DataWhale图网络学习(六)基于图神经网络的图表征学习方法
基于图神经网络的图表征学习方法
- 1 图同构网络理论
-
- 1.1 基于图同构网络的图表征学习
- 1.2 图同构和WL Test算法
- 1.3 判断图同构性的条件
- 1.4 关于图同构网络的总结:
- 2 图同构网络实现
-
- 2.1 基于图同构网络的图表征模块
- 2.2 基于图同构网络的节点嵌入模块(GINNodeEmbedding Module)
- 2.3 GINConv--图同构卷积层
- 2.4 AtomEncoder与 BondEncoder
前边我们已经了解了图节点的表征学习,其主要是根据节点的属性进行学习和预测,而现在我们要学习基于图神经网络的图表征的学习方法。图表征就是根据图的节点属性和边(及边的属性如果有的话)得到一个向量作为图的表征,基于这个表征我们再进行下一步的图预测。基于图同构网络How Powerful are Graph Neural Networks? 的图表征网络是当前最经典的图表征学习网络,我们就以这个为例来学习。
图同构网络设计的动机是:目前新的图神经网络的设计大多基于经验性的直觉、启发式的方法和实验性的试错。然而人们对图神经网络的特性和局限性了解甚少,对图神经网络的表征能力学习的正式分析也很有限。
1 图同构网络理论
1.1 基于图同构网络的图表征学习
主要包含以下两个过程:
- 首先计算得到节点表征;
- 其次对图上各个节点的表征做图池化(Graph Pooling),或称为图读出(Graph Readout),得到图的表征(Graph Representation)。
最简单的图读出操作是做求和。由于每一层的节点表征都可能是重要的,因此在图同构网络中,不同层的节点表征在求和后被拼接,其数学定义如下,
h G = CONCAT ( READOUT ( { h v ( k ) ∣ v ∈ G } ) ∣ k = 0 , 1 , ⋯ , K ) h_{G} = \text{CONCAT}(\text{READOUT}\left(\{h_{v}^{(k)}|v\in G\}\right)|k=0,1,\cdots, K) hG=CONCAT(READOUT({hv(k)∣v∈G})∣k=0,1,⋯,K)
采用拼接而不是相加的原因在于不同层节点的表征属于不同的特征空间。 未做严格的证明,这样得到的图的表示与WL Subtree Kernel得到的图的表征是等价的。
这里节点表征是通过节点嵌入模块实现的,而节点嵌入模块则通过GINConv——图同构卷积层实现,数学定义如下:
x i ′ = h Θ ( ( 1 + ϵ ) ⋅ x i + ∑ j ∈ N ( i ) x j ) \mathbf{x}^{\prime}_i = h_{\mathbf{\Theta}} \left( (1 + \epsilon) \cdot \mathbf{x}_i + \sum_{j \in \mathcal{N}(i)} \mathbf{x}_j \right) xi′=hΘ⎝⎛(1+ϵ)⋅xi+j∈N(i)∑xj⎠⎞
或者
X ′ = h Θ ( ( A + ( 1 + ϵ ) ⋅ I ) ⋅ X ) , \mathbf{X}^{\prime} = h_{\mathbf{\Theta}} \left( \left( \mathbf{A} + (1 + \epsilon) \cdot \mathbf{I} \right) \cdot \mathbf{X} \right), X′=hΘ((A+(1+ϵ)⋅I)⋅X),
PyG中已经实现了此模块,我们可以通过torch_geometric.nn.GINConv来使用PyG定义好的图同构卷积层,然而该实现不支持存在边属性的图。
CLASS GINConv(nn: Callable, eps: float = 0.0, train_eps: bool = False, **kwargs)
nn (torch.nn.Module):一个神经网络 h Θ h_{\mathbf{\Theta}} hΘ将形状为[-1,in_channels]的节点特征x映射为形状为[-1,out_channels],例如,由torch.nn.Sequential定义。eps(float):初始化 ϵ \epsilon ϵ,默认为0。train_eps(bool):如果设置为True, ϵ \epsilon ϵ将是一个可训练参数。(默认值:False)。
1.2 图同构和WL Test算法
那么什么是图同构呢?图同构就是说两个图拥有一样的拓扑结构,也就是说,我们可以通过重新标记节点从一个图中得到另外一个图。Weisfeiler-Lehman 图的同构性测试算法,简称WL Test,是一种用于测试两个图是否同构的算法。
那么我们接下来看一下WL Test算法,其一维形式类似于图神经网络中的邻接节点聚合。首先 1) 迭代地聚合节点及其邻接节点的标签,然后2) 将聚合的标签散列成唯一的新标签,该过程形式化为下方的公式。
L u h ← hash ( L u h − 1 + ∑ v ∈ N ( U ) L v h − 1 ) L^{h}_{u} \leftarrow \operatorname{hash}\left(L^{h-1}_{u} + \sum_{v \in \mathcal{N}(U)} L^{h-1}_{v}\right) Luh←hash⎝⎛Luh−1+v∈N(U)∑Lvh−1⎠⎞
