《用户画像--方法论与工程化解决方法》读后感

代码下载:
GitHub - HunterChao/User-Portrait: 用户画像相关的参考代码
前言
第1章 用户画像基础1
1.1 用户画像是什么1
1.1.1 画像简介1
用户画像,即用户信息标签化,通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或产品特征属性进行刻画,并对这些特征进行分析统计,挖掘潜在价值,从而抽象出用户的信息全貌。
1.1.2 标签类型3
统计类标签、规则类标签、算法类标签
1.2 数据架构4
在整个工程化方案中,系统依赖的基础设施包括Spark、Hive、HBase、Airflow、MySQL、Redis、Elasticsearch。除去基础设施外,系统主体还包括Spark Streaming、ETL、产品端3个重要组成部分。
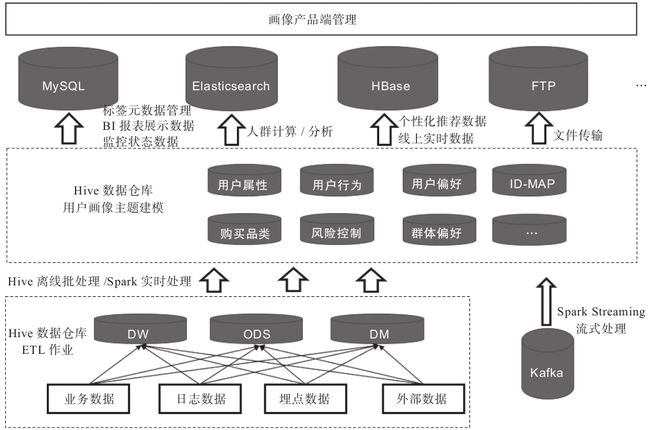
图1-4 用户画像数仓架构
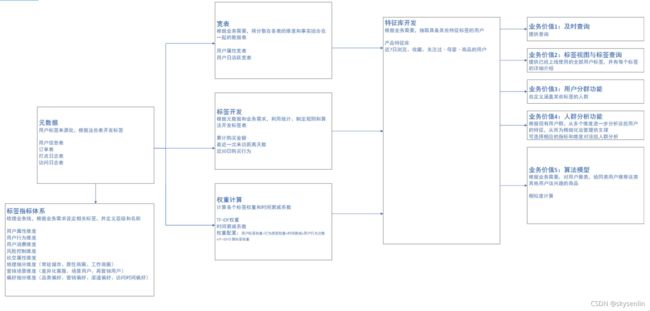
图1-5 用户标签ETL流程
图1-4下方虚线框中为常见的数据仓库ETL加工流程,也就是将每日的业务数据、日志数据、埋点数据等经过ETL过程,加工到数据仓库对应的ODS层、DW层、DM层中。
中间的虚线框即为用户画像建模的主要环节,用户画像不是产生数据的源头,而是对基于数据仓库ODS层、DW层、DM层中与用户相关数据的二次建模加工。在ETL过程中将用户标签计算结果写入Hive,构
图1-4下方虚线框中为常见的数据仓库ETL加工流程,也就是将每日的业务数据、日志数据、埋点数据等经过ETL过程,加工到数据仓库对应的ODS层、DW层、DM层中。
中间的虚线框即为用户画像建模的主要环节,用户画像不是产生数据的源头,而是对基于数据仓库ODS层、DW层、DM层中与用户相关数据的二次建模加工。在ETL过程中将用户标签计算结果写入Hive,由于不同数据库有不同的应用场景,后续需要进一步将数据同步到MySQL、HBase、Elasticsearch等数据库中。
·Hive:存储用户标签计算结果、用户人群计算结果、用户特征库计算结果。
·MySQL:存储标签元数据,监控相关数据,导出到业务系统的数据。
·HBase:存储线上接口实时调用类数据。
·Elasticserch:支持海量数据的实时查询分析,用于存储用户人群计算、用户群透视分析所需的用户标签数据(由于用户人群计算、用户群透视分析的条件转化成的SQL语句多条件嵌套较为复杂,使用Impala执行也需花费大量时间)。
用户标签数据在Hive中加工完成后,部分标签通过Sqoop同步到MySQL数据库,提供用于BI报表展示的数据、多维透视分析数据、圈人服务数据;另一部分标签同步到HBase数据库用于产品的线上个性化推荐。
1.3 主要覆盖模块5
搭建一套用户画像方案需要考虑8个模块的建设:
1、用户画像基础:需要了解、明确用户画像是什么,包含哪些模块,数据仓库架构是什么样子,开发流程,表结构设计,ETL设计等。这些都是框架,大方向的规划,只有明确了方向后续才能做好项目的排期和人员投入预算。这对于评估每个开发阶段重要指标和关键产出非常重要,重点可看1.4节。
