人工智能导论
关于这门全是英文的考试,一些注意的知识点(根据ppt和网课)
目录
关于这门全是英文的考试,一些注意的知识点(根据ppt和网课)
一,Knowledge Representation
1.logic
2.FOL
3.semantic network
4.abductive
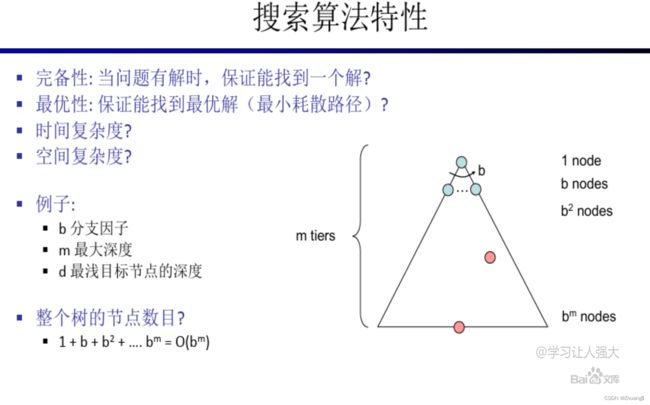
二,Search
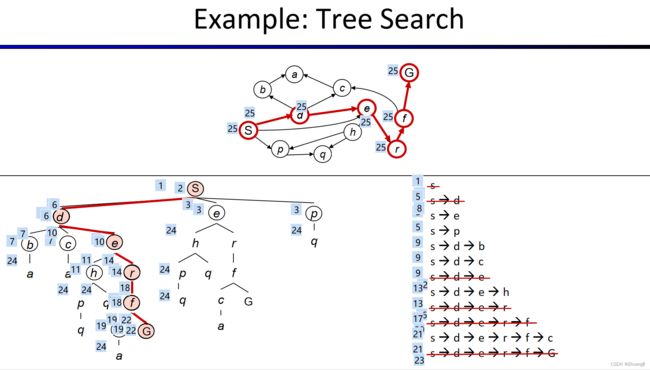
1.DFS
2.BFS
3.DFS和BFS的区别
4.Cost-Sensitive Search:代价敏感搜索
5.Informed Search:启发搜索
三,神经网络
五,试题研究
六,计算题
七,简答题(非标答)
一,Knowledge Representation
知识表示
1.logic
P->Q:
1若:p是真,q是真,则 p→q是真;
2若:p是真,q是假,则 p→q是假;
3若:p是假,q是真,则 p→q是真;
4若:p是假,q是假,则 p→q是真.
2.FOL

例题1:

例题2:选C

对于此题举个其他例子比较:
1)对于宇宙间一切事物而言,如果事物是人,则他要呼吸。
(2)在宇宙间存在着用左手写字的人。
于是(1),(2)的符号化形式分别为
∀x(M(x)→F(x))
和
ョx(M(x)∧G(x))
例题3:如果X是一个矛盾,Y是一个句子,那么X->Y就是一个重言式