其中, L u h L^{h}_{u} Luh表示节点 u u u的第 h h h次迭代的标签,第 0 0 0次迭代的标签为节点原始标签。如果在迭代过程中,发现两个图之间的节点的标签不同时,就可以确定这两个图是非同构的。需要注意的是节点标签可能的取值只能是有限个数。
下面我们通过两个图G和G'来直观的理解一下WL Test算法,这里每个节点拥有标签(实际中,一些图没有节点标签,我们可以以节点的度作为标签)。
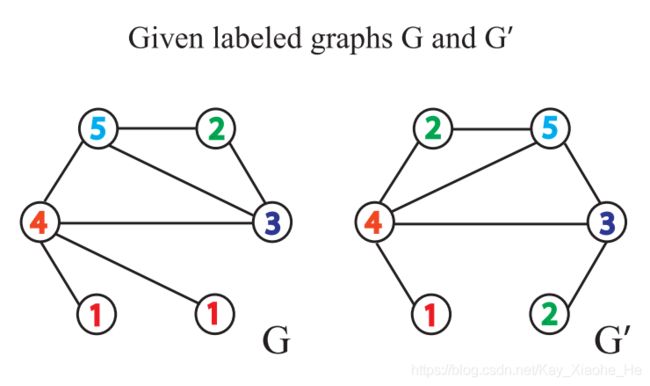
- 对于这两个图,每个节点聚合自身以及邻接节点的标签得到一串字符串,自身字符串与邻接节点标签的字符串用
,隔开,邻接节点的字符串按照升序排列(原因是保证单射性,不因邻接节点的顺序改变而发生改变)。

- 将标签顺序散列,即将标签字符串压缩,得到一个简短的标签

- 重新给节点打上新的到的标签

如此重复上述过程,以进行节点标签的更新。如果上述的步骤重复一定的次数后,没有发现有相同节点标签的出现次数不一致的情况,那么我们无法判断两个图是否同构。而当出现两个图相同节点标签的出现次数不一致时,即可判断两个图不相似。
当两个节点的 h h h层的标签一样时,表示分别以这两个节点为根节点的WL子树是一致的。WL子树与普通子树不同,WL子树包含重复的节点。下图展示了一棵以1节点为根节点高为2的WL子树。

图相似性评估
WL Test 算法的一点局限性是,它只能判断两个图的相似性,无法衡量图之间的相似程度。要衡量两个图的相似程度,我们用WL Subtree Kernel方法。
该方法的思想是用WL Test算法得到节点的多层的标签,然后我们可以分别统计图中各类标签出现的次数,存于一个向量,这个向量可以作为图的表征。两个图的这样的向量的内积,即可作为这两个图的相似性的估计。

这里原始图G的标签为[1,2,3,4,5],出现次数分别为[2,1,1,1,1],同理G'的标签[1,2,3,4,5],出现次数为[1,2,1,1,1],由此构成了向量的前半部分(original部分)。向量的第二部分是压缩后的标签有8个,分别为[6,7,8,9,10,11,12,13],对于G图,出现的次数分别为[2,0,1,0,1,1,0,1],对于图G'出现的次数分别为[1,1,0,1,1,0,1,1],由此构成向量的后边部分(compressed部分)。两个向量的内积为11,因此相似性度量为11。
1.3 判断图同构性的条件
能实现判断图同构性的图神经网络需要满足:
- 只在两个节点自身标签一样且它们的邻接节点一样时,图神经网络将这两个节点映射到相同的表征,即映射是单射性的。
- 一个节点的所有邻接节点是一个可重复集合,一个节点可以有重复的邻接节点,邻接节点没有顺序关系。 因此GIN模型中生成节点表征的方法遵循WL Test算法更新节点标签的过程。(可重复集合(Multisets)指的是元素可重复的集合,元素在集合中没有顺序关系。 )
1.4 关于图同构网络的总结:
- (理论上)图神经网络在区分图结构方面最高只能达到与WL Test一样的能力。
- 确定了邻接点聚合方法和图池化方法的应具备的条件,在这些条件下,所产生的图神经网络能达到与WL Test一样的能力。
- 确定了过去流行的图神经网络变体(如GCN和GraphSAGE)无法区分的图结构,并描述了这种基于图神经网络的模型能够捕获的图结构类型。
- 开发了一个简单的神经结构–图形同构网络(GIN),并证明其分辨/表示能力与WL Test相当。
2 图同构网络实现
我们从顶向下的来实现基于图同构模型(GIN)的图表征学习方法。
2.1 基于图同构网络的图表征模块
我们首先关注如何基于节点表征计算得到图的表征,而忽略计算结点表征的方法。此模块首先采用GINNodeEmbedding模块对图上每一个节点做节点嵌入(Node Embedding),得到节点表征;然后对节点表征做图池化得到图的表征;最后用一层线性变换对图表征转换为对图的预测。
import torch
from torch import nn
from torch_geometric.nn import global_add_pool, global_mean_pool, global_max_pool, GlobalAttention, Set2Set
from gin_node import GINNodeEmbedding
class GINGraphRepr(nn.Module):
def __init__(self, num_tasks=1, num_layers=5, emb_dim=300, residual=False, drop_ratio=0, JK="last", graph_pooling="sum"):
"""GIN Graph Pooling Module
Args:
num_tasks (int, optional): number of labels to be predicted. Defaults to 1 (控制了图表征的维度,dimension of graph representation).
