完整学习 ResNet 家族 ResNext, SEResNet, SEResNext 代码实现- part2
我的更新一向缓慢
因为实在太忙碌了, 然后写这些笔记主要也是希望要自己以及看的人都能学到东西, 我写的文章只要你认真的从头看到尾一定有收获, 我喜欢用自己看得懂别人也能读的懂的话语描述出来, 我说不清楚的也会找个链接补充
好了屁话少说
这篇延续上一篇介绍的ResNet, 来说一下ResNext吧
ResNext主要从ResNet的网络做了一些变化, 老样子先从理论在从代码上说会更清楚
如果不清楚ResNet的结构麻烦请看part1在读这篇
因为我要直接上结构图啦
ResNext Block的结构

右边就是我们今天主角ResNext的一个从原始ResNet bottleneck变化的架构
上个论文中的公式装个逼
F ( X ) = ∑ i = 1 C τ i ( x ) F(X) = \sum ^C_{i=1}\tau_i(x) F(X)=∑i=1Cτi(x)
这里的C指的是 Cardinality, 也就是作者提出的新的超参数, 也就是我们要把输入的通道分成多少组来卷积, 一般为32或者是64, 虽然说是可调参数但一般不会去动
τ ( x ) \tau(x) τ(x) 是任意函数, 在ResNext中就是bottleneck的shape
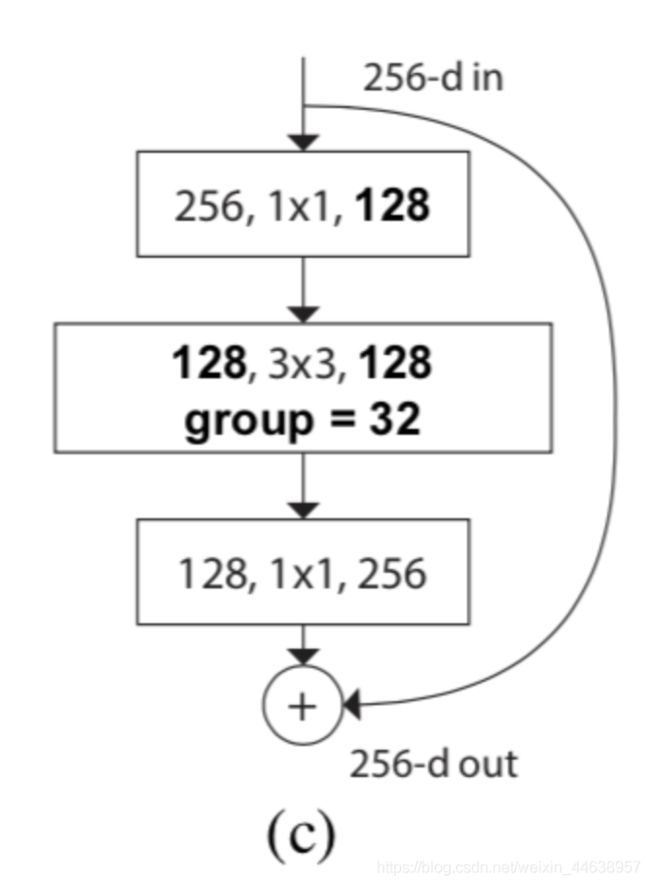
看上图, 注意到input进来的第一个
输入为 256 channels
输出为 128 channels (如果你还记得ResNet只有64, 所以ResNext增加了宽度)

看上图, 实际上将输出通道128分成32组(论文说到的group conv), 那么每一组就是卷积核就是1x1, 通道数为4, 透过这样的方式能够让输出的通道更宽, 也就意味着获取得到的特征越丰富
那么到底是怎么分成32组group的呢?这里有必要解释一下ResNext引进的Grouped Convolution的概念
那么接下来整个block的表达式如下
y = x + ∑ i = 1 C τ i ( x ) y = x + \sum^C_{i=1} \tau_i(x) y=x+∑i=1Cτi(x)
x就是你熟悉的short cut的映射, sum的地方就是32组group(grouped conv)最终要concatenate的地方蓝圈处
最终两者相加, 就是一个block的结构
那么到底Grouped Conv是什么概念呢? 上图最快
Grouped Convolution
传统卷积

上图是一个传统的卷积操作, 假设输入为 (7x7x3)蓝色 经过 (3x3x128)橘色 就变为(5x5x128)
Grouped 卷积
下图是grouped conv的概念, 可以看见原先蓝色的input, 分成了两个等份, 原来的Din(输出维度)也被两个卷积核进行运算, 最终在concatenate成一个绿色的

看图就能快速的理解Grouped Conv的概念了, 到时候在代码说明的地方会在简单说一下group这个参数
接下来你可能会怀疑这样分成32组, 参数量有没有变化? 是不是增加了?
算给你看
下图是原来ResNet的结构
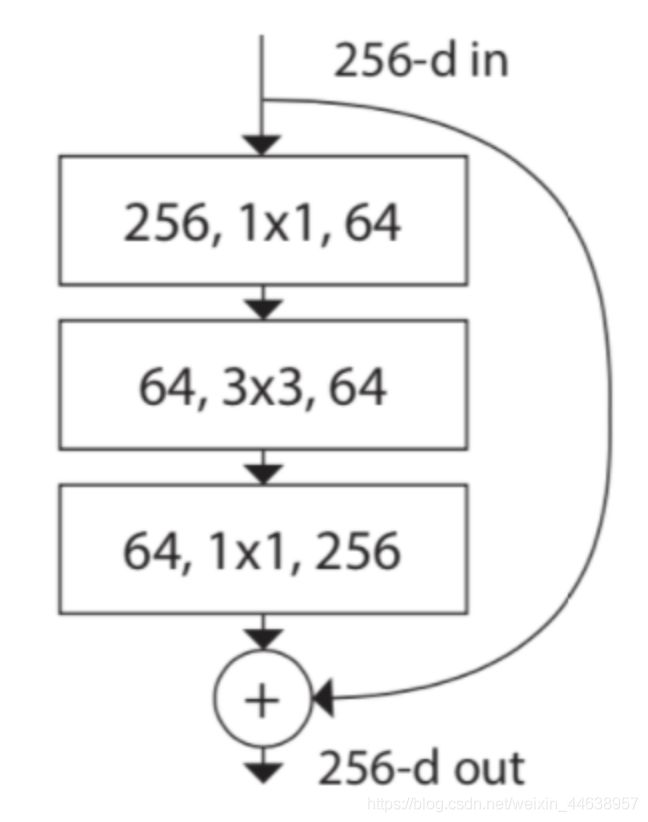
ResNet block
( 256 ∗ 1 ∗ 1 ∗ 64 ) + ( 64 ∗ 3 ∗ 3 ∗ 64 ) + ( 64 ∗ 1 ∗ 1 ∗ 256 ) (256 * 1*1 * 64) + (64 * 3 *3 * 64) + (64 * 1 * 1 *256) (256∗1∗1∗64)+(64∗3∗3∗64)+(64∗1∗1∗256) 约 69, 632参数量
ResNext block
C ∗ ( 256 ∗ d + 3 ∗ 3 ∗ d ∗ d + d ∗ 256 ) C * (256 *d + 3*3*d*d + d*256) C∗(256∗d+3∗3∗d∗d+d∗256) 约70,144 的参数量
假定
Cardinality 设定为32, 输出通道为128, 那么d就是4
参数量只有增加一点点但是能带来性能的上升, 非常值得
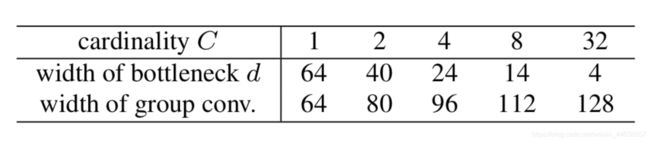
上表为论文中给与的Cardinality和bottleneck 维度的对照
再来关心一下Cardinality和输出维度的怎样的搭配在error上能更有效降低
