Python数据挖掘学习笔记(4)KNN分类算法----以简单的手写数字的图像识别为例
一、相关理论:
KNN算法,又叫邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法的思想如下图,可以看到,通过计算X与各训练集的距离进行比较,可以得出X所属于的类型。
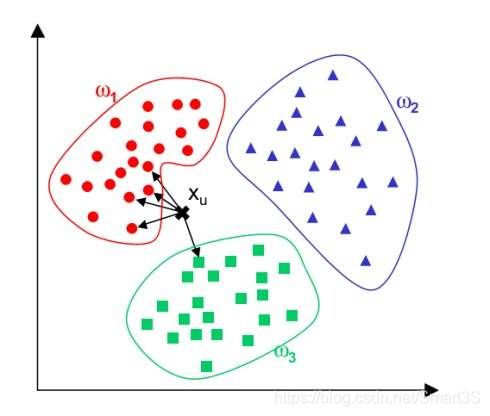
二、应用实例----手写数字图像识别:
1、数据准备,步骤如下:
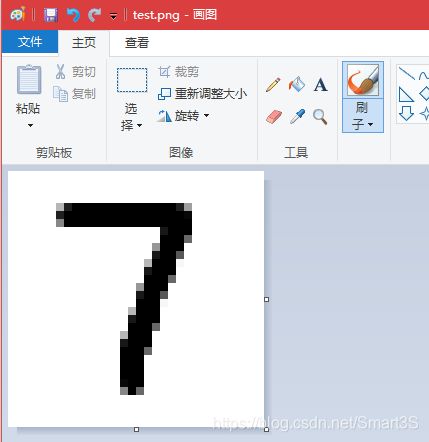
(1)通过windows自带的画图软件绘制一个32X32的手写数字图片:
(2)通过编程将该图片转换为数值矩阵形式的文本数据,可参考:Python数据挖掘学习笔记(3)读取图片数据并转换为文本,代码如下:
#导入PIL模块
from PIL import Image
#读取图片
im=Image.open("E:/test.png")
#打开要写入的文本文档
fh=open("E:/test.txt","a")
width=im.size[0]
height=im.size[1]
#读取图片中的每一个像素
for i in range(0,height):
for j in range(0,width):
cl=im.getpixel((j,i))
clall=cl[0]+cl[1]+cl[2]
#如果是黑色,黑色的RGB值均为0
if(clall==0):
#在txt中写入1
fh.write("1")
else:
#在txt中写入0
fh.write("0")
#读取完之后进行换行
fh.write("\n")
#关闭文本文件
fh.close()(3)图片数据结果:

(4)准备测试数据及训练数据:

下载地址:https://pan.baidu.com/s/11IrMennrFTfjddFz5yhBNA 提取码:yykf
2、用到的相关模块:
from numpy import *
import operator
from os import listdir3、用到的相关方法介绍:
现有:
a=array([1,5,6,4])(1).tile方法:在原有数组基础上,进行行或列的扩展,如:
b=tile(a,2) #行方向扩展为2倍,变成了 1,5,6,4,1,5,6,4
c=tile(a,(2,1)) #列方向扩展为2倍,变成了 1,5,6,4
# 1,5,6,4
d=tile(a,(2,2)) #行列方向均2行2列,变成了 1,5,6,4,1,5,6,4
# 1,5,6,4,1,5,6,4(2).shape方法,获取行列数,当shape[0]为获取列数,shape[1]为获取行数,如:
e=a.shape[0] #结果:4(3).sum方法,数组矩阵求和,.sum(axis=1)每一行的各列求和,.sum(axis=0)各列求和,.sum()所有求和,如:
a.sum(axis=1) #结果:16(4).argsort方法,对数组进行排序,得到的是序号矩阵,如:
a.argsort() #结果:[0,3,1,2]4、正式编写代码:
(1)数据准备的相关方法:
#加载单个数据,将数值矩阵转换为1行的数组并返回
def dataoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0,32):
arr.append(int(thisline[j]))
return arr
#由于测试及训练数据的名称为"数字类型_序号.txt",
#因此需建立一个函数去文件名的前缀来获取数字类型
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split("_")[0])
return label
#建立训练数据,读取所有训练数据
def traindata():
labels=[]
trainfile=listdir("E:/traindata") #得到一个文件夹下所有文件名
num=len(trainfile)
#长度1024(32x32)列,每一行存储一个文件
#用一个数组存储所有训练数据,行:文件总数,列:1024
trainarr=zeros((num,1024)) #生成num行1024列的数组
for i in range(0,num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,:]=dataoarray("E:/traindata/"+thisfname)
return trainarr,labels(2)KNN算法:
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0] #获取列数,若获取行数则是1
#求距离的过程,采用的是欧式距离
dif=tile(testdata,(traindatasize,1))-traindata
sqdif=dif**2
sumsqdif=sqdif.sum(axis=1) #每一行(代表每条训练数据)的各列求和
#.sum()所有求和 .sum(axis=0)各列相加
distance=sumsqdif**0.5
#进行距离排序(升序),得到的是序号矩阵 如[2,10,12,8]排序为[0,3,1,2]
sortdistance=distance.argsort()
count={}
for i in range(0,k):
vote=labels[sortdistance[i]]
count[vote]=count.get(vote,0)+1 #a[5]=a.get(5,0)+1 每出现一次加1
sortcount=sorted(count.items(),key=operator.itemgetter(1),reverse=True) #第2个下标排,降序
#返回识别结果
return sortcount[0][0] (3)可以进行识别测试:
#使用用测试数据调用KNN算法去测试,看是否能够准确识别
def datatest():
trainarr,labels=traindata()
testlist=listdir("E:/testdata")
tnum=len(testlist)
for i in range(0,tnum):
thistestfile=testlist[i]
testarr=dataoarray("E:/testdata/"+thistestfile)
rknn=knn(3,testarr,trainarr,labels)
print(rknn)
#调用测试方法
datatest()(4)进行手写数字图像的正式识别:
#进行正式的图片识别
trainarr,labels=traindata()
thistestfile="E:/test.txt"
testarr=dataoarray(thistestfile)
rknn=knn(3,testarr,trainarr,labels)
print(rknn)运行结果:
