基于pytorch的logistic回归二元分类(使用UCI成年人收入数据集)
学了几天深度学习,于是做了一个小demo来实践了一下,基于UCI的收入数据集进行训练,输入个人的信息来预测其收入是否>50K美金。数据格式如下:
Example:
input:25, Private, 226802, 11th, 7, Never-married, Machine-op-inspct, Own-child, Black, Male, 0, 0, 40, United-States
output:<=50K.
数据预处理
由于数据中含有字符串,不方便训练,需要先对数据进行预处理转换成数值类型,首先遍历每一个非int型的列,将每个字符串加入一个set,之后将所有的字符串对应上不同数值,放入一个dict。
然后将data中所有的字符串换成对应的数值,处理程序如下:
data = pd.read_csv('../data/adult.data', header=None)
row = data[0:1]
d = {}
for index in row:
temp = row[index]
if temp.dtype != int:
keys = list(set(data[index]))
values = range(len(keys))
d.update(dict(zip(keys, values)))
# print(dict(zip(keys, values)))
# for index_col in data[index].keys():
# data.loc[index_col, index] = d[data[index][index_col]]
data = data.applymap(lambda x: d[x] if type(x) != int else x)
data.to_csv('../data/PreProcess_adult.data', header=None, index=None)
d.update({' <=50K.': d[' <=50K'], ' >50K.': d[' >50K']})
data = pd.read_csv('../data/adult.test', header=None)
data = data.applymap(lambda x: d[x] if type(x) != int else x)
data.to_csv('../data/PreProcess_adult.test', header=None, index=None)
训练前的数据(部分):

处理后的数据:
搭建网络
先将数据读取出来并转化为numpy形式,并进行归一化处理,之后将输入数据和标记分开。
# 数据的生成
train = pd.read_csv('../data/PreProcess_adult.data', header=None)
test = pd.read_csv('../data/PreProcess_adult.test', header=None)
train = np.array(train)
test = np.array(test)
n,l=train.shape
for j in range(l-1):
meanVal=np.mean(train[:,j])
stdVal=np.std(train[:,j])
train[:,j]=(train[:,j]-meanVal)/stdVal
np.random.shuffle(train)
n,l=test.shape
for j in range(l-1):
meanVal=np.mean(test[:,j])
stdVal=np.std(test[:,j])
test[:,j]=(test[:,j]-meanVal)/stdVal
np.random.shuffle(test)
train_data = train[:, :14]
train_lab = train[:, 14]
test_data = test[:, :14]
test_lab = test[:, 14]
取均值和标准差来归一化,之后用shuffle来打乱数据,最后将训练集和测试集分开储存。
之后就可以建立模型并进行训练了。
# 定义模型
class LR(nn.Module):
def __init__(self):
super(LR,self).__init__()
self.fc=nn.Linear(14,2) # 由于24个维度已经固定了,所以这里写24
def forward(self,x):
x=torch.sigmoid(self.fc(x))
return x
def test(pred,lab):
t=pred.max(-1)[1]==lab
return torch.mean(t.float())
#训练
net=LR()
criterion=nn.CrossEntropyLoss() # 使用CrossEntropyLoss损失
optm=torch.optim.Adam(net.parameters()) # Adam优化
epochs=1000 # 训练1000次
for i in range(epochs):
# 指定模型为训练模式,计算梯度
net.train()
# 输入值都需要转化成torch的Tensor
x=torch.from_numpy(train_data).float()
y=torch.from_numpy(train_lab).long()
y_hat=net(x)
loss=criterion(y_hat,y) # 计算损失
optm.zero_grad() # 前一步的损失清零
loss.backward() # 反向传播
optm.step() # 优化
if (i+1)%100 ==0 : # 这里我们每100次输出相关的信息
# 指定模型为计算模式
net.eval()
test_in=torch.from_numpy(test_data).float()
test_l=torch.from_numpy(test_lab).long()
test_out=net(test_in)
# 使用我们的测试函数计算准确率
accu=test(test_out,test_l)
print("Epoch:{},Loss:{:.4f},Accuracy:{:.2f}".format(i+1,loss.item(),accu))
这里的模型直接采用的pytorch的官方教程里的线性网络
训练的结果如下:
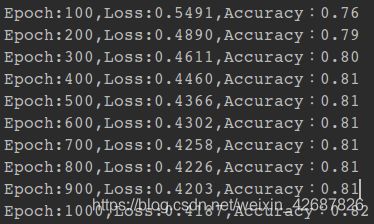
预测的准确率最后收敛为0.82.
工程的github链接:点我跳转