下表是在ImageNet-1K进行实验, 都能看出32x4d的效果是最好的
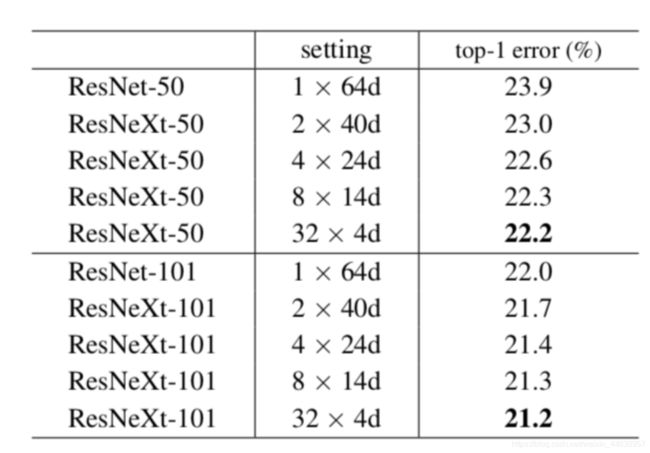
增加Cardinality还是加深加宽网络对网络的性能改善效果最佳?
接下来在看一个有趣的对比
如果将原来的网络复杂度提升一倍,提升的方式有加深, 加宽网络以及增加Cardinality三种
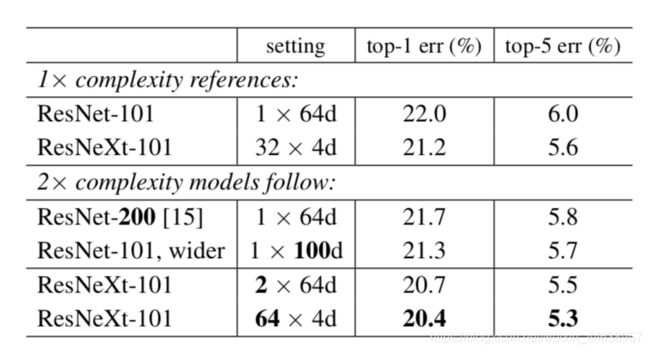
可以看到ResNet网络到200层 error仅仅下降0.03%
而加宽有稍微好一点, error下降了0.07%
但看到最下面一行, ResNext-101 64x4d, 也就是将Cardinality提升一倍, error下降了0.08% (与ResNext-101 32x4d对比), 其实网络复杂度增加一倍, 无论是加深加宽或者是增加Cardinality都是差不多的, 当然最大的改进是直接将网络加上grouped conv
ResNext代码实现
用torchvision 0.41的代码来说明一下, 这次就不整个从头实现一次, 我们把重点放在grouped的实现上说, 其实torch已经把grouped conv的算法都很好的包含在 Conv2d的内置参数groups (实现C = 32), 我们只要调用就好, 问题不大 哈哈 !