num_layers (int, optional): number of GINConv layers. Defaults to 5.
emb_dim (int, optional): dimension of node embedding. Defaults to 300.
residual (bool, optional): adding residual connection or not. Defaults to False.
drop_ratio (float, optional): dropout rate. Defaults to 0.
JK (str, optional): 可选的值为"last"和"sum"。选"last",只取最后一层的结点的嵌入,选"sum"对各层的结点的嵌入求和。Defaults to "last".
graph_pooling (str, optional): pooling method of node embedding. 可选的值为"sum","mean","max","attention"和"set2set"。 Defaults to "sum".
Out:
graph representation
"""
super(GINGraphPooling, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
self.emb_dim = emb_dim
self.num_tasks = num_tasks
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.gnn_node = GINNodeEmbedding(num_layers, emb_dim, JK=JK, drop_ratio=drop_ratio, residual=residual)
# Pooling function to generate whole-graph embeddings
if graph_pooling == "sum":
self.pool = global_add_pool
elif graph_pooling == "mean":
self.pool = global_mean_pool
elif graph_pooling == "max":
self.pool = global_max_pool
elif graph_pooling == "attention":
self.pool = GlobalAttention(gate_nn=nn.Sequential(
nn.Linear(emb_dim, emb_dim), nn.BatchNorm1d(emb_dim), nn.ReLU(), nn.Linear(emb_dim, 1)))
elif graph_pooling == "set2set":
self.pool = Set2Set(emb_dim, processing_steps=2)
else:
raise ValueError("Invalid graph pooling type.")
if graph_pooling == "set2set":
self.graph_pred_linear = nn.Linear(2*self.emb_dim, self.num_tasks)
else:
self.graph_pred_linear = nn.Linear(self.emb_dim, self.num_tasks)
def forward(self, batched_data):
h_node = self.gnn_node(batched_data)
h_graph = self.pool(h_node, batched_data.batch)
output = self.graph_pred_linear(h_graph)
if self.training:
return output
else:
# At inference time, relu is applied to output to ensure positivity
# 因为预测目标的取值范围就在 (0, 50] 内
return torch.clamp(output, min=0, max=50)
计算图的表征的方法(即图池化的方法)有以下几种:
sum:对节点表征求和;使用模块torch_geometric.nn.glob.global_add_pool。mean:对节点表征求平均;使用模块torch_geometric.nn.glob.global_mean_pool。max:取节点表征的最大值;使用模块torch_geometric.nn.glob.global_max_pool。attention:基于Attention对节点表征加权求和;使用模块 torch_geometric.nn.glob.GlobalAttention。set2set:另一种基于Attention对节点表征加权求和的方法;使用模块 torch_geometric.nn.glob.Set2Set。
2.2 基于图同构网络的节点嵌入模块(GINNodeEmbedding Module)
上边的模块按照第一部分的两步得到了图的表征,而在上一部分中,图的池化已经表达的很清楚,那么节点表征是如何计算的呢?
