阅读文献一
摘要:
引言:
近年来,由于多媒体数据的爆炸式增长,研究者[1]-[3]对多模态数据之间的关系表现出了强烈的兴趣。建立多媒体数据之间关系模型的最大挑战是模式之间的异质性差距。为了解决这一问题,一些方法[4]-[7]利用现有的预训练模型获得全局特征,并将这些特征映射到一个公共空间,其中多模态特征可以直接比较。例如,跨模态检索的在线哈希框架,它可以为新数据生成哈希码,而不更新现有的哈希码。它可以利用语义标签信息和新数据和现有数据之间的相关性。Liu等人[9]提出了一种使用联合模态相似矩阵的无监督哈希方法来保持两种模态之间的相关性。采用抽样和加权方案使相似语义的样本更近,使不同语义的样本更远。Dong等[10]提出了一种基于图卷积网络的方法,使每个样本的语义信息更加完整。利用生成式对抗网络在公共空间中获得模态不变表示。上述所有研究方法均取得了良好的效果。然而,仍然存在一个问题,即上述仅使用全局特征的样本的粗粒度对齐不能探索图像和句子之间的交互作用。这不利于准确地检索所需的多模态样本。
为了更准确地对齐图像-文本,一些学者提出了细粒度的[11]-[14]方法。Wang等人[15]提出了一种利用注意机制的跨模态自适应信息传递算法,来自适应地控制模态之间的信息流。他们还考虑了细粒度的相互作用,并提出了一个最困难的负二值交叉熵损失。Wang等人[16]提出了一个位置集中的注意网络来探讨图像和文本模式之间的相关性。将位置信息和视觉特征集成到图像表示中,使视觉表达更加完整,Chen等人[17]提出了一种循环注意记忆迭代匹配方法,逐步捕捉图像中区域与句子中单词之间的相关性。利用一种内存蒸馏单元来融合跨模态特征。然而,在这些细粒度的方法中,如图1(a)所示,存在一个缺点,仅仅对图像中的对象和段落中的单词对齐,不能结合更准确的高阶信息,如属性信息和对象之间的关系信息,不利于图像-文本对齐。从图1(b)和图1(c)中,我们还可以发现,在对图像和文本进行对齐时,对象和对象属性之间的关系在语义表达式上的意义。
Li等人[18]提出了一种通过探索高阶语义信息和干扰的视觉-语义匹配(VSM)方法。为了计算图像-文本的相似度,他们利用图卷积网络来吸收高阶信息和模态之间的图注意机制。该方法在图像-文本匹配方面取得了良好的性能。受该方法的启发,我们充分利用高阶语义信息(包括对象的属性和对象之间的关系)来丰富对象的语义完整性。我们的方法分层地聚合了每个对象节点的属性和关系信息,然后只使用对象节点的特性来进行后续的节点匹配。我们的方法与VSM的不同之处在于,VSM直接为场景图中的每个节点生成节点表示,然后在不同模式下的所有节点(包括属性节点、关系节点和对象节点)之间进行节点匹配,对于我们提出的算法,以图像形态为例,我们的方法只匹配对象节点在图像模态和文本形态的全局特征,而不是各种节点的文本模态的匹配过程,可以有效地降低跨模态匹配的复杂性,提高算法的效率。本文提出了一种基于变换器(HAT)的层次特征的图像-文本匹配聚合算法。我们的工作的、
主要贡献可以总结如下:
•我们提出了一种基于图卷积网络的层次特征聚合算法,通过整合图像和文本模式中对象之间的关系来促进对象语义完整性。
•我们提出了两种跨模态变压器,它们集成了其他模态的对象特征和全局特征,以缩小模态间隙,促进跨模态特征的融合。
•在精细粒度检索数据集MSCOCO和Flickr30K上进行的实验表明,与现有的细粒度图像-文本对齐算法相比,该方法的有效性
相关工作:
近年来,图卷积网络(GCN)[19]具有较强的根据相邻关系提取节点特征的能力,在知识图[20]、[21]、图像检索[22]、[23]、[23]、节点分类[24]、[25]等领域得到了广泛的应用。例如,Yang等人[26]提出了一种用于图像字幕的自动编码场景图,它在模型中引入了语言归纳偏差。他们利用GCN来整合形容词节点和关系节点,并使用字典作为工作记忆。Dong等人[27]提出了一种用于跨模态检索的图注意记忆网络。他们利用GCN利用样本之间的关系重构样本表示,并利用图注意机制从其他模态中吸收信息,进行跨模态特征融合。Xu等人[28]提出了一种用于跨模态检索的图卷积哈希方法,他们同时使用包含语义信息的教师模块和利用语义信息的学生模块来学习特征编码过程,并利用GCN来探索特征融合模式之间的相似性。Ma等人[29]提出了一种用于无监督域自适应的图卷积对抗网络,该网络在一个框架中集成了三个关键角色,并提出了三种对齐方法。上述方法证明了图卷积网络在跨模态学习中的潜力。因此,在我们的方法中,也使用图卷积网络来整合节点间的邻接关系,从而生成具有更完整的语义信息的节点表示

