阅读心得:CenterTrack:Tracking Objects as Points
论文地址: 论文出处
代码地址:code
CenterTrack
- 一、 摘要
- 二、 介绍
- 三、 预备
-
- CenterNet
- 以点追踪目标
- 追踪条件检测器
- 偏移连接
- 实验
-
- 消融学习
- 总结
一、 摘要
本文提出的CenterTrack是一个检测和追踪同时进行的算法。使用之前的检测和当前帧的一对图片来检测模型。考虑到最小化输出,CenterTrack直接利用过去帧定位目标并且预测轨迹。切该网络容易拓展到3D单眼追踪网络。
二、 介绍
早期网络强调追踪时空中感兴趣的目标,虽然快速,简单,但是容易忽略低级的线索(角和高强度峰值)。随着高性能检测器的出现,便出现TBD(检测后追踪)模式,将检测和追踪分为两步。首先在每帧中找到所有目标,然后追踪的任务就变成了一个边界框关联。因为给定了检测的结果,只需要关注如何将相同的目标连接起来(轨迹)即可。但是大多数的关联策略都是复杂的,高计算量的。主要由两个缺点:1.数据关联的时候直接放弃了图片的外貌特征或者需要极大的计算力来进行特征提取;2.检测与追踪分离。
为了降低计算量,本文的模型以基于点的追踪将目标检测和追踪同时进行。本模型直接和检测联合进行学习,几乎不需要关联。在使用过去帧进行学习的同时,可以利用他的线索来对消失的或者遮挡的目标进行恢复。

使用CenterNet检测器来定位目标中心。模型输入为一对相邻帧的图像以及以点表示的前帧轨迹的热图上。训练检测器输出一个当前目标中心和之前帧目标中心补偿向量,作为中心点的一个属性。仅根据预测偏移量与前一帧检测到的中心点之间的距离进行贪婪匹配,即可实现目标关联。追踪器实现端到端训练。
本方法首先,它简化了跟踪条件检测。每个对象用点表示,对象群用热图中的所有点表示。检测器直接提取热图,在帧之间将他们关联来推理目标。其次,基于点的追踪节省了目标关联的时间。简单的位移预测(中心位移补偿)类似于稀疏光流,允许目标在不同帧之间进行关联。位移由前帧决定,可以根据前帧的关联联合来推测当前帧的目标。
有过去帧作为输入,CenterTrack可以很容易地学习重复前一帧的预测,从而拒绝跟踪那些会造成很大训练错误的情况。
缺点是无法进行长帧追踪,输入为相邻俩帧。但是实现了本地简单快捷,高准确率的运行。使用点来表示对象还有个好处是不用担心低帧情况下,帧间存在大的重叠的边界框导致的错误。
使用前一帧关键点的热图作为追踪输入有两点原因:
1.过去帧的信息已获取,不需要耗费太多的计算资源,也不会降低检测器的速度。
2. 条件跟踪可以推断出在当前帧中可能不再可见的被遮挡对象。追踪器可以简单的学习从前帧中保存这些检测。
三、 预备
CenterNet
有关CenterNet的相关知识在CenterNet,需要看的可以跳过去。
以点追踪目标
将追踪任务看成是一个连续帧之间的传播目标检测身份任务,而不需要在时间间隔之间重新建立关联。
t时刻,给予一个当前帧的图片 I ( t ) ∈ R W × H × 3 I^{(t)}\in R^{W×H×3} I(t)∈RW×H×3,过去帧 I ( t − 1 ) ∈ R W × H × 3 I^{(t-1)}∈R^{W×H×3} I(t−1)∈RW×H×3和过去帧中的目标 T ( t − 1 ) = { b 0 ( t − 1 ) , b 1 ( t − 1 ) , … } i T^{(t-1)}=\{b_0^{(t-1)},b_1^{(t-1)},…\}_i T(t−1)={b0(t−1),b1(t−1),…}i。对于每个目标b=(p,s,w,id),p∈ R²是中心点,s∈R²是大小, w ∈ [ 0 , 1 ] w\in [0,1] w∈[0,1]是检测置信度,以及身份 i d ∈ I id\in I id∈I。任务是检测和追踪当前帧的目标 T ( t ) = { b 0 ( t ) , b 1 ( t ) , … } T^{(t)}=\{b_0^{(t)},b_1^{(t)},…\} T(t)={b0(t),b1(t),…},同时为在两个帧中都出现的目标赋一个连续的id。
但是要找到所有帧中的所有目标,包括遮挡的,同时要在时序上将他们的身份关联都是挑战。本文使用一个深度网络来实现端到端训练同时解决这两个问题:使用条件检测器和一个简单的补偿预测方案。条件检测器用过去帧来改善当前帧的检测,补偿预测用于在时序上连接目标。
追踪条件检测器
利用过去帧的追踪检测信息来改善当前帧的检测。虽然CenterNet以及提供了够多的信息用于追踪,但是他无法找到那些在当前帧中无法直接观察的目标,并且检测出的目标可能存在时间不一致性。
自然而然的想到在传入当前帧输入的时候,传入一个过去相邻帧的信息,用于评估场景变化并潜在恢复当前帧的遮挡目标。
CenterTrack同时还传入了一个过去帧的热图,每个目标用点表示,热图使用和CenterNet中一样的高斯渲染函数渲染。渲染置信度高于阈值τ的点以便减少假阳性检测的提升。中心结构和CenterNet基本相同,只是多了额外的四个通道的数据。虽然解决了时间不一致性,但仍有可能会在时序上不匹配。
偏移连接

