DLF +DDI 一站式数据湖构建与分析最佳实践
简介: 本文由阿里云数据湖构建 DLF 团队和 Databricks 数据洞察团队联合撰写,旨在帮助您更深入地了解阿里云数据湖构建(DLF)+Databricks 数据洞察(DDI)构建一站式云上数据入湖。
作者
陈鑫伟(熙康),阿里云 计算平台事业部 技术专家
冯加亮(加亮),阿里云 计算平台事业部 技术研发
背景
随着数据时代的不断发展,数据量爆发式增长,数据形式也变的更加多样。传统数据仓库模式的成本高、响应慢、格式少等问题日益凸显。于是拥有成本更低、数据形式更丰富、分析计算更灵活的数据湖应运而生。
数据湖作为一个集中化的数据存储仓库,支持的数据类型具有多样性,包括结构化、半结构化以及非结构化的数据,数据来源上包含数据库数据、binglog 增量数据、日志数据以及已有数仓上的存量数据等。数据湖能够将这些不同来源、不同格式的数据集中存储管理在高性价比的存储如 OSS 等对象存储中,并对外提供统一的数据目录,支持多种计算分析方式,有效解决了企业中面临的数据孤岛问题,同时大大降低了企业存储和使用数据的成本。
数据湖架构及关键技术
企业级数据湖架构如下:
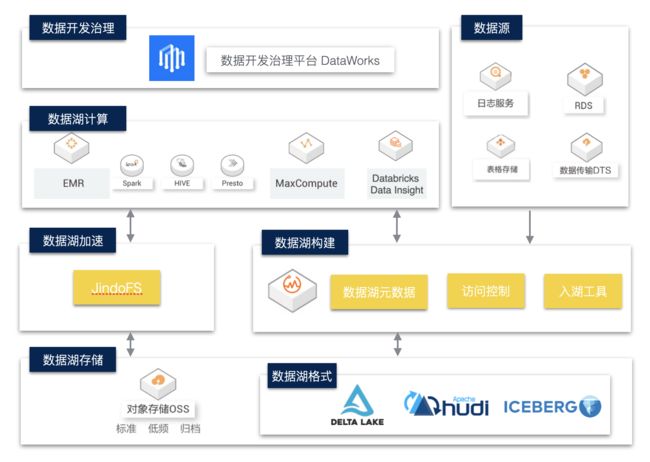
数据湖存储与格式
数据湖存储主要以云上对象存储作为主要介质,其具有低成本、高稳定性、高可扩展性等优点。
数据湖上我们可以采用支持 ACID 的数据湖存储格式,如 Delta Lake、Hudi、Iceberg。这些数据湖格式有自己的数据 meta 管理能力,能够支持 Update、Delete 等操作,以批流一体的方式解决了大数据场景下数据实时更新的问题。在当前方案中,我们主要介绍Delta Lake的核心能力和应用场景。
Delta Lake 的核心能力
Delta Lake 是一个统一的数据管理系统,为云上数据湖带来数据可靠性和快速分析。Delta Lake 运行在现有数据湖之上,并且与 Apache Spark 的 API 完全兼容。使用Delta Lake,您可以加快高质量数据导入数据湖的速度,团队也可以在云服务上快速使用这些数据,安全且可扩展。
- ACID 事务性:Delta Lake 在多个写操作之间提供 ACID 事务性。每一次写操作都是一个事务操作,事务日志(Transaction Log)中记录的写操作都有一个顺序序列。事务日志(Transaction Log)跟踪了文件级别的写操作,并使用了乐观锁进行并发控制,这非常适用于数据湖,因为尝试修改相同文件的多次写操作的情况并不经常发生。当发生冲突时,Delta Lake 会抛出一个并发修改异常,抛给供用户处理并重试其作业。Delta Lake 还提供了最高级别的隔离(可序列化隔离),允许工程师不断地向目录或表写入数据,而使用者不断地从同一目录或表读取数据,读取数据时会看到数据的最新快照。
- Schema 管理(Schema management):Delta Lake 会自动验证正在写入的DataFrame 的 Schema 是否与表的 Schema 兼容。若表中存在但 DataFrame 中不存在的列则会被设置为 null。如果 DataFrame 中有额外的列不在表中,那么该操作将会抛出异常。Delta Lake 具有 DDL(数据定义语言)显式添加新列的功能,并且能够自动更新 Schema。
- 可伸缩的元数据(Metadata)处理:Delta Lake 将表或目录的元数据信息存储在事务日志(Transaction Log)中,而不是元数据 Metastore 中。这使得 Delta Lake够在固定时间内列出大目录中的文件,并且在读取数据时效率很高。