例题4:一阶逻辑中有多少个逻辑常数
Infinity:无限

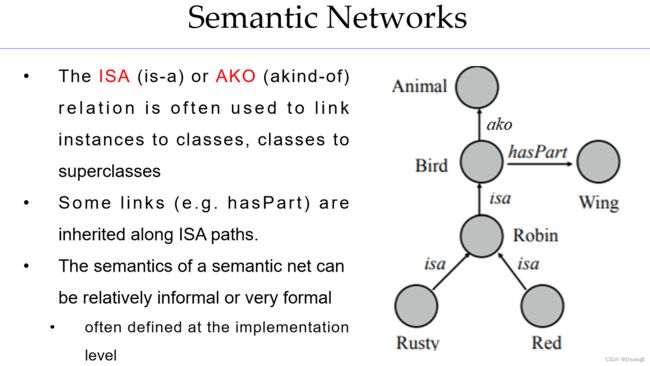
3.semantic network
- 介绍:语义网络
- ppt内容及翻译(下图PPT前三排中文)
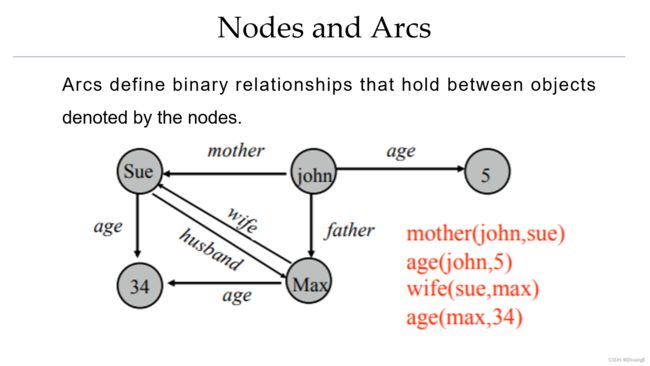
节点和弧
弧定义二进制对象之间的关系
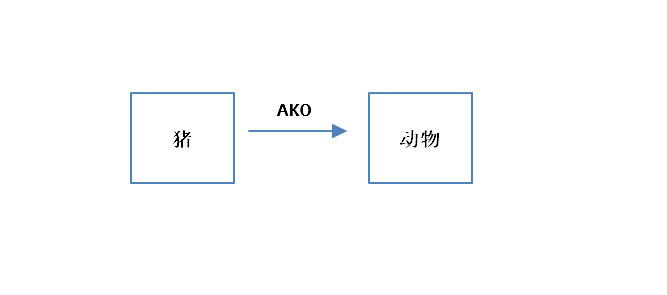
3.ISA和AKO
ISA:一个事物是另外一个事物的具体例子

AKO:一个事物是另外一个事物的成员
聚类关系:

PPT内容及翻译
4.abductive
介绍:溯因

- 判断:
deduction(演绎推理):从规则和观察中形成解释(原因到结果)
abduction(溯因推理):从结果到原因
induction(归纳推理):从特殊例子到一般规则
例题:
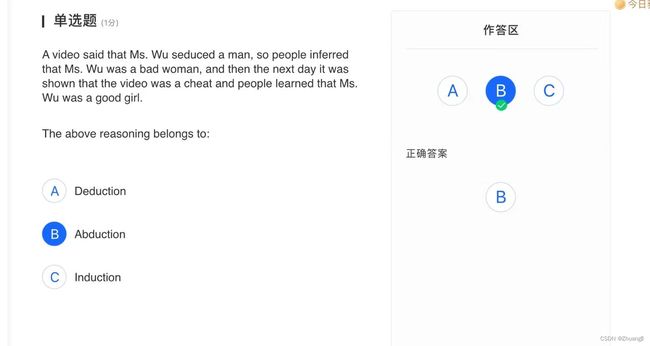
二,Search
1.DFS
例题1:

这道题的图就像是一个无限,所以选Infinity
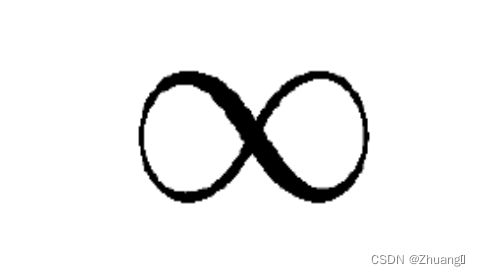
2.BFS
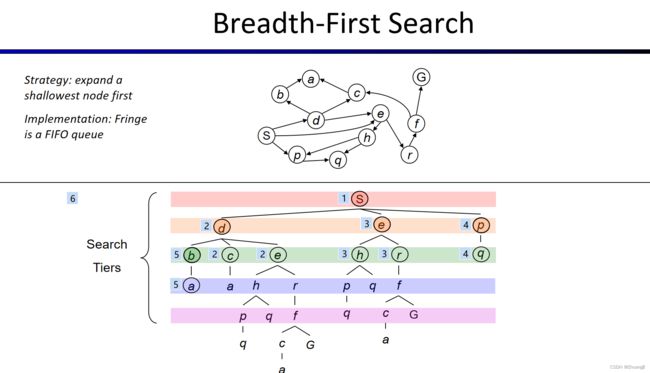
3.DFS和BFS的区别
- 数据结构
bfs 遍历节点是先进先出,一般使用队列作为辅助数据结构,dfs遍历节点是先进后出,一般使用栈作为辅助数据结构;
- 访问节点的方式
bfs是按层次访问的,先访问源点,再访问它的所有相邻节点,并且标记结点已访问,根据每个邻居结点的访问顺序,依次访问它们的邻居结点,并且标记节点已访问,重复这个过程,一直访问到目标节点或无未访问的节点为止。
dfs 是按照一个路径一直访问到底,当前节点没有未访问的邻居节点时,然后回溯到上一个节点,不断的尝试,直到访问到目标节点或所有节点都已访问。
- 应用
bfs 适用于求源点与目标节点距离近的情况,例如:求最短路径。dfs 更适合于求解一个任意符合方案中的一个或者遍历所有情况,例如:全排列、拓扑排序、求到达某一点的任意一条路径。
例题1:


