基于统计学习---面向新闻的发生地与提及地检测
基于统计学习---面向新闻的发生地与提及地检测
- 一、摘要
-
- 二、流程
-
- 2.1- 数据构建及数据预处理
- 2.2- 全国5级地址实体二叉树
- 2.3- 命名实体识别相关算法
- 2.4- 新闻中特征信息分析
- 2.5-基于多个特征融合设计权重公式
- 三、总结
一、摘要
从新闻中抽取出的发生地对于舆论溯源与检索信息都有所帮助,目前针对发生地抽取的研究较少,大部分学者致力于抽取出新闻中包含的地名或是新闻事件的抽取。命名实体识别技术无法判断哪个地名是新闻发生地,而新闻事件的抽取无法保证一定能抽取出所有的事件要素。因此,本文针对抽取出新闻发生地这一研究任务,为其构造了多个不同的特征,并进行发生地与提及地抽取。
二、流程
- 对文本进行预处理
- 构建全国地址实体2叉树
- 新闻中所有地名的实体识别
- 新闻中特征信息分析
- 基于多个特征融合设计权重公式
2.1- 数据构建及数据预处理
笔者数据来源为各大新闻网站爬取得到的1035932条新闻文本。
从篇幅上看,这些新闻网站中的新闻文本长短不一,有的仅包含几句话,有的篇幅较长。
从新闻类别上看,包含社会、科技、生活方式、财经、时政、健康、房产、旅游、体育、教育、美食、育儿、文化等多种类别,并且其分布较为均匀。
数据处理上笔者将文章标题与正文使用正则清洗非中文文本,并将文章以\n \t !。??!切分为句子粒度。
后续会使命名实体识别算法对文章句子进行实体识别任务。
''':param
title:文章标题
text:文章正文
sentence_list:包含标题在内的文章内容
sentence_num:不包含标题的句子总数
'''
sentence_list = [title+'。']
for sent in re.findall('(?<=[!。??!\t\n])[^!。??!\t\n]*?[!。??!\t\n]+', '。' + text):
if len(re.sub(
u'[^\n\t\r.\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a|\u3002|\uff1f|\uff01|\uff0c|\u3001|\uff1b|\uff1a|\u201c|\u201d|\u2018|\u2019|\uff08|\uff09|\u300a|\u300b|\u3008|\u3009|\u3010|\u3011|\u300e|\u300f|\u300c|\u300d|\ufe43|\ufe44|\u3014|\u3015|\u2026|\u2014|\uff5e|\ufe4f|\uffe5]',
'', sent)) > 0:
sentence_list.extend([sent])
sentences_num = len(sentence_list)
return sentence_list, sentences_num
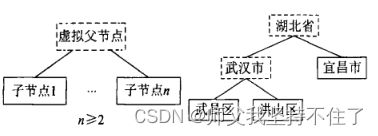
2.2- 全国5级地址实体二叉树
1. 地名树的生成应有子节点(较低行政级别)向上扩展。为减少查询次数,应将数据按照行政级别高低存储。
2. 基于行政隶属关系的带有虚拟父节点的地名树生成如下图。
3. 地名树的构建解决我们后续通过NER算法识别到的LOC实体进行层级逆推。
举个栗子: 文章经过 NER 算法得到LOC实体,如文章中识别到LOC实体为(杭州市,LOC),但我们最终需要的是全路径地址,所以需要依赖二叉树去寻找上级,当然也可以通过构建地名实体知识图谱去实现。
2.3- 命名实体识别相关算法
1. 本文的发生地提及地抽取需要在地名识别的基础上完成,因此,本文首先需对新闻文本进行地名识别,识别出新闻中的所有地名,而后通过这些地名进行全路径地址逆推。
2. 目前流行的命名实体识别的算法是提条件随机场算法,其识别准确率较高。但也有很多神经网络与CRF相结合的方法,例如:LSTM+CRF或者预训练模型BERT+CRF能够在某些数据集上提高实体识别的准确率,但笔者考虑到识别速度,故选择使用CRF。
3. 随着CRF的广泛使用,出现了CRF++的方法,该方法可以人工定义特征模板,为使用CRF模型提供了极大的便利。
HMM 模型认为基于观察序列中的每个元素都是相互条件独立的。这个假设会导致 HMM 模型无法处理一些需要上下文信息的问题,而 CRF的出现较好的解决了这个问题。CRF 的本质是给定了观察值集合的马尔可夫随机场,与 HMM 模型对比,二者的节点均具有马尔科夫性,但 CRF 在这个基础上考虑了前文对当前词的影响,从而在需要上下文信息的场景中占据一定优势。
备注: 通用实体的训练语料(笔者使用开源的API标注投票获得) , 点击CRF++工具包下载即可。
def nerExtract(text):
# 形成预测样本
tagger.clear()
for word in text:
tagger.add("{} B-char".format(word))
tagger.parse()
size = tagger.size()
# 获取模型预测标签
predict_tags = [tagger.y2(i) for i in range(0, size)]
# 输出预测结果
entity = ''
entity_type = 'O'
EntityList = list()
first_flg = False
for char, tag in zip(text, predict_tags):
# print("{}\t{}".format(char, tag))
if tag.startswith('B-'):
if first_flg == False:
entity_type = tag.replace('B-', '')
entity = char
first_flg = True
else:
if entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if entity not in blacklist_address_word or not (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$",
entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
entity_type = tag.replace('B-', '')
entity = char
elif tag.startswith('I-'):
entity += char
entity_type = tag.replace('I-', '')
else:
if tag == 'O' and entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if entity not in blacklist_address_word or not (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$",
entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
entity = ''
entity_type = 'O'
if tag != 'O' and entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if (len(entity) > 1 and entity not in blacklist_address_word) or (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$", entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
return EntityList
2.4- 新闻中特征信息分析
1. 地点频次特征: 将地名在文中出现的频次作为一个特征是一个很自然的想法。在新闻中如果某地名出 现的频次高于其他地名,那么这个地名是发生地的概率也就越大。
2. 地名实体在文章中所属句子位置特征:文章中发生地地名基本都在文章中靠前位置的句子中出现,所以句子索引位置需要考虑进去。
3. 句子标题中出现: 如果文章标题中带了一个地名,也可以认为与发生地高度相关,那我们可以将该实体权重适当抬高。
4. 句子与标题的相对距离特征:在新闻文本中,人们习惯于在文章的“前端”即文章的前几句话中提及文章的中心思想,因此,人们总可以在文章的前两段甚至前一段中得到文章所描述的主旨,进而得到发生地。在此情况下,假设如果在文章的前几句话中出现了地名词,那这个地名是发生地的概率会大于在其后篇章中出现的地名的概率。
5. 句子与标题相似度: 我们知道,标题是新闻文本内容的概括,一般表达了其新闻内容的精华,从标题中就可以获悉一篇文章主题,因此,标题对于新闻体裁的文本而言是一个重要的帮助识别中心句的特征。标题中如果出现了地名,那么该地名是发生地概率将远大于该地名不是发生地的概率,标题中不一定包含地名,因此,如果从新闻中抽取出与标题相似度高的句子,且该句子包含了地名,那么该地名是发生地的概率也将提高,通过上述分析将问题转化为计算句子与标题之间的相似度并将此作为提取发生地的特征之一。
6. 当然也可以考虑相邻句子的相似度等特征。
2.5-基于多个特征融合设计权重公式
1. 有了上面的特征信息我们可以设计一个概率计算公式: P r o b = 1 l e n ( b p L i s t ) ⋅ W e i g h t s Prob = \frac{1}{{len(bpList)}} \cdot Weights Prob=len(bpList)1⋅Weights
2. 对权重公式的设计: W e i g h t s = 2 1 + ( 0.335 × l e n ( b p L i s t ) 3 × e n t i t y C o u n t × ( 1 − log ( e n t i t y s e n t _ _ _ _ _ _ _ _ _ _ _ ) ) l e n ( s e n t L i s t ) Weights = \frac{2}{{1 + (0.335 \times len{{(bpList)}^3}}} \times \frac{{\mathop {entity}\nolimits_{Count} \times (1 - \log (\mathop {entit{y_{sent}}}\limits^{\_\_\_\_\_\_\_\_\_\_\_} ))}}{{len(sentList)}} Weights=1+(0.335×len(bpList)32×len(sentList)entityCount×(1−log(entitysent___________))
- l e n ( b p L i s t ) {len(bpList)} len(bpList) 表示逆推全路径地址的个数
- e n t i t y C o u n t {\mathop {entity}\nolimits_{Count} } entityCount 表示实体频次
- e n t i t y s e n t _ _ _ _ _ _ _ _ _ _ _ {\mathop {entit{y_{sent}}}\limits^{\_\_\_\_\_\_\_\_\_\_\_} } entitysent___________ 表示单篇文章中该实体所在句子号均值
- l e n ( s e n t L i s t ) {len(sentList)} len(sentList) 表示单篇文章的句子总数
def weightFormula(bpList, entityCount, SentenceIndex, totalSentenceNum):
''':param
bpList:逆推全路径地址列表
entityCount:实体频次
SentenceIndex:句子号
totalSentenceNum:该文章句子总数
'''
weight = (2 / (1 + (0.335 * len(bpList)) ** 3)) * entityCount * (