- 数据版本控制和时间旅行(Time Travel):Delta Lake 允许用户读取表或目录的历史版本快照。当文件在写入过程中被修改时,Delta Lake 会创建文件的新的版本并保留旧版本。当用户想要读取表或目录的较旧版本时,他们可以向 Apach Spark的 read API 提供时间戳或版本号,Delta Lake 根据事务日志(Transaction Log)中的信息来构建该时间戳或版本的完整快照。这非常方便用户来复现实验和报告,如果需要,还可以将表还原为旧版本。
- 统一批流一体:除了批处理写入之外,Delta Lake 还可以作为 Apache Spark 的结构化流的高效流接收器(Streaming Sink)。与 ACID 事务和可伸缩元数据处理相结合,高效的流接收器(Streaming Sink)支持大量近实时的分析用例,而无需维护复杂的流和批处理管道。
- 记录更新和删除:Delta Lake 将支持合并、更新和删除的 DML(数据管理语言)命令。这使得工程师可以轻松地在数据湖中插入和删除记录,并简化他们的变更数据捕获和 GDPR(一般数据保护条例)用例。由于 Delta Lake 在文件级粒度上进行跟踪和修改数据,因此它比读取和覆盖整个分区或表要高效得多。
数据湖构建与管理
1. 数据入湖
企业的原始数据存在于多种数据库或存储系统,如关系数据库 MySQL、日志系统SLS、NoSQL 存储 HBase、消息数据库 Kafka 等。其中大部分的在线存储都面向在线事务型业务,并不适合在线分析的场景,所以需要将数据以无侵入的方式同步至成本更低且更适合计算分析的对象存储。
常用的数据同步方式有基于 DataX、Sqoop 等数据同步工具做批量同步;同时在对于实时性要求较高的场景下,配合使用 Kafka+spark Streaming / flink 等流式同步链路。目前很多云厂商提供了一站式入湖的解决方案,帮助客户以更快捷更低成本的方式实现数据入湖,如阿里云 DLF 数据入湖。
2. 统一元数据服务
对象存储本身是没有面向大数据分析的语义的,需要结合 Hive Metastore Service 等元数据服务为上层各种分析引擎提供数据的 Meta 信息。数据湖元数据服务的设计目标是能够在大数据引擎、存储多样性的环境下,构建不同存储系统、格式和不同计算引擎统一元数据视图,并具备统一的权限、元数据,且需要兼容和扩展开源大数据生态元数据服务,支持自动获取元数据,并达到一次管理多次使用的目的,这样既能够兼容开源生态,也具备极大的易用性。
数据湖计算与分析
相比于数据仓库,数据湖以更开放的方式对接多种不同的计算引擎,如传统开源大数据计算引擎 Hive、Spark、Presto、Flink 等,同时也支持云厂商自研的大数据引擎,如阿里云 MaxCompute、Hologres 等。在数据湖存储与计算引擎之间,一般还会提供数据湖加速的服务,以提高计算分析的性能,同时减少带宽的成本和压力。

Databricks 数据洞察-商业版的 Spark 数据计算与分析引擎
DataBricks 数据洞察(DDI)做为阿里云上全托管的 Spark 分析引擎,能够简单快速帮助用户对数据湖的数据进行计算与分析。
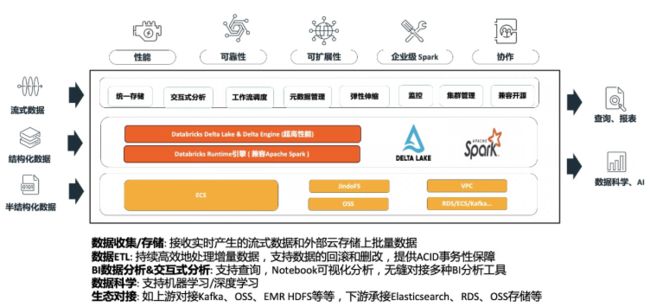
- Saas 全托管 Spark:免运维,无需关注底层资源情况,降低运维成本,聚焦分析业务
- 完整 Spark 技术栈集成:一站式集成 Spark 引擎和 Delta Lake 数据湖,100%兼容开源 Spark 社区版;Databricks 做商业支持,最快体验 Spark 最新版本特性
