使用python pipeline 实现FATE三方横向逻辑回归
本文是基于微众开发的FATE联邦学习平台,进行一个三方的横向逻辑回归实验。且使用pipeline进行流程搭建与模型训练,代替书写dsl和conf的json文件的方法,使得整个流程更加简洁、方便。
1 目标
- 测试三方(多方)联邦学习在FATE的可行性
- 尝试使用python pipeline 进行建模过程
2 准备工作
- 三个可以运行FATE的虚拟机 (不会配置的可以参考之前的文章)
- 主机中可以在jupyter上运行python代码
3 建模流程
附上官方给出的pipeline例子 :https://github.com/FederatedAI/FATE/tree/master/doc/tutorial/pipeline
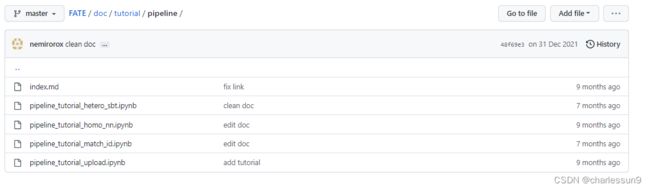 可以从图中看到,官方给出了两种上传数据的例子(其中一个包括添加sid),给了一个横向nn,纵向secureboost的例子 。
可以从图中看到,官方给出了两种上传数据的例子(其中一个包括添加sid),给了一个横向nn,纵向secureboost的例子 。
3.1 数据上传
我们这里面使用的是皮马印第安人糖尿病数据集,768条数据,200条一组分为3组,作为训练集,剩下的168条作为测试集。
这个实验中,我们设置的guest为9999,两个host,分别为10000和9998,arbiter为9999
所以上传后各服务器数据的name和namespace分别为
10000:
{"name": "diabetes_homo_host_a", "namespace": "diabetes_train"}
{"name": "diabetes_test_host_a", "namespace": "diabetes_test"}
9999:
{"name": "diabetes_homo_guest", "namespace": "diabetes_train"}
{"name": "diabetes_test_guest", "namespace": "diabetes_test"}
9998:
{"name": "diabetes_homo_host_b", "namespace": "diabetes_train"}
{"name": "diabetes_test_host_b", "namespace": "diabetes_test"}
3.2 建模(pipeline)
我们已经熟悉在虚拟机中用dsl和conf进行建模,现在我们在jupyter中用pipeline来操作。
首先是准备工作,环境配置:
注意ip地址为正常你用dsl和conf方式时的那台服务器。
!flow init --ip 192.168.73.162 --port 9380 这行代码都会提示successful,所以需要!flow table info -t breast_homo_host -n experiment去验证。
# 准备工作 环境配置
!pip install fate_client
!pipeline --help
!flow init --ip 192.168.73.162 --port 9380
!flow table info -t breast_homo_host -n experiment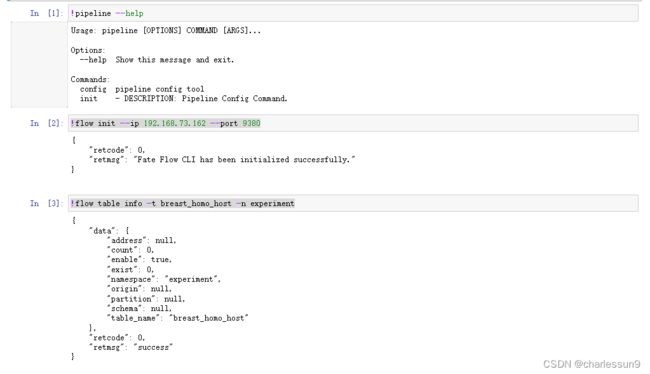
下面我把整个流程的代码都贴上,后面再一个个解释
from pipeline.backend.pipeline import PipeLine
from pipeline.component import DataTransform
from pipeline.component import Reader
from pipeline.component import FeatureScale
from pipeline.component import HomoNN,HomoLR
from pipeline.component import Evaluation
from pipeline.component.homo_secureboost import HomoSecureBoost
from pipeline.interface import Data, Model
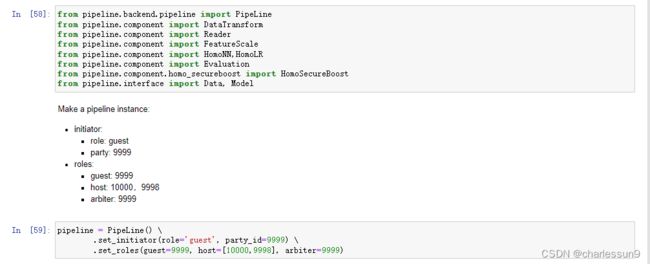
pipeline = PipeLine() \
.set_initiator(role='guest', party_id=9999) \
.set_roles(guest=9999, host=[10000,9998], arbiter=9999)
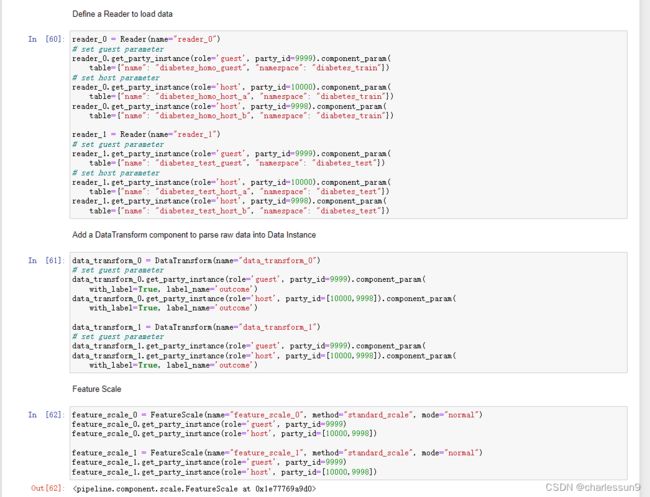
reader_0 = Reader(name="reader_0")
# set guest parameter
reader_0.get_party_instance(role='guest', party_id=9999).component_param(
table={"name": "diabetes_homo_guest", "namespace": "diabetes_train"})
# set host parameter
reader_0.get_party_instance(role='host', party_id=10000).component_param(
table={"name": "diabetes_homo_host_a", "namespace": "diabetes_train"})
reader_0.get_party_instance(role='host', party_id=9998).component_param(
table={"name": "diabetes_homo_host_b", "namespace": "diabetes_train"})
reader_1 = Reader(name="reader_1")
# set guest parameter
reader_1.get_party_instance(role='guest', party_id=9999).component_param(
table={"name": "diabetes_test_guest", "namespace": "diabetes_test"})
# set host parameter
reader_1.get_party_instance(role='host', party_id=10000).component_param(