1 - (np.log(np.mean(SentenceIndex) / totalSentenceNum + 1.25)))
''':arg
句子标题中包含该实体 权重相应增大
'''
if 0 in entityInfo_dic[entity2_]['sentence_index']:
weight = 2 * weight
return weight
else:
return weight
def Probability(weight, bpList):
''':param
1.逆推列表中该地址为一级地址则为其本身权重
2.逆推列表中该地址为二级/三级地址 则 (1/(长度-1)) x weight
'''
probability = list(
map(lambda x: round(weight, 3) if len(x) == 1 else round(
weight * (1 / (len(x) - 1)) * (1 / len(bpList)), 3),
bpList))
# 将每个地址 最小级到最大级的得到的概率结果存储为对应列表 例: ["浙江省",0.63]
local_probility = [[bpList[i][0], probability[i]] for i in range(len(bpList))]
return local_probility
三、总结
抽取结果简单展示如下

文本实现了基于统计学习,面向新闻内容的发生地与提及地抽取方法,总体效果基本可以满足! 也可根据该方法进行拓展改进! 例如引入机器学习常见的分类算法及知识图谱等方法。
炼丹路漫漫,山高路远,看世界也找自己! Luofan
# -*-coding:utf-8-*-
'''
File Name:regional_detection_backup5.py
Author:Luofan
'''
import json
import CRFPP
import re
import numpy as np
# 加载模型文件
CRF_MODEL_PATH = "crf_model_5"
tagger = CRFPP.Tagger("-m %s" % CRF_MODEL_PATH)
blacklist_address_word = ['此列表为实体黑名单']
# 地址数据库提前加载
with open("level5.json", "r", encoding="utf-8-sig") as f:
local_database = json.loads(f.read())
# print(local_database['杭州'])
databaseKeys = str(list(local_database.keys()))
def ner_extract(text):
# 形成预测样本
tagger.clear()
for word in text:
tagger.add("{} B-char".format(word))
tagger.parse()
size = tagger.size()
# 获取模型预测标签
predict_tags = [tagger.y2(i) for i in range(0, size)]
# 输出预测结果
entity = ''
entity_type = 'O'
EntityList = list()
first_flg = False
for char, tag in zip(text, predict_tags):
# print("{}\t{}".format(char, tag))
if tag.startswith('B-'):
if first_flg == False:
entity_type = tag.replace('B-', '')
entity = char
first_flg = True
else:
if entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if entity not in blacklist_address_word or not (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$",
entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
entity_type = tag.replace('B-', '')
entity = char
elif tag.startswith('I-'):
entity += char
entity_type = tag.replace('I-', '')
else:
if tag == 'O' and entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if entity not in blacklist_address_word or not (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$",
entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
entity = ''
entity_type = 'O'
if tag != 'O' and entity_type != 'O':
entity = re.sub(u"([\u3000\xa0\t/]+)", '', entity)
if re.match('.*[\u4e00-\u9fa5]+.*', entity) != None:
entity = entity.replace(' ', '')
if entity_type == "PER":
if len(entity) > 1 and re.match(