- 总成本降低:商业版本 Spark 及 Delta Lake 性能优势显著;同时基于计算存储分离架构,存储依托阿里云 OSS 对象存储,借助阿里云 JindoFS 缓存层加速;能够有效降低集群总体使用成本
- 高品质支持以及 SLA 保障:阿里云和 Databricks 提供覆盖 Spark 全栈的技术支持;提供商业化 SLA 保障与7*24小时 Databricks 专家支持服务
Databricks 数据洞察+ DLF 数据湖构建与流批一体分析实践
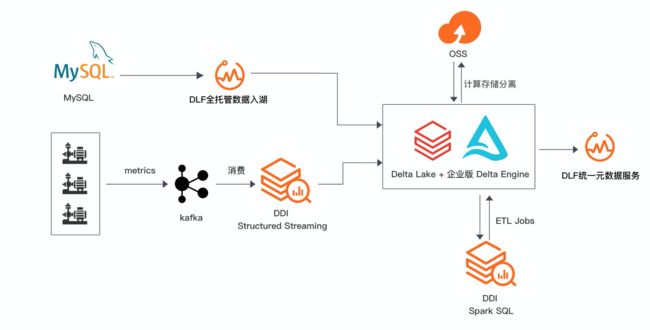
企业构建和应用数据湖一般需要经历数据入湖、数据湖存储与管理、数据湖探索与分析等几个过程。本文主要介绍基于阿里云数据湖构建(DLF)+Databricks 数据洞察(DDI)构建一站式的数据入湖,批流一体数据分析实战。
流处理场景:
实时场景维护更新两张 Delta 表:
- delta_aggregates_func 表:RDS 数据实时入湖 。
- delta_aggregates_metrics 表:工业 metric 数据通过 IoT 平台采集到云 Kafka ,经由 Spark Structured Streaming 实时入湖。
批处理场景:
以实时场景生成两张 Delta 作为数据源,进行数据分析执行 Spark jobs,通过 Databrick 数据洞察作业调度定时执行。
前置条件
1. 服务开通
确保 DLF、OSS、Kafka、DDI、RDS、DTS 等云产品服务已开通。注意 DLF、RDS、Kafka、DDI 实例均需在同一 Region 下。
2. RDS 数据准备
RDS 数据准备,在 RDS 中创建数据库 dlfdb。在账户中心创建能够读取 engine_funcs数据库的用户账号,如 dlf_admin。

通过 DMS 登录数据库,运行一下语句创建 engine_funcs 表,及插入少量数据。
CREATE TABLE `engine_funcs` ( `emp_no` int(11) NOT NULL, `engine_serial_number` varchar(20) NOT NULL, `engine_serial_name` varchar(20) NOT NULL, `target_engine_serial_number` varchar(20) NOT NULL, `target_engine_serial_name` varchar(20) NOT NULL, `operator` varchar(16) NOT NULL, `create_time` DATETIME NOT NULL, `update_time` DATETIME NOT NULL, PRIMARY KEY (`emp_no`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 INSERT INTO `engine_funcs` VALUES (10001,'1107108133','temperature','1107108144','temperature','/', now(), now()); INSERT INTO `engine_funcs` VALUES (10002,'1107108155','temperature','1107108133','temperature','/', now(), now()); INSERT INTO `engine_funcs` VALUES (10003,'1107108155','runTime','1107108166','speed','/', now(), now()); INSERT INTO `engine_funcs` VALUES (10004,'1107108177','pressure','1107108155','electricity','/', now(), now()); INSERT INTO `engine_funcs` VALUES (10005,'1107108188','flow' ,'1107108111','runTime','/', now(), now());