2、数据指标体系:根据业务线梳理,包括用户属性、用户行为、用户消费、风险控制等维度的指标体系。
3、标签数据存储:标签相关数据可存储在HIVE、MYSQL、HBASE等数据库中,不同的应用场景有不同的存储方式。
4、标签数据开发:统计类、规则类、算法类、流式计算类标签的开发,以及人群计算功能的开发,打通画像数据和各业务系统之间的通路,提供接口服务等开发内容。
5、开发性能调优:标签加工、人群计算等脚本上线调度后,为了缩短调度时间,保障数据的稳定性等,需要对开发的数据进行迭代重构、调优。
6、作业流程调度:标签加工、人群计算、同步数据到业务系统、数据监控预警等脚本开发完成后,需要调度工具把整套流程调度起来。本书讲解了Airflow这款开源ETL工具在调度画像相关任务脚本上的应用。
7、用户画像产品化:为了能让用户数据更好地服务于业务方,需要以产品化的形态应用在业务上。产品化的模块主要包括标签视图、用户标签查询、用户分群、透视分析等。
8、用户画像应用:画像的应用场景包括用户特征分析、短信、邮件、站内信、Push消息的精准推送、客服针对用户的不同话术、针对高价值用户的极速退货退款等VIP服务应用。
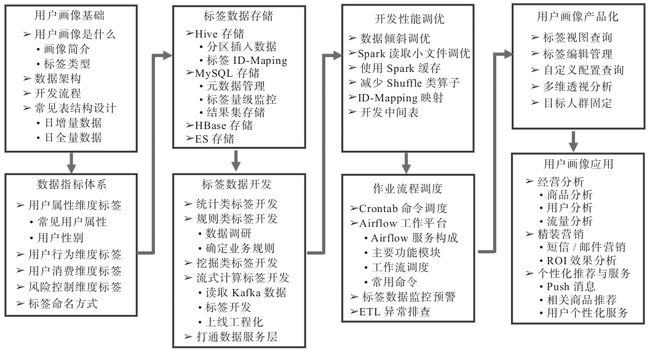
图1-5 用户画像主要覆盖模块
1.4 开发阶段流程7
1.4.1 开发上线流程7
用户画像建设项目流程,如图1-6所示。
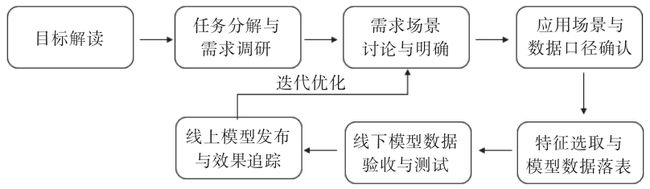
图1-6 用户画像建设项目流程
第一阶段:目标解读
在建立用户画像前,首先需要明确用户画像服务于企业的对象,再根据业务方需求,明确未来产品建设目标和用户画像分析之后的预期效果。
一般而言,用户画像的服务对象包括运营人员和数据分析人员。不同业务方对用户画像的需求有不同的侧重点,就运营人员来说,他们需要分析用户的特征、定位用户行为偏好,做商品或内容的个性化推送以提高点击转化率,所以画像的侧重点就落在了用户个人行为偏好上;就数据分析人员来说,他们需要分析用户1
开发上线流程
用户画像建设项目流程,如图1-6所示。
图1-6 用户画像建设项目流程
第一阶段:目标解读
服务对象:运营人员和数据分析师
他们需求的侧重点:分析用户的特征、定位用户行为偏好、做商品或内容的个性化推送以提高点击转化率、分析用户行为特征做好用户的流失预警工作、根据用户的消费偏好做更有针对性的精准营销。
第二阶段:任务分解与需求调研
结合产品现有业务体系和“数据字典”规约实体和标签之间的关联关系,明确分析维度。就后文将要介绍的案例而言,需要从用户属性画像、用户行为画像、用户偏好画像、用户群体偏好画像等角度去进行业务建模。
第三阶段:需求场景讨论与明确
在本阶段,数据运营人员需要根据与需求方的沟通结果,输出产品用户画像需求文档,在该文档中明确画像应用场景、最终开发出的标签内容与应用方式,并就该文档与需求方反复沟通并确认无误。
第四阶段:应用场景与数据口径确认