图2展示了偏移预测。CenterTrack预测了一个额外的2维位移输出 D ^ ( t ) ∈ R W R × H R × 2 \hat D^{(t)}∈R^{\frac {W}{R}×\frac {H}{R}×2} D^(t)∈RRW×RH×2,用于在时序上关联目标。对于每个在位置 p ^ ( t ) \hat p^{(t)} p^(t)上的检测目标,其位移是 d ^ ( t ) = D ^ p ^ ( t ) ( t ) \hat d^{(t)}={\hat D^{(t)}_{\hat p^{(t)}}} d^(t)=D^p^(t)(t),用于捕捉当前帧 p ^ ( t ) \hat p^{(t)} p^(t)和过去帧 p ^ ( t − 1 ) \hat p^{(t-1)} p^(t−1)上目标的差距 d ^ ( t ) = p ^ ( t ) − p ^ ( t − 1 ) \hat d^{(t)}=\hat p^{(t)} - \hat p^{(t-1)} d^(t)=p^(t)−p^(t−1)。我们使用相同的回归函数来学习这个位移作为位置和坐标的微调:
L o f f = 1 N ∑ i = 1 N ∣ D ^ p i ( t ) − ( p i ( t − 1 ) − p i ( t ) ) ∣ L_{o f f}=\frac{1}{N} \sum_{i=1}^{N}\left|\hat{D}_{\mathbf{p}_{i}^{(t)}}-\left(\mathbf{p}_{i}^{(t-1)}-\mathbf{p}_{i}^{(t)}\right)\right| Loff=N1i=1∑N∣∣∣D^pi(t)−(pi(t−1)−pi(t))∣∣∣ p i ( t − 1 ) p_i^{(t-1)} pi(t−1)和 p i ( t ) p_i^{(t)} pi(t)追踪目标真实坐标值。
当这个位移损失足够低,使用一个贪婪匹配算法来完成在时序上连接目标。在 p ^ \hat p p^上每个检测目标,将过去帧中未匹配的点且距离在 p ^ − D ^ p ^ \hat p-{\hat D}_{\hat p} p^−D^p^内按置信度 w ^ \hat w w^递减排序,若在半径κ内未匹配上,则生成一条新路径。κ定义为每个预测轨迹的预测边界框的高和宽的几何均值。
举例:输入一个上帧追踪的目标的轨迹 T ( t − 1 ) = { ( p , d , i d ) j ( t − 1 ) } j = 1 M T^{(t-1)} = \{( p, d,id)^{(t-1)}_j\} ^M_{j=1} T(t−1)={(p,d,id)j(t−1)}j=1M, p p p和 d d d都是一个二维数组, p p p代表中心点, s s s代表 s i z e = ( w , h ) size=(w,h) size=(w,h)。还有当前帧预测中心点和偏移量 B ^ ( t ) = { ( p ^ , d ^ ) i ( t ) } i = 1 N \hat B^{(t)} = \{(\hat p, \hat d)^{(t)}_i\} ^N_{i=1} B^(t)={(p^,d^)i(t)}i=1N按照热图中的峰值(即中心点)按照 d ^ \hat d d^递减排序的。
