XPath的死角
文章目录
- 前言
- 问题
- LXML的见解和方案
- 小结
前言
在网络爬虫和网页信息抽取领域,XPath、CSS Selector和正则表达式是选择、过滤HTML标签和文本节点的主要工具。三种技术都有各自的爱好者。个人认为XPath功能比较全面,但它在某些场景下也难以满足需求。
问题
Xpath有各种定位标签的方式,定位文本的方式只有/text()和//text()。有时候,我们希望更加精确地定位某个文本节点,但就是无法做到。
例如,在下面这个网页中,文章的作者和发表时间这两个子段,无法通过XPath直接分开。

具体原因,需要看HTML源代码。
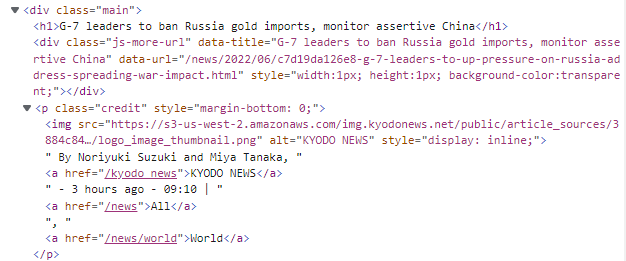
我们看到,作者和发表时间都是p标签的文本,中间有a标签分隔,但都不是a标签的text。
简化的HTML如下所示。
<p>
author
<a>websitea>
datetime
p>
使用xpath选择author和datetime只能这样。
//p/text()
得到的结果:author datetime
LXML的见解和方案
lxml对于这个问题有自己的解决方式,它使用text和tail来区分这两种不同的文本。
text表示标签内的文本
tail表示标签后面紧随的文本
但是,使用者仍然要用//text()先获取全部文本节点,然后才能获得每个文本节点的类型,text还是tail。
无法用xpath直接定位到tail文本。
也就是,使用者无法给出这样的xpath并直接得到结果。
/p/text() -> author
/p/a/tail() -> datetime
但是,LXML总归是给了一条路,让大家在某些场景下,可以绕过这个坑。
小结
本文介绍了一个XPath无法准确定位文本节点的问题,并简单说明了LXML的解决方案。