MIT 6.824 学习(三)【KV Raft】
文章目录
- 一、概述
- 二、实现
-
- 2.1 KV Server
- 2.2 Get
- 2.3 Put/Append
- 三、扩展
-
- 3.1 LSM Tree
-
- 3.1.1 基础结构
- 3.1.2 Compact
一、概述
实验内容来自 MIT 6.824 的 lab3,Lab 3
实现的方式主要参考 raft 作者博士论文 论文 的第六章内容。

主要内容就是实现这三个 RPC 的的语意
ClientRequest RPC:就是追加数据,改变状态的 RPC,就是 Append 函数:
根据论文中的描述,需要通过 clientID 以及 sequenceNum 来保证处理的幂等,从而保证一致性。
// Put or Append
type PutAppendArgs struct {
Key string
Value string
Op string // "Put" or "Append"
sequenceNum int64 // 序列号
clientId int64 // 客户端id
}
type PutAppendReply struct {
Err Err
}
RegisterClient RPC:将客户端节点注册到服务器中的函数,和服务器端建立一个会话。ClientQuery RPC:查询节点数据的 RPC ,就是 Get 方法的实现。
type GetArgs struct {
Key string
sequenceNum int64 // 序列号
clientId int64 // 客户端id
}
type GetReply struct {
Err Err
Value string
}
二、实现
2.1 KV Server
首先实现基本的 KV Raft Server 的结构体:
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
maxraftstate int // snapshot if log grows this big
// 记录应用的状态机索引和 term 防止回滚
lastApplyIndex int
lastApplyTerm int
notifyChans map[int64]chan *CommandResponse // 异步处理查询结果,提醒 Server 响应客户端
lastApplies map[int64]int64 // 每个客户端上一个应用的状态机索引,保证幂等
stateMachine KVStateMachine // 状态机抽象类
}
type CommandResponse struct {
Err Err
Value string
}
type KVStateMachine interface {
Get(key string) (string, Err)
Put(key, value string) Err
Append(key, value string) Err
}
2.2 Get
Raft KV 的读操作,在 KV 层次的实现比较简单,主要在于 Raft 的响应,得到Raft的响应之后,只需要获取 KV 中的键值对。
对于 Raft 的读操作主要包括两种:
- Leader Read:
Leader 的数据是最准确的可以直接返回,但是有一种意外的情况就是发生网络分区之后节点错误的任务自己还是Leader 而造成返回旧数据,所以Leader读取数据需要先确保和其他节点的 LeaderShip。
- Follower Read:
etcd 实现的Follower read是有效的一种一致性读的实现方式。读请求可以发给follower,follower先去leader查询最新的committed index,然后等待自身的committed index增长为读请求发生时的leader的committed index(也就是 apply 了 Leader commit Index 之前所有的日志),从而保证能从follower中读到最新的数据。
// Get 请求
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
_, isLeader := kv.rf.GetState()
if !isLeader {
reply.Err = ErrWrongLeader
return
}
op := Op{
sequenceNum: args.sequenceNum,
ReqId: nrand(), // 可以用雪花算法
Key: args.Key,
Method: Get,
clientId: args.clientId,
}
res := kv.executeCommand(op)
reply.Err = res.Err
reply.Value = res.Value
return
}
// 对命令的处理
func (kv *KVServer) executeCommand(option Op) (resp *CommandResponse) {
_, _, isLeader := kv.rf.Start(option) // 触发 Raft 协议
if !isLeader {
resp.Err = ErrWrongLeader
return
}
kv.mu.Lock()
ch := make(chan *CommandResponse, 1)
kv.notifyChans[option.ReqId] = ch // 使用一个 ch 监听 Raft 处理结果返回
kv.mu.Unlock()
t := time.NewTimer(WaitCmdTimeOut)
defer t.Stop()
select {
case resp = <-ch:
kv.removeCh(option.ReqId)
return
case <-t.C: // 超时处理