注意机制因其关注重要信息和过滤琐碎信息的能力而受到了广泛的关注。注意机制最经典的应用是变压器[30]。近年来,仅基于注意机制的变压器由于其集成多模态特征和生成特定于模态的特征表示的能力,在多模态特征处理中得到了广泛的应用。例如,Ging等人[31]提出了一种用于视频-文本表示学习的协作层次转换器,它可以利用不同层次的特征,并从模式内部和模式间的方面建模它们之间的交互。由于Devlin等人[32]提出了基于多层双向变压器模型的BERT概念用于语言理解,因此出现了许多用于跨模态应用的BERT变体。例如,Lu等人[33]提出了一种视觉和语言的BERT来学习图像和文本模态的任务不可知的特征表示。它们将图像和文本特征输入共注意变压器层,以进行多模态特征融合。Lei等人[34]提出了一种视频和语言学习的剪辑模型,采用稀疏采样策略,仅使用少量视频剪辑即可获得良好的结果,并使用转换器来聚合特征。Su等人[35]提出了一种用于对视觉-语言通用任务进行表示的VL-BERT方法,该方法利用变压器模型作为主干,并将图像或句子中的单词的感兴趣区域作为输入。VL-BERT可以为两种不同的模式生成通用表示。上述变压器的应用显示了其在处理多模态特性方面的潜力。因此,在我们的工作中,我们利用变压器模型进行跨模态特征融合。
在此研究中,我们提出了一种新的图像-文本匹配算法HAT。首先,我们使用基于GCN的特征聚合器逐层聚合每个对象的属性和关系信息,使对象描述更加完整。然后,我们将其他模态的对象特征和全局特征输入到变压器中。值得注意的是,不同模式的变压器具有相同的结构,但没有共享的参数。最后,我们的算法将来自不同模式的融合特征映射到一个公共空间,其中样本之间的距离可以直接测量。我们的方法受到(非)监督域自适应的启发,来学习模式之间的相互作用,以及图学习对各种应用的有效性,如根据相邻关系提取节点特征。此外,我们的方法也受到了变压器的广泛使用的启发,这已经被发现是在选择有意义的特征作为表示学习的主要目标的有效方法,
在本节中,我们将展示我们所提出的HAT的细节,包括模型定义和优化算法。HAT包含两部分:分层图卷积网络(H-GCN)和图像和用于文本模式的跨模态变压器。数据集D包含图像和文本模式分别表示为I和S。设D={Di}ni=1,其中n表示图像-文本对的数量。Di=(Ii、Si)、Ii和Si是第i个实例的原始图像和文本。图2说明了所提出的HAT方法的一般原理。该方法由两部分组成:1)分层图卷积网络(H-GCN)和用于图像和文本模式的跨模态变压器。首先,用现成的算法分别对图像和文本进行预处理,得到图像场景图和文本场景图。然后将场景图中的对象特征、对象属性和对象之间的关系输入H-GCN,重建对象表示。然后将重构的对象表示和其他模态的全局特征输入变压器进行模态特征融合。最后,将融合的特征映射到公共空间,其中可以直接测量不同模式之间的距离
实验:
为了评价该方法的有效性,我们在MSCOCO和Flickr30K数据集上进行了实验。在本节中,我们首先介绍数据集的特征和基线方法,然后将我们的方法与基线方法进行比较,并对我们的HAT方法进行可视化分析。最后,为了进一步验证所提出的方法的每个部分的影响,我们实施了一个消融分析。
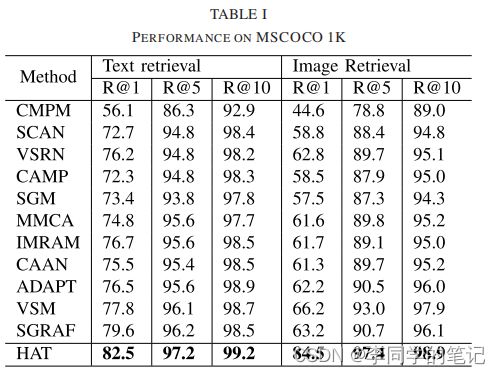

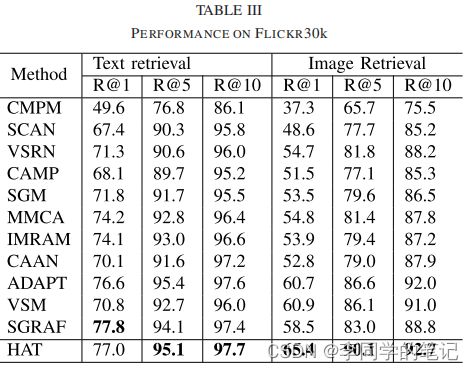
结论:
在这项工作中,我们提出了一种基于层次特征聚合的变压器算法,将图像和文本模式的融合特征映射到一个公共空间,其中特征距离可以直接测量。我们使用层次图卷积网络(H-GCN),分层地利用属性和关系信息,使对象的语义表达更加完整。然后,我们分别使用图像变换器和文本变换器来融合跨模态特征,从而消除了特征的异质性。实验结果表明,该方法在评价指标上取得了良好的效果。