RDS数据实时入湖
1. 创建数据源
- 进入 DLF 控制台界面:https://dlf.console.aliyun.com/cn-hangzhou/home,点击菜单 数据入湖 -> 数据源管理。
- 点击 新建数据源。填写连接名称,选择数据准备中的使用的 RDS 实例,填写账号密码,点击“连接测试”验证网络连通性及账号可用性。
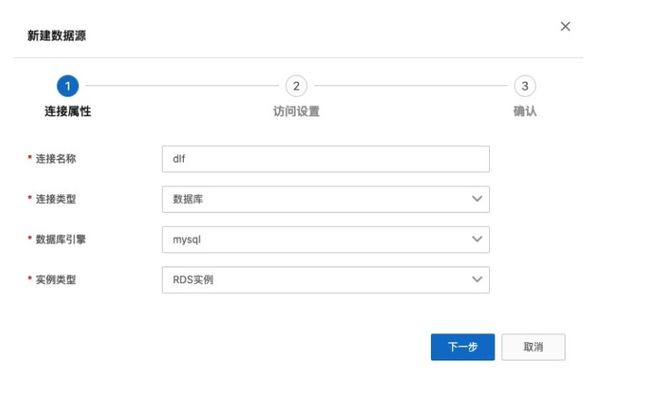
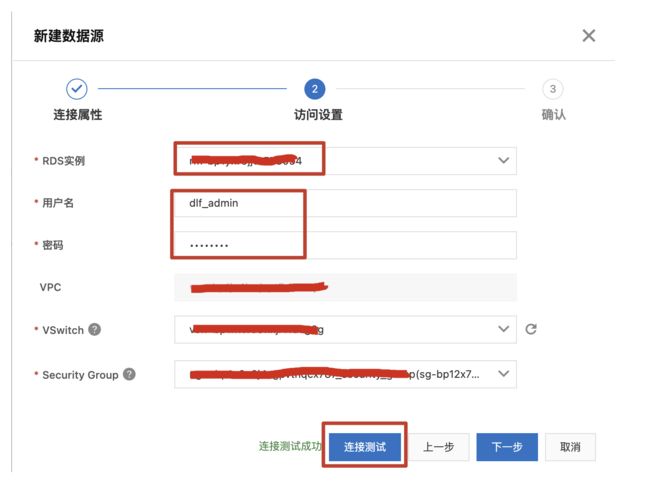
- 点击下一步,确定,完成数据源创建。
2. 创建元数据库
在 OSS 中新建 Bucket,databricks-data-source;
点击左侧菜单“元数据管理”->“元数据库”,点击“新建元数据库”。填写名称,新建目录 dlf/,并选择。
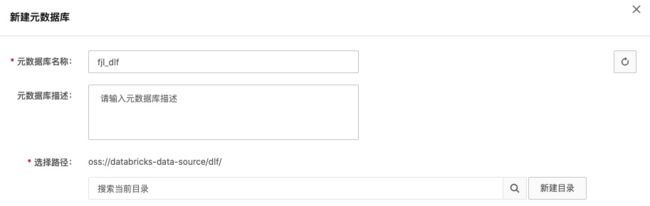
3. 创建入湖任务
- 点击菜单“数据入湖”->“入湖任务管理”,点击“新建入湖任务”。
- 选择“关系数据库实时入湖”,按照下图的信息填写数据源、目标数据湖、任务配置等信息。并保存。
- 配置数据源,选择刚才新建的“dlf”连接,使用表路径 “dlf/engine_funcs”,选择新建 dts 订阅,填写名称。
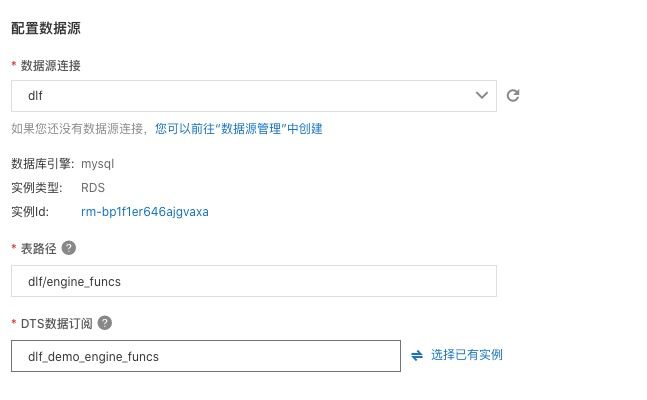
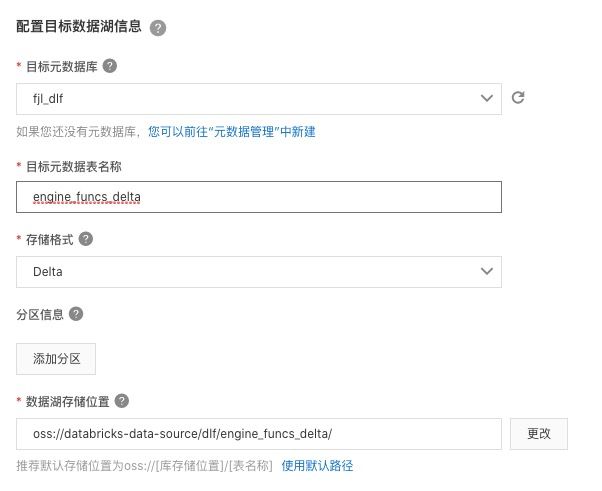
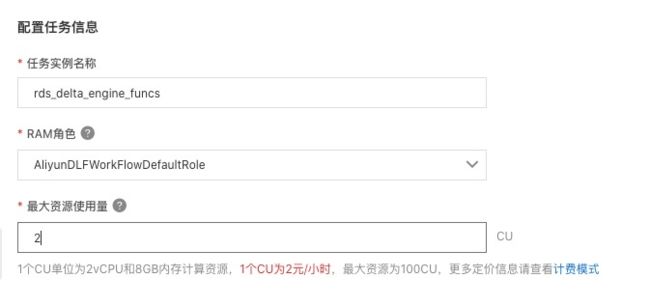
- 回到任务管理页面,点击“运行”新建的入湖任务。就会看到任务进入“初始化中”状态,随后会进入“运行”状态。
- 点击“详情”进入任务详情页,可以看到相应的数据库表信息。

该数据入湖任务,属于全量+增量入湖,大约3至5分钟后,全量数据会完成导入,随后自动进入实时监听状态。如果有数据更新,则会自动更新至 Delta Lake 数据中。
数据湖探索与分析
DLF 数据查询探索
DLF 产品提供了轻量级的数据预览和探索功能,点击菜单“数据探索”->“SQL 查询”进入数据查询页面。
在元数据库表中,找到“fjl_dlf”,展开后可以看到 engine_funcs_delta 表已经自动创建完成。双击该表名称,右侧 sql 编辑框会出现查询该表的 sql 语句,点击“运行”,即可获得数据查询结果。
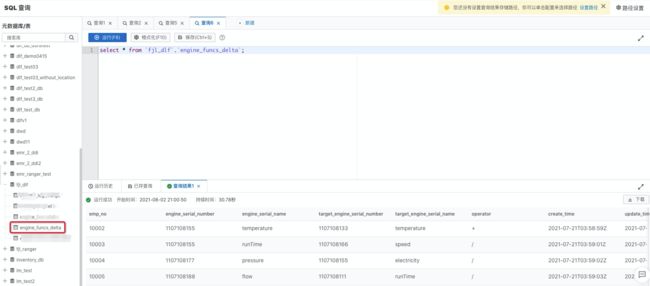
回到 DMS 控制台,运行下方 DELETE 和 INSERT SQL 语句。
DELETE FROM `engine_funcs` where `emp_no` = 10001; UPDATE `engine_funcs` SET `operator` = '+', `update_time` = NOW() WHERE `emp_no` =10002; INSERT INTO `engine_funcs` VALUES (20001,'1107108199','speed','1107108122','runTime','*', now(), now());