ResNext50(32x4d) 与 RexNet50 结构对比

Conv2d 的 groups参数
首先看一下conv3x3这个模块做了哪些改变, 不知道这个模块的请务必看part1
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
Conv2d的地方多了一个参数groups
这边简单的说下这个参数的用法(结合上面的图解更好理解), 个人认为这个参数就是整个ResNext实现的核心
当group为1的时候(默认就是1)
conv = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1, groups=1)
conv.weight.data.size()
>>output
torch.Size([128, 256, 1, 1])
这边能看出output size为 [out_channels, in_channels, kernel_size, kernel_size]
当group为32的时候
conv = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1, groups=32)
conv.weight.data.size()
>>output
torch.Size([128, 8, 1, 1])
可以看见In_channels的地方 变为256/32 = 8
也就是每一组卷积核为128个 shape为(8, 1, 1) , 一共32组计算, 我们就能理解为将输入的layer 分成32组, 每一组卷积核就是(8, 1, 1)来进行计算, 最后再将32组concatenate起来, 也特别注意一下无论是in-channels还是out-channels都必须是groups的倍数
现在我们回到Bottleneck这个类
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups #planes = 64 , base_width = 4, 则width = 64 * (4/64) * 32 = 128
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)#inplanes = width = 128
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation) #注意到只有conv3x3的函数需要group, 1x1的不用
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
对比之前ResNet在初始化参数多了几个参数: groups, base_width, dilation(这个先不说)
以及多了一行width = int(planes * (base_width / 64.)) * groups, 这一样主要就是计算bottleneck中的网络宽度, 仔细看代码会发现width放在第一个conv1x1的out_channels的位置,
那么就来找一下group和base_width和planes是在那边定义的
直接看到最后定义resnext50_32x4d这个网络的函数最快
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
kwargs['groups'] = 32 #这段代码就是指定conv3x3这函数中的groups为32
kwargs['width_per_group'] = 4 #
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
看到关键字
kwargs['groups'] = 32, 这段代码就是指定conv3x3这函数中的groups为32
kwargs['width_per_group'] = 4 顾名思义就是每一个group的宽度, 也就是128 / 32 = 4
所以我们找到定义resnext50_32x4d 最重要的两个参数
最后return的是_resnet这个函数
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
groups 和 width_per_group的值透过**kwargs传入ResNet主体类
接着看一下这参数怎么在ResNet类中实现
ResNet主体结构的代码, 可以看到__init__初始化的地方已经
有groups 默认为1, width_per_group默认为64
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
#################################################################################
self.groups = groups
self.base_width = width_per_group #
#################################################################################
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
看重点地方,
self.groups = groups
self.base_width = width_per_group
这两个参数传入赋值后变成类属性
在看到_make_layer这个函数, 该函数是用来制作ResNet每一个阶段的网络层, 不熟悉请看part1
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
#################################################################################
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
################################################################################
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
_make_layer函数最主要的参数就是block结构, 而ResNext需要的是bottleneck的结构(而不是BasicBlock), 也就回到了我们最一开始说的width = int(planes * (base_width / 64.)) * groups 这个算式
我们现在有了
- groups = 32
- base_width = 4
最后planes呢? 这点在ResNet主体中有定义的, 整个网路架构从conv2 ~ conv5(四个阶段),每一个阶段都是透过__make_layer这个函数来定义, 看到_make_layer的第二个参数就是planes
所以conv2~conv5 依序是64, 128, 256, 512
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
看到这可能觉得奇怪因为和下面这结构图所展示的输出通道不一样啊

我们把网路打印一下来看就知道, 只看conv2 也就是第一个阶段(layer1), 一共是3组bottleneck
也就是下面的0, 1, 2, 上图的结构真正对应到的是1, 2的部分, 可以看到conv1输出为128维, 经过conv1(1x1), conv2(3x3) conv3(1x1)之后, 输出是256维, 不就和上图是一个结构吗?
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
我们现在有了
- groups = 32
- base_width = 4
- planes = 64 (只用第一个阶段来说明)
带回width = int(planes * (base_width / 64.)) * groups
算出width = 128, 接着就能带回bottleneck结构中的conv1(1x1), conv2(3x3) conv3(1x1)计算出输出每一层输出通道
所以其实ResNext主要加上了groups 这个Conv2d类自带的参数, 也是实现整个ResNext的核心关键
总结一下ResNext 的优点
- 利用Grouped convolution的概念提升了网络性能, 更强的表达能力
- 因为Grouped conv同时又能进行多GPU训练, 也就是模型的并行化(model parallelization), 多个GPU能够让更多的图片输入进网络
- 参数量与原始ResNet差不多, 性能提升
下一篇将继续讲一下加上SE模块的ResNet
Inference
https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e582150
https://arxiv.org/pdf/1611.05431.pdf