Python课程设计(二)
DBSCAN聚类分析应用试验
- DBSCAN聚类分析
-
- 一、实验要求
-
- 原代码DBSCAN_circles.py代码如下:
- 二、实验原理
- 三、实现过程
- 四、实验结果
- 具体代码如下:
DBSCAN聚类分析
一、实验要求
模仿DBSCAN_circles.py代码,用datasets.make_moons函数生成样本点1000个,参数设置为noise=0.1,用datasets.make_blobs函数生成样本点1000个, 参数设置为n_features=2, centers=[[1.2,1.2]], cluster_std=0.1, 二个函数的random_state都设置为各人学号除以30的余数。调整DBSCAN算法的参数正确识别出相应的类,代码中反映调整的过程。
原代码DBSCAN_circles.py代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn import datasets
from sklearn.cluster import DBSCAN
#%% 生成、展示数据
X1, y1=datasets.make_circles(n_samples=1000, factor=0.6,noise=0.05,random_state=9) #factor:外圈与内圈的尺度因子
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]],
cluster_std=[[0.1]], random_state=9)
X = np.concatenate((X1, X2)) #纵向拼接
plt.figure(figsize=(12, 9))
plt.plot(X[:, 0], X[:, 1], 'o',markersize=6)
plt.show()
#%% 首先看看K-Means的聚类效果
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X)
plt.figure(figsize=(12, 9))
plt.scatter(X[:, 0], X[:, 1],s=25, c=y_pred)
plt.title('k-means:k=3')
plt.show()
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, y_pred))
#%% 那么如果使用DBSCAN效果如何呢?我们先不调参,直接用默认参数,看看聚类效果,:
db = DBSCAN().fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
# 1)np.linspace 返回[0,1]之间的len(unique_labels) 个数
# 2)plt.cm 一个颜色映射模块
# 3)生成的每个colors包含4个值,分别是RGBA:
# RGBA是代表Red(红色) Green(绿色) Blue(蓝色)和 Alpha的色彩空间,
# 也就是透明度/不透明度
# 4)其实这行代码的意思就是生成len(unique_labels)个可以和光谱对应的颜色值
plt.figure(figsize=(12, 9))
for k, col in zip(unique_labels, colors):
class_member_mask = (labels == k)
if k == -1: #被判定的噪声点
cls = 'noise'
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor='k',
markeredgecolor='k', markersize=6,label=cls)
else:
xy = X[class_member_mask & core_samples_mask] #核心点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=10,label= 'class '+ str(k)+' core')
xy = X[class_member_mask & ~core_samples_mask] #边缘点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6,label= 'class '+ str(k)+' border')
plt.legend(loc='best')
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
#%% 对DBSCAN的两个关键的参数eps和min_samples进行调参!发现,类别数太少,
#需要增加类别数,可以减少eps-邻域的大小,默认是0.5,减到0.1看看效果
db = DBSCAN(eps=0.1).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
plt.figure(figsize=(12, 9))
for k, col in zip(unique_labels, colors):
class_member_mask = (labels == k)
if k == -1: #被判定的噪声点
cls = 'noise'
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor='k',
markeredgecolor='k', markersize=6,label=cls)
else:
xy = X[class_member_mask & core_samples_mask] #核心点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=12,label='class '+ str(k)+' core')
xy = X[class_member_mask & ~core_samples_mask] #边缘点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6,label='class '+ str(k)+' border')