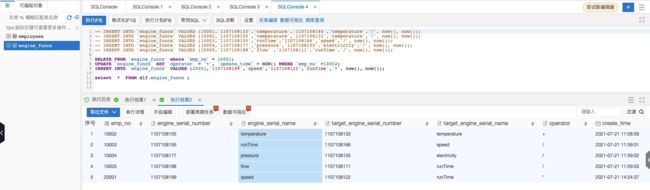
大约1至3分钟后,在 DLF 数据探索再次执行刚才的 select 语句,所有的数据更新已经同步至数据湖中。
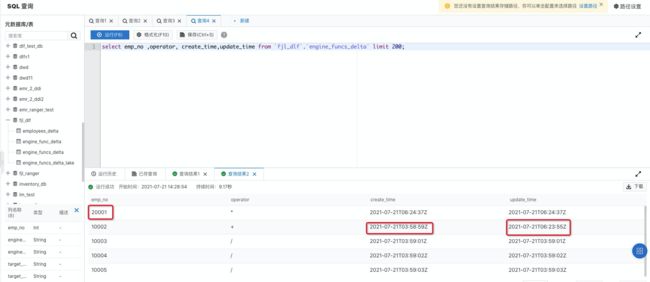
创建 Databricks 数据洞察(DDI)集群

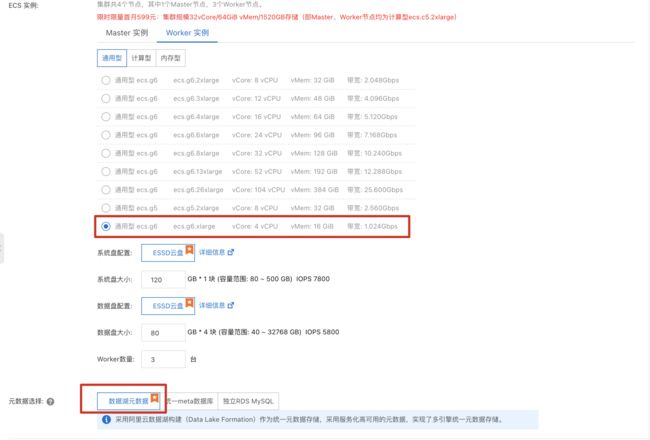
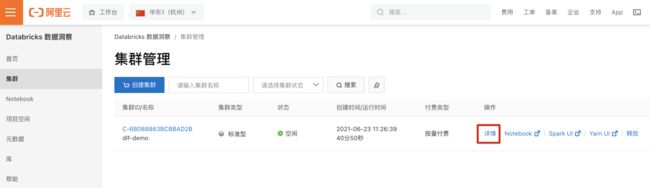
- 集群创建完成后,点击“详情”进入详情页,添加当前访问机器 ip 白名单。
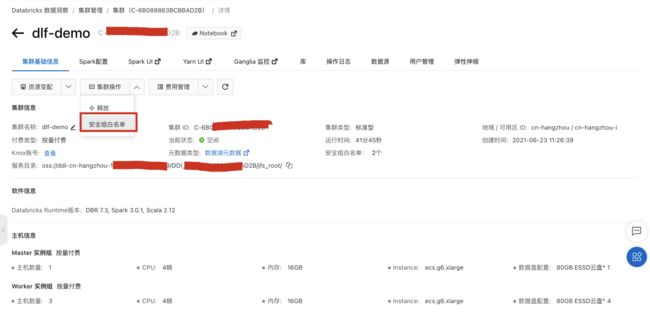
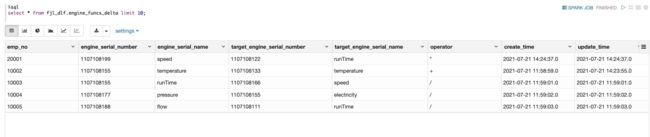
- 点击 Notebook 进入交互式分析页查询同步至 Delta Lake 中 engine_funcs_delta 表数据。
IoT 平台采集到云 Kafka 数据实时写入 Delta Lake
1.引入 spark-sql-kafka 三方依赖
%spark.conf spark.jars.packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1
2.使用 UDF 函数定义流数据写入 Delta Lake 的 Merge 规则
发往 Kafka 的测试数据的格式:
{"sn": "1107108111","temperature": "12" ,"speed":"1115", "runTime":"160","pressure":"210","electricity":"380","flow":"740","dia":"330"}
{"sn": "1107108122","temperature": "13" ,"speed":"1015", "runTime":"150","pressure":"220","electricity":"390","flow":"787","dia":"340"}
{"sn": "1107108133","temperature": "14" ,"speed":"1215", "runTime":"140","pressure":"230","electricity":"377","flow":"777","dia":"345"}
{"sn": "1107108144","temperature": "15" ,"speed":"1315", "runTime":"145","pressure":"240","electricity":"367","flow":"730","dia":"430"}
{"sn": "1107108155","temperature": "16" ,"speed":"1415", "runTime":"155","pressure":"250","electricity":"383","flow":"750","dia":"345"}
{"sn": "1107108166","temperature": "10" ,"speed":"1515", "runTime":"145","pressure":"260","electricity":"350","flow":"734","dia":"365"}
{"sn": "1107108177","temperature": "12" ,"speed":"1115", "runTime":"160","pressure":"210","electricity":"377","flow":"733","dia":"330"}