经过第三个阶段明确了需求场景与最终实现的标签维度、标签类型后,数据运营人员需要结合业务与数据仓库中已有的相关表,明确与各业务场景相关的数据口径。在该阶段中,数据运营方需要输出产品用户画像开发文档,该文档需要明确应用场景、标签开发的模型、涉及的数据库与表以及应用实施流程。该文档不需要再与运营方讨论,只需面向数据运营团队内部就开发实施流程达成一致意见即可。
第五阶段:特征选取与模型数据落表
本阶段中数据分析挖掘人员需要根据前面明确的需求场景进行业务建模,写好HQL逻辑,将相应的模型逻辑写入临时表中,并抽取数据校验是否符合业务场景需求。
第六阶段:线下模型数据验收与测试
数据仓库团队的人员将相关数据落表后,设置定时调度任务,定期增量更新数据。数据运营人员需要验收数仓加工的HQL(HQL是Hibernate Query Language的缩写,提供更加丰富灵活、更为强大的查询能力,对查询条件进行了面向对象封装,符合编程人员的思维方式,格式:from + 类名 + 类对象 + where + 对象的属性)逻辑是否符合需求,根据业务需求抽取表中数据查看其是否在合理范围内,如果发现问题要及时反馈给数据仓库人员调整代码逻辑和行为权重的数值。
第七阶段:线上模型发布与效果追踪
经过第六阶段,数据通过验收之后,会通过Git进行版本管理,部署上线。使用Git进行版本管理,上线后通过持续追踪标签应用效果及业务方反馈,调整优化模型及相关权重配置。
1.4.2 各阶段关键产出9
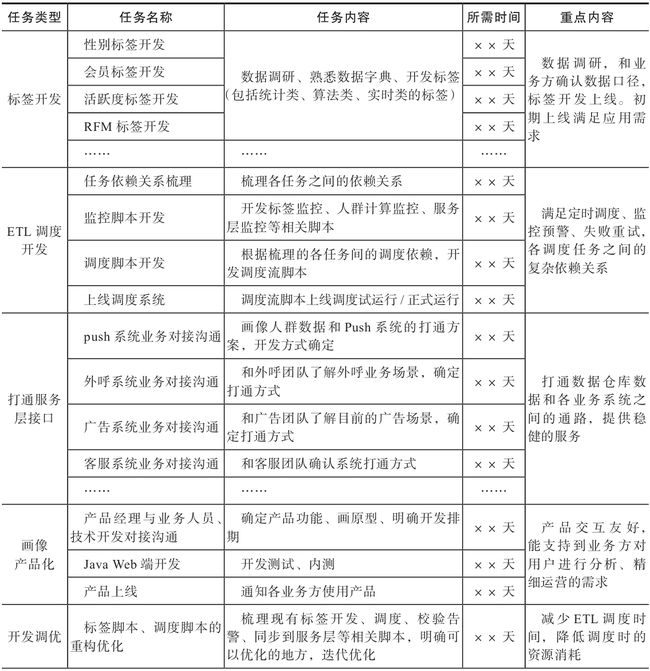
为保证程序上线的准时性和稳定性,需要规划好各阶段的任务排期和关键产出。画像体系的开发分为几个主要阶段,包括前期指标体系梳理、用户标签开发、ETL调度开发、打通数据服务层、画像产品端开发、面向业务方推广应用、为业务方提供营销策略的解决方案等,如表1-1所示。
表1-1 用户画像项目各阶段关键产出

1.5 画像应用的落地10
对数据分析人员来说,会关注开发了哪些表、哪些字段以及字段的口径定义;
对运营、客服人员来说,可能更关注如何在web端使用画像产品进行分析、固定特定用户进行定向营销以及应用在业务数据中准确性和及时性;
只有业务人员在实际业务中使用画像产品,画像数据才能更好的推动画像标签的迭代优化,带来流量提升和营收增长,产生业绩价值。
1.6 某用户画像案例11
在本案例的开发工作中,基于spark计算引擎,主要涉及的语言包括hivesql、python、scala、shell等。
1.6.1 案例背景介绍11
一方面在企业产品线不断扩张,信息资源过载的背景下,如何在兼顾自身商业目标的同时更好的满足消费者的需求,为用户带来更个性化的购物体验,通过内容的精准推荐,更好的提高用户的点击转化率,另一方面建立用户流失预警机制。
1.6.2 相关元数据12
在本案例中,按照获取数据的类型分为:业务数据和用户行为数据。其中业务类数据是指用户在平台上下单、购买、收藏物品、货物配送等与业务相关的数据;用户行为数据是指用户搜索某条信息、访问某个页面、点击某个按钮、提交某个表单等通过操作行为产生(在解析日志的埋点表中)的数据。
涉及数据仓库中的表主要包括用户信息表、商品订单表、图书信息表、图书类目表、App端日志表、Web端日志表、商品评论表等。下面就用户画像建模过程中会用到的一些数据表做详细介绍。