kv.removeCh(option.ReqId)
resp.Err = ErrTimeOut
return
}
}
// 应用状态机到raft,一个单独的 goroutinue 运行
func (kv *KVServer) applier() {
for !kv.killed() {
msg := <-kv.applyCh
if !msg.CommandValid {
log.Printf("[applier] msg not CommandValid")
continue
}
// 获取命令索引和参数
//commandIndex := msg.CommandIndex
commanOption := msg.Command.(Op)
kv.mu.Lock()
var err Err
switch commanOption.Method {
case Get:
// get 在switch之后统一返回
case Put:
if kv.isRepeated(commanOption.clientId, commanOption.sequenceNum) {
err = kv.stateMachine.Put(commanOption.Key, commanOption.Value)
}
case Append:
if kv.isRepeated(commanOption.clientId, commanOption.sequenceNum) {
err = kv.stateMachine.Append(commanOption.Key, commanOption.Value)
}
default:
panic("[applier] unknow method")
}
resp := &CommandResponse{}
// 读取操作
if ch, ok := kv.notifyChans[commanOption.ReqId]; ok {
if err != "" {
resp.Err = err
}
value, getErr := kv.stateMachine.Get(commanOption.Key)
if getErr != "" {
resp.Err = getErr
} else {
resp.Err = OK
resp.Value = value
}
ch <- resp
}
kv.mu.Unlock()
}
}
2.3 Put/Append
对于写操作就是触发 Raft 进行写入,达成共识之后,写入 applyCh ,上层 KV 执行写入操作。和上述写操作也类似。
func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
m := map[string]OpMethod{
"Put":Put,
"Append":Append,
}
op := Op{
sequenceNum: args.sequenceNum,
ReqId: nrand(),
Key: args.Key,
Value: args.Value,
Method: m[args.Op],
clientId: args.clientId,
}
reply.Err = kv.executeCommand(op).Err
}
三、扩展
3.1 LSM Tree
3.1.1 基础结构
LSM Tree 是 Log-Structured-Merge-Tree,是许多 key-value 型数据库所依赖的核心数据结构,通过顺序写的方式来提升写入的效率。
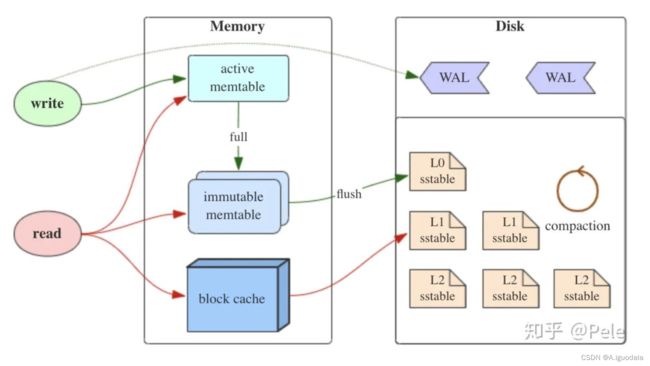
LSM Tree 主要包括三个部分:
MemTable
内存中的存储表,对于数据的写入,会先顺序的写入这张表,为了防止断电导致的数据丢失,会把数据写入到 WAL 中。
为了提高查询的效率会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
Immutable MemTable
当 MemTable 到达一定的大小之后,就会生成 Immutable MemTable 然后顺序的写入磁盘,也就是 MemTable 转变为 SSTable 的一种中间态,MemTable 可以继续处理写请求不造成阻塞。
SSTable(Sorted String Table)
LSM tree 包含一个持久化在硬盘上的数据结构,称为 Sorted Strings Table (SSTable)。顾名思义,SSTable 保存了排序后的数据(实际上是按照 key 排序的 key-value 对)。
因为对于日志的操作是 append 的操作,所以是可以顺序写入的,但是会存在一些问题:
- 冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
- 读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,所以会采取一些优化的策略:
- 对每个 segment 建立稀疏索引,就是对每一个数据块的首部建立索引,记录 key -> offset 的映射。每查询一个 key,先通过 key 二分查找找到对应的偏移量范围,然后读取范围中数据,找到对应值(不建立全量索引是权衡查询和插入的效率,全量索引需要维护插入成本)
- 如果对于SSTable中没有的数据,就要遍历所有 segment,降低大量的效率,所以可以采用 bloom filter 来事先拦截一些不存在的查询。
3.1.2 Compact
因为日志是追加的写,所以 SSTable 会不断膨胀,产生上述的问题1,其实很大一部分存留的 key 是不需要的,所以可以通过整理来压缩。
合并的过程比较简单,就是类似于 map 的覆盖,每条数据都以最新的 segment 为准,遍历所有的 kv,保留最新的 kv 值,复杂度为 O(N)。