{"sn": "1107108188","temperature": "13" ,"speed":"1015", "runTime":"150","pressure":"220","electricity":"381","flow":"737","dia":"340"}
{"sn": "1107108199","temperature": "14" ,"speed":"1215", "runTime":"140","pressure":"230","electricity":"378","flow":"747","dia":"345"}
%spark
import org.apache.spark.sql._
import io.delta.tables._
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
microBatchOutputDF.createOrReplaceTempView("dataStream")
// 对流数据DF执行列转行的操作;
val df=microBatchOutputDF.sparkSession.sql(s"""
select `sn`,
stack(7, 'temperature', `temperature`, 'speed', `speed`, 'runTime', `runTime`, 'pressure', `pressure`, 'electricity', `electricity`, 'flow', `flow` , 'dia', `dia`) as (`name`, `value` )
from dataStream
""")
df.createOrReplaceTempView("updates")
// 实现实时更新动态的数据,结果merge到表里面
val mergedf=df.sparkSession.sql(s"""
MERGE INTO delta_aggregates_metrics t
USING updates s
ON s.sn = t.sn and s.name=t.name
WHEN MATCHED THEN UPDATE SET
t.value = s.value,
t.update_time=current_timestamp()
WHEN NOT MATCHED THEN INSERT
(t.sn,t.name,t.value ,t.create_time,t.update_time)
values (s.sn,s.name,s.value,current_timestamp(),current_timestamp())
""")
}
3.使用 Spark Structured Streaming 实时流写入 Delta Lake
%spark
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.Trigger
def getquery(checkpoint_dir:String,servers:String,topic:String ){
var streamingInputDF =
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", servers)
.option("subscribe", topic)
.option("startingOffsets", "latest")
.option("minPartitions", "10")
.option("failOnDataLoss", "true")