此模块基于多层GINConv实现结点嵌入的计算。此处我们先忽略GINConv的实现。输入到此节点嵌入模块的节点属性为类别型向量,我们首先用AtomEncoder对其做嵌入得到第0层节点表征。然后我们逐层计算节点表征,从第1层开始到第num_layers层,每一层节点表征的计算都以上一层的节点表征h_list[layer]、边edge_index和边的属性edge_attr为输入。需要注意的是,GINConv的层数越多,此节点嵌入模块的感受野(receptive field)越大,结点i的表征最远能捕获到结点i的距离为num_layers的邻接节点的信息。
import torch
from mol_encoder import AtomEncoder
from gin_conv import GINConv
import torch.nn.functional as F
# GNN to generate node embedding
class GINNodeEmbedding(torch.nn.Module):
"""
Output:
node representations
"""
def __init__(self, num_layers, emb_dim, drop_ratio=0.5, JK="last", residual=False):
"""GIN Node Embedding Module"""
super(GINNodeEmbedding, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
# add residual connection or not
self.residual = residual
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.atom_encoder = AtomEncoder(emb_dim)
# List of GNNs
self.convs = torch.nn.ModuleList()
self.batch_norms = torch.nn.ModuleList()
for layer in range(num_layers):
self.convs.append(GINConv(emb_dim))
self.batch_norms.append(torch.nn.BatchNorm1d(emb_dim))
def forward(self, batched_data):
x, edge_index, edge_attr = batched_data.x, batched_data.edge_index, batched_data.edge_attr
# computing input node embedding
h_list = [self.atom_encoder(x)] # 先将类别型原子属性转化为原子表征
for layer in range(self.num_layers):
h = self.convs[layer](h_list[layer], edge_index, edge_attr)
h = self.batch_norms[layer](h)
if layer == self.num_layers - 1:
# remove relu for the last layer
h = F.dropout(h, self.drop_ratio, training=self.training)
else:
h = F.dropout(F.relu(h), self.drop_ratio, training=self.training)
if self.residual:
h += h_list[layer]
h_list.append(h)
# Different implementations of Jk-concat
if self.JK == "last":
node_representation = h_list[-1]
elif self.JK == "sum":
node_representation = 0
for layer in range(self.num_layers + 1):
node_representation += h_list[layer]
return node_representation
接下来看该模块中的关键组件GINConv。
2.3 GINConv–图同构卷积层
其原理与数学表达式在前边已经介绍过,下面直接来看实现:
import torch
from torch import nn
from torch_geometric.nn import MessagePassing
import torch.nn.functional as F
from ogb.graphproppred.mol_encoder import BondEncoder
### GIN convolution along the graph structure
class GINConv(MessagePassing):
def __init__(self, emb_dim):
'''
emb_dim (int): node embedding dimensionality
'''
super(GINConv, self).__init__(aggr = "add")
self.mlp = nn.Sequential(nn.Linear(emb_dim, emb_dim), nn.BatchNorm1d(emb_dim), nn.ReLU(), nn.Linear(emb_dim, emb_dim))
self.eps = nn.Parameter(torch.Tensor([0]))
self.bond_encoder = BondEncoder(emb_dim = emb_dim)
def forward(self, x, edge_index, edge_attr):
edge_embedding = self.bond_encoder(edge_attr) # 先将类别型边属性转换为边表征
out = self.mlp((1 + self.eps) *x + self.propagate(edge_index, x=x, edge_attr=edge_embedding))
return out
def message(self, x_j, edge_attr):
return F.relu(x_j + edge_attr)
def update(self, aggr_out):