table={"name": "diabetes_test_host_a", "namespace": "diabetes_test"})
reader_1.get_party_instance(role='host', party_id=9998).component_param(
table={"name": "diabetes_test_host_b", "namespace": "diabetes_test"})
data_transform_0 = DataTransform(name="data_transform_0")
# set guest parameter
data_transform_0.get_party_instance(role='guest', party_id=9999).component_param(
with_label=True, label_name='outcome')
data_transform_0.get_party_instance(role='host', party_id=[10000,9998]).component_param(
with_label=True, label_name='outcome')
data_transform_1 = DataTransform(name="data_transform_1")
# set guest parameter
data_transform_1.get_party_instance(role='guest', party_id=9999).component_param(
data_transform_1.get_party_instance(role='host', party_id=[10000,9998]).component_param(
with_label=True, label_name='outcome')
feature_scale_0 = FeatureScale(name="feature_scale_0", method="standard_scale", mode="normal")
feature_scale_0.get_party_instance(role='guest', party_id=9999)
feature_scale_0.get_party_instance(role='host', party_id=[10000,9998])
feature_scale_1 = FeatureScale(name="feature_scale_1", method="standard_scale", mode="normal")
feature_scale_1.get_party_instance(role='guest', party_id=9999)
feature_scale_1.get_party_instance(role='host', party_id=[10000,9998])
lr_param = {
}
config_param = {
"penalty": "L2",
"tol": 1e-05,
"alpha": 0.01,
"optimizer": "rmsprop",
"batch_size": 320,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"encrypt_param": {
"method": None
},
"max_iter": 5,
"early_stop": "diff",
"cv_param": {
"n_splits": 4,
"shuffle": True,
"random_seed": 33,
"need_cv": False
},
"callback_param": {
"callbacks": ["EarlyStopping"],
"validation_freqs": 1
}
}
lr_param.update(config_param)
print(f"lr_param: {lr_param}")
homo_lr_0 = HomoLR(name='homo_lr_0', **lr_param)
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
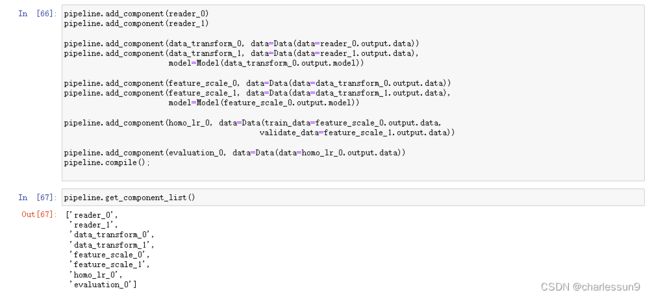
pipeline.add_component(reader_0)
pipeline.add_component(reader_1)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(data_transform_1, data=Data(data=reader_1.output.data),
model=Model(data_transform_0.output.model))
pipeline.add_component(feature_scale_0, data=Data(data=data_transform_0.output.data))
pipeline.add_component(feature_scale_1, data=Data(data=data_transform_1.output.data),
model=Model(feature_scale_0.output.model))
pipeline.add_component(homo_lr_0, data=Data(train_data=feature_scale_0.output.data,
validate_data=feature_scale_1.output.data))
pipeline.add_component(evaluation_0, data=Data(data=homo_lr_0.output.data))
pipeline.compile();
pipeline.get_component_list()
- 加载fate各种库包,设定各方服务器的作用
- 读书数据 and 特征标准化处理
- 构建模型和评估函数
- 构建流程图,其实就是dsl了,并根据get_component_list查看已有流程
- 模型训练,开始训练就可以去FATEBoard查看进展了
4 总结
这个就是fate使用python piepeline的方式进行建模,这个过程相比于在虚拟机中修改dsl和conf的json文件更为简单,且修改起来更方便,当然可以加一些python代码,更加自定义一些。但在实际跑homo nn的时候,数据无法转换成tensor,后续有解决的麻烦告知一下,有任何问题也欢迎讨论。