.load()
var streamingSelectDF =
streamingInputDF
.select(
get_json_object(($"value").cast("string"), "$.sn").alias("sn"),
get_json_object(($"value").cast("string"), "$.temperature").alias("temperature"),
get_json_object(($"value").cast("string"), "$.speed").alias("speed"),
get_json_object(($"value").cast("string"), "$.runTime").alias("runTime"),
get_json_object(($"value").cast("string"), "$.electricity").alias("electricity"),
get_json_object(($"value").cast("string"), "$.flow").alias("flow"),
get_json_object(($"value").cast("string"), "$.dia").alias("dia"),
get_json_object(($"value").cast("string"), "$.pressure").alias("pressure")
)
val query = streamingSelectDF
.writeStream
.format("delta")
.option("checkpointLocation", checkpoint_dir)
.trigger(Trigger.ProcessingTime("5 seconds")) // 执行流处理时间间隔
.foreachBatch(upsertToDelta _) //引用upsertToDelta函数
.outputMode("update")
.start()
}
4. 执行程序
%spark val my_checkpoint_dir="oss://databricks-data-source/checkpoint/ck" val servers= "***.***.***.***:9092" val topic= "your-topic" getquery(my_checkpoint_dir,servers,topic)
5. 启动 Kafka 并向生产里发送测试数据

- 查询数据实时写入并更新
- 查询从 MySQL 实时同步入湖的 engine_funcs_delta 数据
%spark
val rds_dataV=spark.table("fjl_dlf.engine_funcs_delta")
rds_dataV.show()

批处理作业
结合业务,需要将对应的 delta_aggregates_metrics 里的 Value 参数 join 到engine_funcs_delta 表里
%spark
//读取实时更新的delta_aggregates_metrics数据表
val aggregateDF=spark.table("log_data_warehouse_dlf.delta_aggregates_metrics")
//读取实时更新的engine_funcs_delta函数表
val rds_dataV=spark.table("fjl_dlf.engine_funcs_delta").drop("create_time","update_time")
