏移)
即使P(x|y)是相同的,边际分布Pi(y)也可能不同。
e.g. 当客户被绑定到特定的地理区域时,不同客户的标签分布也不同——袋鼠只在澳大利亚或动物园;一个人的脸只在世界上少数几个地方;对于移动设备键盘,某些表情符号被一个人使用,而不被其他人使用。
3、Same label, different features 相同的标签,不同的特征(概念漂移)
即使P(y)是共享的,条件分布Pi(x|y)也可能在不同的客户端之间有所不同。相同的标签y可以对不同的客户端有非常不同的特征x。
e.g. 由于文化差异、天气影响、生活水平等原因。例如,世界各地的家庭形象可能差别很大,服装的种类也差别很大。即使是在美国境内,冬天停放的汽车的照片也只会在美国的某些地区被雪覆盖。同样的标签在不同的时间和不同的时间尺度上也可能看起来非常不同:昼夜、季节影响、自然灾害、时尚和设计趋势等等。
4、Same features, different label 相同的特征,不同的标签 (概念漂移)
条件分布Pi(y|x)可能在不同的客户端之间有所不同,即使P(x)相同。由于个人偏好,训练数据项中相同的特征向量可以有不同的标签。
e.g. 例如,反映情绪或下一个词预测器的标签有个人和区域差异。
5、Quantity skew or unbalancedness 数量倾斜或不平衡
e.g. 不同的客户端可以拥有非常不同的数据量。
Towards Personalized Federated Learning
这篇文章主要是介绍当前个性化联邦的解决思路与方法,同时文章快结尾的时候介绍了他们对于非独立同分布的分类方法。分为4类:
1、Quantity Skew 数量倾斜:FL客户端持有不同大小的本地数据集,有些客户端比其他客户端的数据量要大得多。由于跨FL客户机的不同使用模式,数据大小的异构性在现实环境中普遍存在。
与上面的Quantity skew or unbalancedness 一样,没什么可说的。
2、Feature Distribution Skew 特征分布倾斜:特征分布在不同客户端之间有所不同,而条件分布P(y|x)在不同客户端之间是相同的。例如,在健康监测应用程序中,用户的活动数据的分布根据他们的习惯和生活方式模式而差异很大。
协变量偏移,与上面相同。举个新例子:
比如:不同人的字迹差异很大,但小明写的“联邦学习”和小红写的“联邦学习”都应该被识别为“联邦学习”。
3、Label Distribution Skew 标签分布倾斜:标签分布在不同客户端之间有所不同,而条件分布P(x|y)在不同客户端之间是相同的。例如,在软件移动键盘中,标签分布偏差对来自不同人口统计数据的用户来说可能是一个可能的问题,因为存在不同的语言和文化细微差别,导致某些单词或表情符号主要被不同的用户使用。
先验概率偏移,与上面相同。举个新例子:
比如:不同人认识的字的集合不一样,虽然字都是打印的楷体,但是小明认识“联邦学习”,小红只认识“学习”。
4、Label Preference Skew 标签偏好倾斜:条件分布Pc(x|y)在不同客户端之间有所不同,而标签分布P(y)在不同客户端之间是相同的。
跟上面提到的相同的标签,不同的特征相同。
举个例子:
人皆有爱美之心,假设现在有一个图像鉴别颜值的任务,标签都是“美”、“一般”两类,客户端A来自唐朝图像,客户端B来自楚国图像。当标签得结果是“美”时,客户端A会认为图像特征为“丰腴”,而客户端B认为图像特征为“细腰”。
区别
这篇文章与第一篇文章相比,缺少了概念漂移的一个分类, 只说了相同的标签,不同的特征;忽略了相同的特征,不同的标签这一种情况。
Federated Learning on Non-IID Data Silos: An Experimental Study
这篇论文也对非独立同分布进行了分类,同第一篇文章分类方式相同。
总结
结合几篇文章,我认为像第一篇文章一样,将非独立同分布分成五类比较合理。上面文章举的例子有的可能有点抽象,不便于理解,我尝试总结几个便于理解的例子,可以结合前面的例子一起理解。
| 非独立同分布分类 |
Dataset Shift 分类 |
例子 |
| Feature distribution skew 特征分布偏差 |
协变量偏移 |
不同人的字迹差异很大,但小明写的“联邦学习”和小红写的“联邦学习”都应该被识别为“联邦学习”。 |
| Lable distribution skew 标签分布偏差 |
先验概率偏移 |
不同人认识的字的集合不一样,虽然字都是打印的楷体,但是小明认识“联邦学习”,小红只认识“学习”。 |
| Same label, different features 相同的标签,不同的特征 |
概念偏移 |
人皆有爱美之心,假设现在有一个图像鉴别颜值的任务,标签都是“美”、“一般”两类,客户端A来自唐朝图像,客户端B来自楚国图像,客户端A会任务“美”指的是“丰腴”的图像,但是客户端B会认为“美”指的是“细腰”的图像。 |
| Same features, different label 相同的特征,不同的标签 |
概念偏移 |
人皆有爱美之心,假设现在有一个图像鉴别颜值的任务,标签都是“美”、“一般”两类,客户端A来自唐朝图像,客户端B来自楚国图像。客户端A会把“丰腴”的图像分类为“美”,但是客户端B会把“丰腴”的图像分类为“一般”,虽然两个客户端上面“丰腴”的图像分布很接近 |
| Quantity skew or unbalancedness 数量倾斜或不平衡 |
无 |
这个很简单 不同的客户端可以拥有非常不同的数据量。 |
有任何疑问,欢迎大家一起讨论。
参考文章:
联邦学习中常见的Clients数据Non-IID非独立同分布
Covariate Shift
机器学习中的概念漂移