随机森林小结
划重点:Bagging + 决策树 = 随机森林
1.算法原理:随机森林,是基于bagging的一种并行式集成学习方法,可以用来做分类、回归。随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由基学习器输出的类别的众数而定。
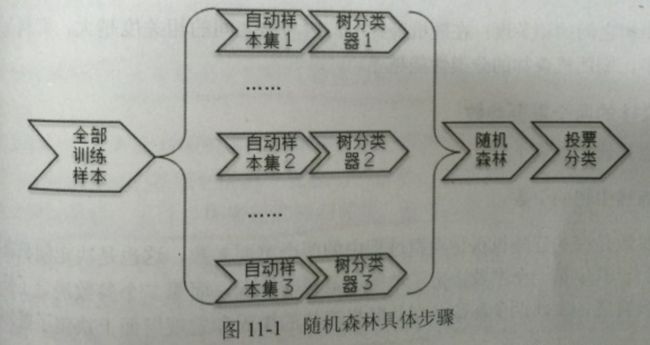
通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取N个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林。
在构造第i棵决策树时,在每个节点随机选择m(通常log2d+1,d是特征数)个特征作为该点划分的候选特征。新数据的分类结果按分类树投票多少形成的分数而定。其实这是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
(随机森林的构建有两个方面:行采样和列采样——样本的随机选取,以及待选特征的随机选取。
即样本的随机:从样本集中用Bootstrap随机选取n个样本;
特征的随机:从所有属性中随机选取K个属性,选择最佳分割属性作为节点建立CART决策树)
(1)集成学习,预测准确率高
(2)随机性的引入,使得随机森林不容易过拟合,有很好的抗噪声能力
(3)能处理很高维度的数据,并且不用做特征选择
(4)既能处理离散型数据,也能处理连续型数据;
树模型——每次筛选都只考虑一个变量不需要归一化,使用数据集无需规范化
(5)训练速度快,可以得到变量重要性排序
(6)实现比较简单,高度并行化,易于分布式实现3.缺点:
(1)忽略属性之间的相关性
(2)随机森林在某些噪音较大的分类或回归问题上会过拟合;
(3)对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响。(如何解决?可以采用信息增益比)
(4)当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
4. 随机森林的构建过程:
(1)从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集
(2)对于n_tree个训练集,我们分别训练n_tree个决策树模型
(3)对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂
(4)每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝
(5)将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果
5.随机森林调参:
https://www.cnblogs.com/gczr/p/7141712.html
(区别碎碎念:
关于树模型和线性模型有什么区别呢?其中最重要的是,树形模型是一个一个特征进行处理,而线性模型是所有特征给予权重相加得到一个新的值。
决策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
而树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可解释性(可以抽取规则)。树模型拟合出来的函数其实是分区间的阶梯函数。
)参考:
https://blog.csdn.net/qq547276542/article/details/78304454
http://www.cnblogs.com/liuwu265/p/4690486.html
https://baike.baidu.com/item/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97/1974765?fr=aladdin
https://www.cnblogs.com/fionacai/p/5894142.html
https://www.cnblogs.com/gczr/p/7141712.html
还要感谢男朋友的总结参考⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