4.Cost-Sensitive Search:代价敏感搜索
UCS:代价一致搜索

5.Informed Search:启发搜索
- h(x)启发函数

八数码问题启发函数采用曼哈顿距离(Manhatten distance)
- 贪婪搜索(gready search)
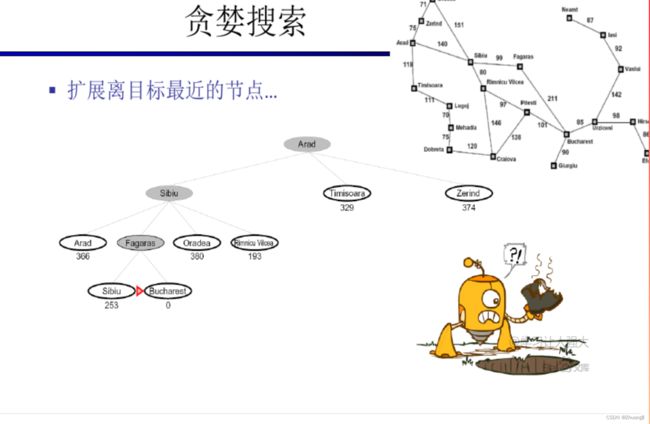
- A*搜索
f(n)=g(n)+h(n)
例题1:


关于曼哈顿和欧式距离:
对于网格地图来说, 如果只能四方向(上下左右)移动, 曼哈顿是最合适的启发函数.(8数码)
如果网格地图可以八方向(包括斜对角)移动, 使用切比雪夫距离作为启发函数比较合适.
如果地图中允许任意方向移动, 不太建议使用网格 (Grid) 来描述地图, 此时使用欧式距离来作为启发函数比较合适.
三,神经网络
有一道计算题,见计算题板块
例题1:b选项:小批量的梯度上升,每一步占一小部分


五,试题研究
1


2.

3.

关于这道题
根据逻辑分类:
Deduction(演绎) vs Induction(归纳)
从一般情况推导出一些特定的情况,这叫演绎.
从很多特殊情况总结出一般性的规律,这叫做归纳.
演绎一般是保真的,而归纳一般是不保真的.
根据知识的准确度进行分类:
Certainty(确定) vs uncertainty(不确定)
根据原因过程的单调性进行分类:
Monotonic(单调) vs Non-monotonic(非单调)
4.fuzzy reasoning:模糊推理

5.

6.

六,计算题
1.
(120-30)*0.3-30*0.7=6(另外70%的概率是要扣除30k)