目的:输出当前帧轨迹 T ( t ) = { ( p , d , i d ) i ( t ) } j = 1 N T^{(t)} = \{( p, d,id)^{(t)}_i\} ^N_{j=1} T(t)={(p,d,id)i(t)}j=1N。初始 T ( t ) T^{(t)} T(t)和以匹配点 S S S都为0 。
推理:计算矩阵 W = C o s t ( B ( t ) , T ( t − 1 ) ) W=Cost(B^{(t)},T^{(t-1)}) W=Cost(B(t),T(t−1))
W i j = ∥ p ^ i ( t ) − d ^ i ( t ) , p j ( t − 1 ) ∥ 2 W_{i j}=\left\|\hat{\mathbf{p}}_{i}^{(t)}-\hat{\mathbf{d}}_{i}^{(t)}, \mathbf{p}_{j}^{(t-1)}\right\|_{2} Wij=∥∥∥p^i(t)−d^i(t),pj(t−1)∥∥∥2
对于当前帧的每个目标使用贪婪匹配,首先寻找它的最小 W i j W_{i j} Wij对应的未匹配的 j j j;然后计算阈值 k = m i n ( w ^ i h ^ i , w j h j ) k=min(\sqrt{\hat w_i\hat h_i},\sqrt{w_jh_j}) k=min(w^ih^i,wjhj)。
如果 j j j对应的 W i j < k W_{ij}
S = S ∪ { j } S = S∪\{j\} S=S∪{j}
即检测的热图的当前帧热图的中心点和偏移值和上一帧id组合进新轨迹。
如果所有的 W i j < k W_{ij}
T ( t ) = T ( t ) ∪ ( p ^ i ( t ) , s ^ i ( t ) , N e w I d ) T^{(t)}=T^{(t)}∪(\hat p_i^{(t)},\hat s_i^{(t)},NewId) T(t)=T(t)∪(p^i(t),s^i(t),NewId)
在视频数据上的训练,一个主要的挑战是需要传入的前帧热图是可靠的。推理时,这个热图可以包含自定义多的目标,错误定位目标甚至假正性。但是训练时传入的真实轨迹 { p 0 ( t − 1 ) , p 1 ( t − 1 ) , … } \{p_0^{(t-1)},p_1^{(t-1)},…\} {p0(t−1),p1(t−1),…}并不会有这些错误,所以会使用一些数据增强策略来增强模型鲁棒性。
实验中,不一定非要使用相邻的前帧,可以使用t帧附近的随机采样防止过拟合。
实验
实验基于CenterNet,使用DLA作为网络backbone,优化器使用学习率为1,25e-4的Adam,batchsize为32。数据增强使用随机水平翻转,随机大小裁剪和颜色抖动。每个实验训练70个epoch,学习率在60个epoch下降10倍。主要看在MOT数据集上的测试。

消融学习

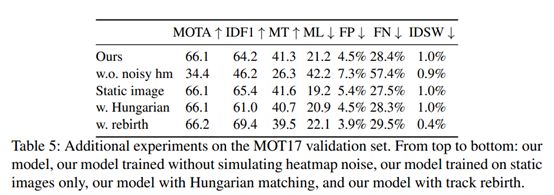
对比其他的运动检测模型:No motion代表设置offset为0,直接引用表4。

总结
提出了一个端到端同时的目标检测和跟踪框架。方法以两个帧和一个先验的热图作为输入,对当前帧产生检测和跟踪偏移量。跟踪器完全是本地的,并通过时间贪婪地关联对象,能够实时运行并且是Online模式。