// rds_dataV.show()
val aggregateSDF= aggregateDF.withColumnRenamed("value","esn_value").withColumnRenamed("name","engine_serial_name").withColumnRenamed("sn","engine_serial_number")
// aggregateSDF.show()
val aggregateTDF=aggregateDF.withColumnRenamed("value","tesn_value").withColumnRenamed("name","target_engine_serial_name").withColumnRenamed("sn","target_engine_serial_number").drop("create_time","update_time")
// aggregateTDF.show()
//将对应的delta_aggregates_metrics里的Value参数 join到engine_funcs_delta表里;
val resdf=rds_dataV.join(aggregateSDF,Seq("engine_serial_name","engine_serial_number"),"left").join(aggregateTDF,Seq("target_engine_serial_number","target_engine_serial_name"),"left")
.selectExpr("engine_serial_number","engine_serial_name","esn_value","target_engine_serial_number","target_engine_serial_name","tesn_value","operator","create_time","update_time")
//数据展示
resdf.show(false)
// 将结果写入到Delta表里面
resdf.write.format("delta")
.mode("append")
.saveAsTable("log_data_warehouse_dlf.delta_result")

性能优化:OPTIMIZE & Z-Ordering
在流处理场景下会产生大量的小文件,大量小文件的存在会严重影响数据系统的读性能。Delta Lake 提供了 OPTIMIZE 命令,可以将小文件进行合并压缩,另外,针对 Ad-Hoc 查询场景,由于涉及对单表多个维度数据的查询,我们借助 Delta Lake 提供的 Z-Ordering 机制,可以有效提升查询的性能。从而极大提升读取表的性能。DeltaLake 本身提供了 Auto Optimize 选项,但是会牺牲少量写性能,增加数据写入 delta 表的延迟。相反,执行 OPTIMIZE 命令并不会影响写的性能,因为 Delta Lake 本身支持 MVCC,支持 OPTIMIZE 的同时并发执行写操作。因此,我们采用定期触发执行 OPTIMIZE 的方案,每小时通过 OPTIMIZE 做一次合并小文件操作,同时执行 VACCUM 来清理过期数据文件:
OPTIMIZE log_data_warehouse_dlf.delta_result ZORDER by engine_serial_number; VACUUM log_data_warehouse_dlf.delta_result RETAIN 1 HOURS;
原文链接
本文为阿里云原创内容,未经允许不得转载。