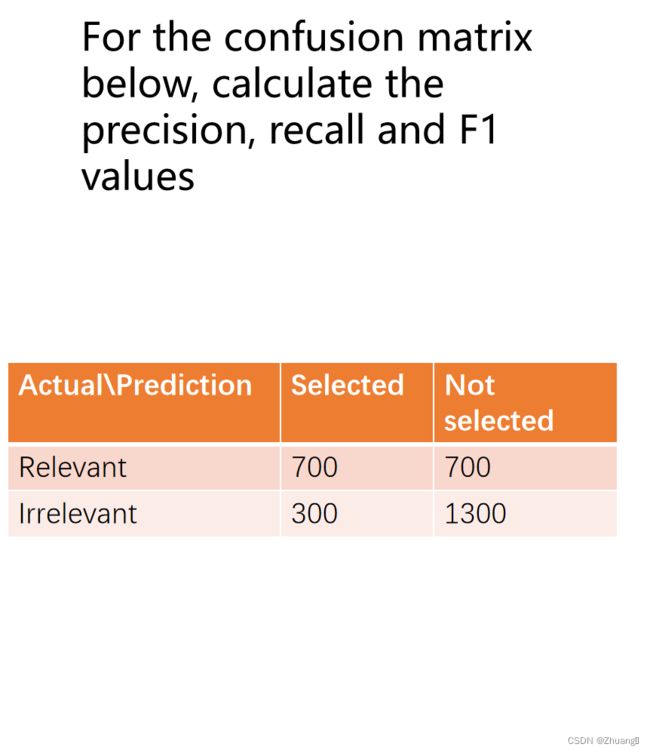
2.答案:5,5,2,6
三角形朝上找最大,三角形朝下找最小
B中三个最小是5,C是4,D是2,然后三个中找最大的是B的5,所以A是5
最后一个空的检索顺序是5,7,6,8,4(比5还小不用检索后面的),2(跟前面同理)所以是6
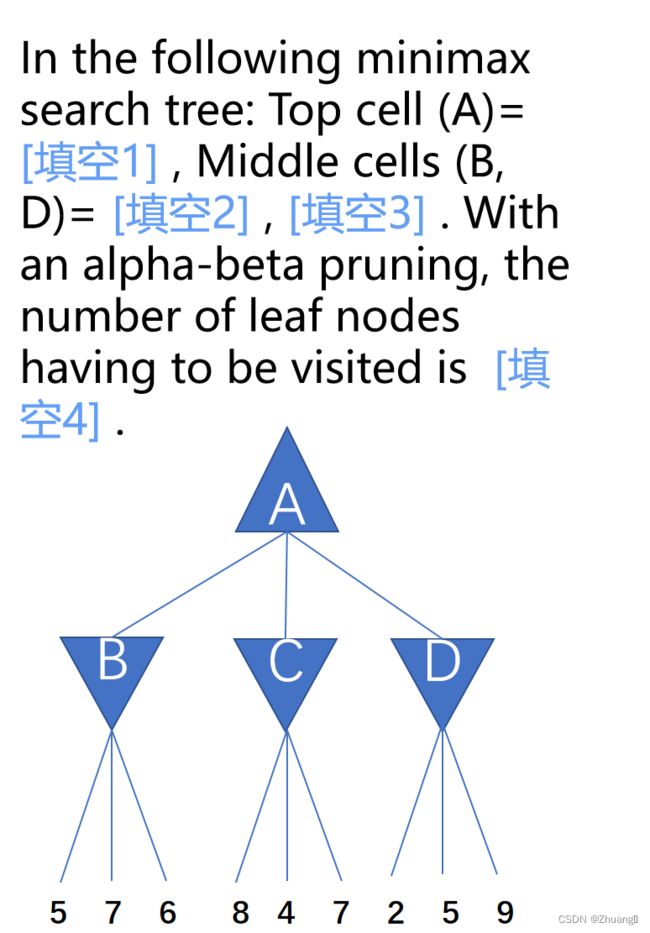
3.答案未知,方法固定
z1'=f1(x)*w1+f2(x)*w3+f2(x)*w5,计算z2'同理,这是激活前的值
激活后的值要用一个公式: 算出真正的z1和z2,最后计算softmax
算出真正的z1和z2,最后计算softmax
用另外个公式 分母都一样,计算出两个值写出来(建议写公式再写值容易算错)。
分母都一样,计算出两个值写出来(建议写公式再写值容易算错)。
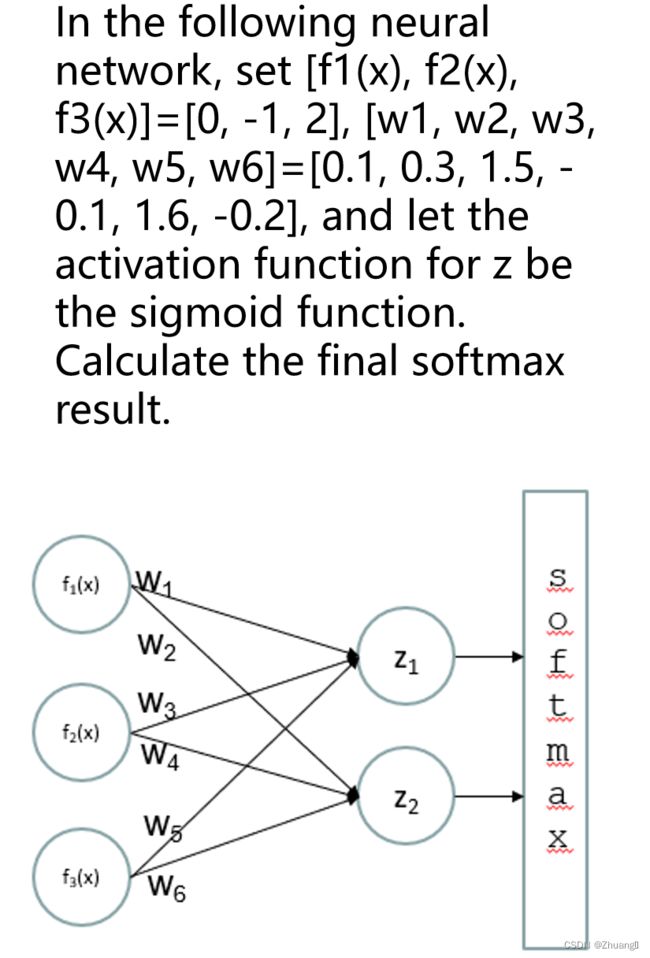
4.答案未知方法固定(公式右图)
5.答案未知方法固定:
第一问:举个例子最后计算出来是一个4*4的矩阵,(0,0)的值为3*2+-2*1+2*-1+-1*3一一对应,然后下面那个2*2的矩阵右左平移一个参照上面计算得到(0,1)的值,最后4*4矩阵全部求出来。
第二问:第一步做出来是4*4矩阵,2*2最大池化就是把它分成上下左右4个小矩阵,每个里面取最大值,参看第十个ppt