return aggr_out
由于输入的边属性为类别型,因此我们需要先将类别型边属性转换为边表征。我们定义的GINConv模块遵循“消息传递、消息聚合、消息更新”这一过程。
- 这一过程随着
self.propagate()方法的调用开始执行,该函数接收edge_index,x,edge_attr此三个参数。edge_index是形状为[2,num_edges]的张量(tensor)。 - 在消息传递过程中,此张量首先被按行拆分为
x_i和x_j张量,x_j表示了消息传递的源节点,x_i表示了消息传递的目标节点。 - 接着
message()方法被调用,此函数定义了从源节点传入到目标节点的消息,在这里要传递的消息是源节点表征与边表征之和的relu()的输出。我们在super(GINConv, self).__init__(aggr = "add")中定义了消息聚合方式为add,那么传入给任一个目标节点的所有消息被求和得到aggr_out,它还是目标节点的中间过程的信息。 - 接着执行消息更新过程,我们的类
GINConv继承了MessagePassing类,因此update()函数被调用。然而我们希望对节点做消息更新中加入目标节点自身的消息,因此在update函数中我们只简单返回输入的aggr_out。 - 然后在
forward函数中我们执行out = self.mlp((1 + self.eps) *x + self.propagate(edge_index, x=x, edge_attr=edge_embedding))实现消息的更新。
在实现了GINConv模块后我们发现还有两个组件AtomEncoder 和BondEncoder分别出现在GINNodeEmbedding Module模块和GINConv模块中,下面我们来看这两个。
2.4 AtomEncoder与 BondEncoder
AtomEncoder 用于得到节点表征的第0层,也就是将节点的类别表征进行转换,BondEncoder用于将类别型边属性转换为边表征,也是进行了一个转换,可见二者是类似的作用。在当前的例子中,节点和边的属性都为离散值,它们属于不同的空间,无法直接将它们融合在一起。通过嵌入(Embedding),我们可以将节点属性和边属性分别映射到一个新的空间,在这个新的空间中,我们就可以对节点和边进行信息融合。
import torch
from ogb.utils.features import get_atom_feature_dims, get_bond_feature_dims
full_atom_feature_dims = get_atom_feature_dims()
full_bond_feature_dims = get_bond_feature_dims()
class AtomEncoder(torch.nn.Module):
def __init__(self, emb_dim):
super(AtomEncoder, self).__init__()
self.atom_embedding_list = torch.nn.ModuleList()
for i, dim in enumerate(full_atom_feature_dims):
emb = torch.nn.Embedding(dim, emb_dim)
torch.nn.init.xavier_uniform_(emb.weight.data)
self.atom_embedding_list.append(emb)
def forward(self, x):
x_embedding = 0
for i in range(x.shape[1]):
x_embedding += self.atom_embedding_list[i](x[:,i])
return x_embedding
class BondEncoder(torch.nn.Module):
def __init__(self, emb_dim):
super(BondEncoder, self).__init__()
self.bond_embedding_list = torch.nn.ModuleList()
for i, dim in enumerate(full_bond_feature_dims):
emb = torch.nn.Embedding(dim, emb_dim)
torch.nn.init.xavier_uniform_(emb.weight.data)
self.bond_embedding_list.append(emb)
def forward(self, edge_attr):
bond_embedding = 0
for i in range(edge_attr.shape[1]):
bond_embedding += self.bond_embedding_list[i](edge_attr[:,i])
return bond_embedding
if __name__ == '__main__':
from loader import GraphClassificationPygDataset
dataset = GraphClassificationPygDataset(name = 'tox21')
atom_enc = AtomEncoder(100)
bond_enc = BondEncoder(100)
print(atom_enc(dataset[0].x))
print(bond_enc(dataset[0].edge_attr))
代码中的AtomEncoder类,将节点属性映射到一个新的空间:
full_atom_feature_dims是一个链表list,存储了节点属性向量每一维可能取值的数量,即X[i]可能的取值一共有full_atom_feature_dims[i]种情况,X为节点属性;- 节点属性有多少维,那么就需要有多少个嵌入函数,通过调用
torch.nn.Embedding(dim, emb_dim)可以实例化一个嵌入函数; torch.nn.Embedding(dim, emb_dim),第一个参数dim为被嵌入数据可能取值的数量,第一个参数emb_dim为要映射到的空间的维度。得到的嵌入函数接受一个大于0小于dim的数,输出一个维度为emb_dim的向量。嵌入函数也包含可训练参数,通过对神经网络的训练,嵌入函数的输出值能够表达不同输入值之间的相似性。- 在
forward()函数中,我们对不同属性值得到的不同嵌入向量进行了相加操作,实现了将节点的的不同属性融合在一起。
参考:
- DataWhale开源内容