plt.legend(loc='best')
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
二、实验原理
DBSCAN是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
三、实现过程


四、实验结果
原始数据分布图:

K-means算法:
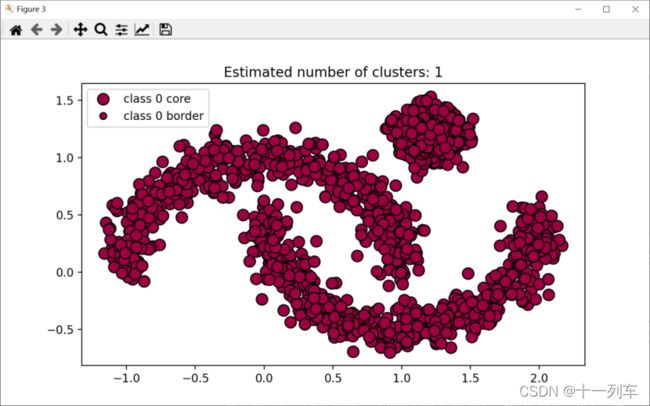
DBSCAN算法(默认exp=0.5时,簇间邻域的距离阈值,eps过大,更多的点会落在核心点的邻域中,只生成了一类样本点)
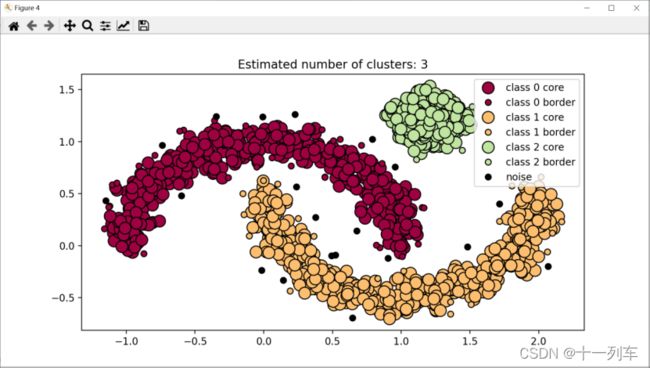
DBSCAN算法(exp=0.1,减少了邻域的距离,聚类结果聚成了三类。)
具体代码如下:
# -*- coding: utf-8 -*-
"""
创建于 Fri Jan 14 22:05:33 2022
作者:
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn import datasets
from sklearn.cluster import DBSCAN
#%% 生成、展示数据
X1,y1=datasets.make_moons(n_samples=1000, noise=0.1,random_state=19050411111%30) #factor:外圈与内圈的尺度因子
#make_moons 函数用来生成数据集 random_state生成随机种子
X2,y2= datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[0.1]],random_state=17050411122%30)
X = np.concatenate((X1, X2)) #纵向拼接
plt.figure(figsize=(12, 9))#图的设置
plt.plot(X[:, 0], X[:, 1], 'o',markersize=4)
plt.show()
#%% 首先看看K-Means的聚类效果
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=19050411111%30).fit_predict(X)
plt.figure(figsize=(12, 9))
plt.scatter(X[:, 0], X[:, 1],s=25, c=y_pred)
#scatter 绘制散点图 s=25 是散点图的半径
plt.title('k-means:k=3')
plt.show()
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, y_pred))
#%% 使用DBSCAN查看效果,先不调参,直接用默认参数,看看聚类效果
db = DBSCAN().fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
plt.figure(figsize=(12, 9))
for k, col in zip(unique_labels, colors):
class_member_mask = (labels == k)
if k == -1: #被判定的噪声点
cls = 'noise'
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor='k',
markeredgecolor='k', markersize=6,label=cls)
else:
xy = X[class_member_mask & core_samples_mask] #核心点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=10,label= 'class '+ str(k)+' core')
xy = X[class_member_mask & ~core_samples_mask] #边缘点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6,label= 'class '+ str(k)+' border')
plt.legend(loc='best')
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
#当eps=0.1,看看效果
db = DBSCAN(eps=0.1).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
plt.figure(figsize=(12, 9))
for k, col in zip(unique_labels, colors):
class_member_mask = (labels == k)
if k == -1: #被判定的噪声点
cls = 'noise'
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor='k',
markeredgecolor='k', markersize=6,label=cls)
else:
xy = X[class_member_mask & core_samples_mask] #核心点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=12,label='class '+ str(k)+' core')
xy = X[class_member_mask & ~core_samples_mask] #边缘点
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6,label='class '+ str(k)+' border')
plt.legend(loc='best')
plt.title('Estimated number of clusters: %d' % n_clusters_)