七,简答题(非标答)
- Describe the steps how actions are selected in a decision network
描述在决策网络中如何选择行动的步骤
1.例举所有证据
2.以各种可能的方式设置操作节点
3.根据证据计算效用节点所有父节点的后验概率
4.计算每个动作的预期效用
5.选择最大化行动
- Describe the concept of kernalization.
描述内核化的概念
把低维的特征向量空间,投影到高维,再将结果返回到低维。
- Describe how we can combat overfitting.
描述我们如何对抗过拟合
两种方法:a,限制假设空间,限制函数可能的复杂程度;b,正则化。
- Describe the K-means algorithm.
描述K-means算法
K-means算法。要点:初始选点-随机选点;迭代的两步;如何结束。
迭代:第一步-计算所有点到中心的距离,然后根据距离分类,第二步-对已经聚完的数,重新求中心点再计算所有的距离。不断重复一二步,反复计算然后归类,直到中心点不再发生变化结束。
- Describe what the one-hot representation and the distributed representations are and explain their difference
描述什么是一热表示法和分布式表示法,并解释它们的区别
热编码维度多,容易导致维度爆炸,会导致语义鸿沟;分布式编码维度少,避免了维度爆炸,避免了语义鸿沟。
- List the properties of the VPI.
列出VPI的属性。
非负性:非加性;(两条完美信息的价值是不能相加的):顺序无关性(得知两条完美信息的顺序不影响完美信息的价值)。
- Describe what an admissible heuristic function is.
描述什么是可容许的启发式函数
admissible指任意一个结点上的值大于等于0,且小于等于到中结点的值
- How to calculate the entropy?
如何计算熵?
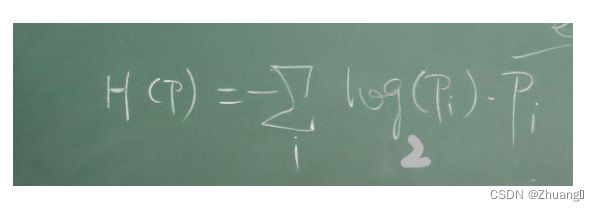
- How to calculate the evaluation function?
如何计算评价函数?
Gn+hn
Gn 为初始节点到当前节点的距离
Hn为当前节点到目标节点的距离
- Describe the C4.5 and ID3 algorithms.
描述C4.5和ID3算法
ID3:根据信息增益来选择节点
C4.5:根据信息增益率选择节点

- Describe the agglomerative clustering.
描述聚集性聚类
首先,合并非常相似的实例
从较小的集群中逐步构建较大的集群
选择两个最近的簇
将它们合并到一个新集群中
当只剩下一个集群时停止
生成的不是一个聚类,而是由树状图表示的一系列聚类
(eg:原80个簇,选择两个离得最近簇聚集为一个簇剩79簇。反复进行,直到只有一个簇。)
- Understand the CNN channels.
了解CNN频道
CNN相关—就是输入输出数据通道和卷积核通道数和个数的关系。