'^(李|王|张|刘|陈|杨|赵|黄|周|吴|徐|孙|胡|朱|高|林|何|郭|马|罗|梁|宋|郑|谢|韩|唐|冯|于|董|萧|程|曹|袁|邓|许|傅|沈|曾|彭|吕|苏|卢|蒋|蔡|贾|丁|魏|薛|叶|余|潘|杜|戴|夏|钟|汪|田|任|姜|范|方|石|姚|谭|廖|邹|熊|金|陆|郝|孔|白|崔|康|毛|邱|秦|江|史|顾|侯|邵|孟|龙|万|段|漕|钱|汤|尹|黎|易|常|武|乔|贺|赖|龚|文|庞|樊|兰|殷|施|陶|洪|翟|安|颜|倪|严|牛|温|芦|季|俞|章|鲁|葛|伍|韦|申|尤|毕|聂|丛|焦|向|柳|邢|路|岳|齐|沿|梅|莫|庄|辛|管|祝|左|涂|谷|祁|时|舒|耿|卜|路|詹|关|苗|凌|费|纪|靳|盛|童|欧|甄|项|曲|成|游|阳|裴|席|卫|查|屈|鲍|位|覃|霍|翁|隋|植|甘|景|薄|单|包|司|柏|宁|柯|阮|桂|闵|欧阳|解|强|柴|华|车|冉|房|边|辜|吉|饶|刁|瞿|戚|丘|古|米|池|滕|晋|苑|邬|臧|畅|宫|来|嵺|苟|全|褚|廉|简|娄|盖|符|奚|木|穆|党|燕|郎|邸|冀|谈|姬|屠|连|郜|晏|栾|郁|商|蒙|计|喻|揭|窦|迟|宇|敖|糜|鄢|冷|卓|花|仇|艾|蓝|都|巩|稽|井|练|仲|乐|虞|卞|封|竺|冼|原|官|衣|楚|佟|栗|匡|宗|应|台|巫|鞠|僧|桑|荆|谌|银|扬|明|沙|薄|伏|岑|习|胥|保|和|蔺|司马|上官|欧阳|诸葛|东方|皇甫|尉迟|公羊|淳于|公孙|轩辕|令狐|宇文|长孙|慕容|司徒)[\u4e00-\u9fa5]{1,2}',
entity) != None:
EntityList.append((entity, entity_type))
elif entity_type == "LOC":
if (len(entity) > 1 and entity not in blacklist_address_word) or (
len(entity) == 1 and re.match(r"^[京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂琼渝川黔滇藏陕甘青宁新台港澳中美英韩日法德意澳]$", entity) != None):
EntityList.append((entity, entity_type))
else:
EntityList.append((entity, entity_type))
return EntityList
def sentences_num_data(title, text):
''':param
title:文章标题
text:文章正文
sentence_list:包含标题在内的文章内容
sentence_num:不包含标题的句子总数
'''
sentence_list = [title + '。']
for sent in re.findall('(?<=[!。??!\t\n])[^!。??!\t\n]*?[!。??!\t\n]+', '。' + text):
if len(re.sub(
u'[^\n\t\r.\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a|\u3002|\uff1f|\uff01|\uff0c|\u3001|\uff1b|\uff1a|\u201c|\u201d|\u2018|\u2019|\uff08|\uff09|\u300a|\u300b|\u3008|\u3009|\u3010|\u3011|\u300e|\u300f|\u300c|\u300d|\ufe43|\ufe44|\u3014|\u3015|\u2026|\u2014|\uff5e|\ufe4f|\uffe5]',
'', sent)) > 0:
sentence_list.extend([sent])
sentences_num = len(sentence_list)
return sentence_list, sentences_num
def weightFormula(bpList, entityCount, SentenceIndex, totalSentenceNum):
''':param
bpList:逆推全路径地址列表
entityCount:实体频次
SentenceIndex:句子号
totalSentenceNum:该文章句子总数
'''
weight = (2 / (1 + (0.335 * len(bpList)) ** 3)) * entityCount * (
1 - (np.log(np.mean(SentenceIndex) / totalSentenceNum + 1.25)))
''':arg
如果句子标题包含该实体 权重增大
'''
if 0 in entityInfo_dic[entity2_]['sentence_index']:
weight = 2 * weight
return weight
else:
return weight
def Probability(weight, bpList):
''':param
1.逆推列表中该地址为一级地址则为其本身权重
2.逆推列表中该地址为二级/三级地址 则 (1/(长度-1)) x weight
'''
probability = list(
map(lambda x: round(weight, 3) if len(x) == 1 else round(
weight * (1 / (len(x) - 1)) * (1 / len(bpList)), 3),
bpList))
# 将每个地址 最小级到最大级的得到的概率结果存储为对应列表 例: ["浙江省",0.63]
local_probility = [[bpList[i][0], probability[i]] for i in range(len(bpList))]
return local_probility
def City2UrbanPro(entityInfo_dic, local_pro_list):
local_pro_dic = {}
for entity, entityInfo in entityInfo_dic.items():
if entityInfo.get('back_push_list') != None:
New_back_push_list = []
''':arg
剔除 单1省及无关省的全地址
province_pro_list[0][0] 为权重最大省所在的二级市实体
将二级及其往后的实体路径添加至New-back-push—list
保留该实体对应的历史信息(句子号,实体频次)
'''
for proInfo in entityInfo['back_push_list']:
for index in range(len(local_pro_list)):
if len(proInfo) > 1 and proInfo[0] == local_pro_list[index][0]:
New_back_push_list.append(proInfo[1:])
if New_back_push_list != []:
local_pro_dic[entity] = {'sentence_index': []}
local_pro_dic[entity]['sentence_index'] = entityInfo.get('sentence_index')
local_pro_dic[entity]['count'] = entityInfo.get('count')
local_pro_dic[entity]['back_push_list'] = New_back_push_list
return local_pro_dic
def sorted_ouput(entityInfo_dic, local_string):
''':arg
所有实体-->省 其对应概率加和排序
'''
pro_dic = {}
for k, v in entityInfo_dic.items():
if v.get(local_string) is not None:
for proInfo in v[local_string]:
if proInfo[0] not in pro_dic.keys():
pro_dic[proInfo[0]] = proInfo[1]
else:
pro_dic[proInfo[0]] += proInfo[1]
local_sort_list = sorted(pro_dic.items(), key=lambda x: x[1], reverse=True)
return local_sort_list
if __name__ == '__main__':
json_file = open(r'全国党媒公共平台语料汇总.json', encoding='utf-8', errors='ignore')
for index, one_line in enumerate(json_file): # 遍历文件,一行行遍历,读取文本
line_json = json.loads(one_line.strip())
title = line_json['title']
content = line_json['content']
classificationName = line_json['classificationName']
sentences_list, sentences_num = sentences_num_data(title=title, text=content)
entityInfo_dic = {}
for sentence_index, sentence in enumerate(sentences_list):
for entityInfo in ner_extract(sentence):
if entityInfo[1] == 'LOC' and "'" + entityInfo[0] + "'" in databaseKeys and entityInfo[
0] not in blacklist_address_word:
''':arg
统计: 该实体 对应句子索引号('索引号多次出现则去重') 频次
'''
if not entityInfo_dic.get(entityInfo[0]):
entityInfo_dic[entityInfo[0]] = {'sentence_index': [], 'count': 0}
if sentence_index not in entityInfo_dic[entityInfo[0]]['sentence_index']:
entityInfo_dic[entityInfo[0]]['sentence_index'].append(sentence_index)
entityInfo_dic[entityInfo[0]]['count'] += 1
entity2_keys = list(entityInfo_dic.keys())
for entity2_ in entity2_keys:
entity2_result = local_database[entity2_]
# 逆推层级权重
weight = weightFormula(bpList=entity2_result, entityCount=entityInfo_dic[entity2_]['count'],
SentenceIndex=entityInfo_dic[entity2_]['sentence_index'],
totalSentenceNum=sentences_num)
# 逆推最终省权重
province_probility = Probability(weight=weight, bpList=entity2_result)
entityInfo_dic[entity2_]['back_push_list'] = entity2_result
entityInfo_dic[entity2_]['province'] = province_probility
''':arg
针对省-->权重加和 排序输出
'''
province_pro_list = sorted_ouput(entityInfo_dic=entityInfo_dic, local_string='province')
if len(province_pro_list) == 1:
# ---------------------------------------------------------市级-----------------------------------------------
city_pro_dic = City2UrbanPro(entityInfo_dic=entityInfo_dic, local_pro_list=province_pro_list)
city2_result = city_pro_dic.keys()
for city2_entity in city2_result:
# 逆推层级权重
weight = weightFormula(bpList=city_pro_dic[city2_entity]['back_push_list'],
entityCount=city_pro_dic[city2_entity]['count'],
SentenceIndex=city_pro_dic[city2_entity]['sentence_index'],
totalSentenceNum=sentences_num)
city_probability = Probability(weight=weight, bpList=city_pro_dic[city2_entity]['back_push_list'])
city_pro_dic[city2_entity]['city'] = city_probability
''':arg
针对市级-->权重加和 排序输出
'''
city_pro_list = sorted_ouput(entityInfo_dic=city_pro_dic, local_string='city')
# ---------------------------------------------------------区县级-----------------------------------------------
urban_pro_dic = City2UrbanPro(entityInfo_dic=city_pro_dic, local_pro_list=city_pro_list)
city3_result = urban_pro_dic.keys()
for city3_entity in city3_result:
# 逆推层级权重
weight = weightFormula(bpList=urban_pro_dic[city3_entity]['back_push_list'],
entityCount=urban_pro_dic[city3_entity]['count'],
SentenceIndex=urban_pro_dic[city3_entity]['sentence_index'],
totalSentenceNum=sentences_num)
urban_probability = Probability(weight=weight, bpList=urban_pro_dic[city3_entity]['back_push_list'])
urban_pro_dic[city3_entity]['urban'] = urban_probability
''':arg
针对区县级-->权重加和 排序输出
'''
urban_pro_list = sorted_ouput(entityInfo_dic=urban_pro_dic, local_string='urban')
# ---------------------------------------------------------乡镇级-----------------------------------------------
township_pro_dic = City2UrbanPro(entityInfo_dic=urban_pro_dic, local_pro_list=urban_pro_list)
city4_result = township_pro_dic.keys()
for city4_entity in city4_result:
# 逆推层级权重
weight = weightFormula(bpList=township_pro_dic[city4_entity]['back_push_list'],
entityCount=township_pro_dic[city4_entity]['count'],
SentenceIndex=township_pro_dic[city4_entity]['sentence_index'],
totalSentenceNum=sentences_num)
township_probability = Probability(weight=weight,
bpList=township_pro_dic[city4_entity]['back_push_list'])
township_pro_dic[city4_entity]['township'] = township_probability
''':arg
针对区县级-->权重加和 排序输出
'''
township_pro_list = sorted_ouput(entityInfo_dic=township_pro_dic, local_string='township')
local_result = ''
for result in ([province_pro_list, city_pro_list, urban_pro_list, township_pro_list]):
if result:
if result[0]:
local_result += result[0][0]
print('发生地:', local_result)
print('\n文章内容:', content)
print('*' * 220)