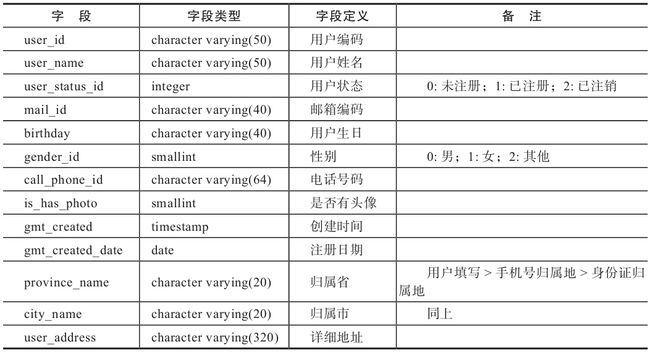
1.用户信息表
用户信息表(见表1-2)存放有关用户的各种信息,如用户姓名、年龄、性别、电话号码、归属地等信息。
表1-2 用户信息表(dim.user_basic_info)
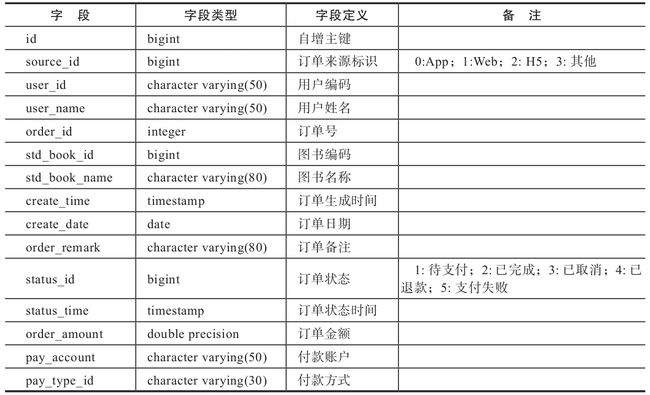
2.商品订单表
商品订单表(见表1-3)存放商品订单的各类信息,包括订单编号、用户id、用户姓名、订单生成时间、订单状态等信息。
表1-3 商品订单表(dw.order_info_fact)
3.埋点日志表
埋点日志表(见表1-4)存放用户访问App时点击相关控件的打点记录。通过在客户端做埋点,从日志数据中解析出来。
表1-4 埋点日志表(ods.page_event_log)
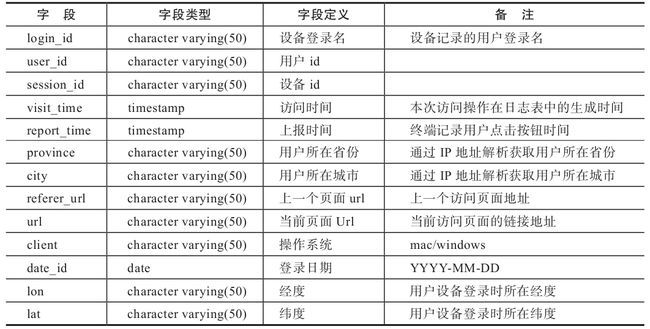
4.访问日志表
访问日志表(见表1-5)存放用户访问App的相关信息及用户的LBS相关信息,通过在客户端埋点,从日志数据中解析出来。
表1-5 访问日志表(ods.page_view_log)
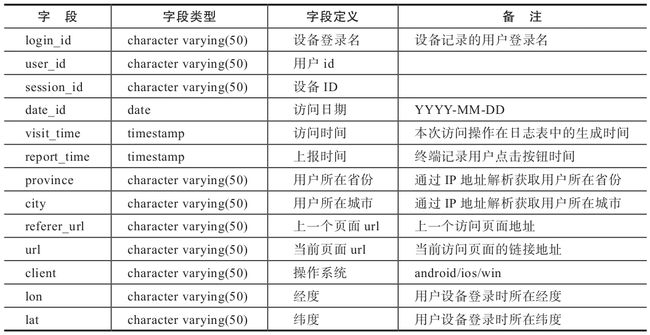
5.商品评论表
商品评论表(见表1-6)存放用户对商品的评论信息。
表1-6 商品评论表(dw.book_comment)
6.搜索日志表
搜索日志表(见表1-7)存放用户在App端搜索相关的日志数据。
表1-7 搜索日志表(dw.app_search_log)
| 字段 | 字段类型 | 字段定义 | 备注 |
| login_id | character varying(15) | 设备登录名 | 设备记录的用户登录名 |
| user_id | character varying(15) | 用户id | |
| session_id | character varying(15) | 设备id | |
| search_rad | character varying(15) | 搜索id | |
| date_id | date | 搜索日期 | |
| visit_time | timestamp | 搜索时间 | |
| search_q | character varying(15) | 用户搜索的关键词 | |
| tag_name | character varying(15) | 标签内容 | 用户搜索关键词切词后与标签库模糊匹配到的标签内容 |
| random_id | character varying(15) | 每个访次的随机数 |
7.用户收藏表
用户收藏表(见表1-8)记录用户收藏图书的数据。
表1-8 用户收藏表(dw.book_collection_df)
| 字段 | 字段类型 | 字段定义 | 备注 |
| user_id | character varying(15) | 用户id | |
| create_date | date | 收藏日期 | |
| creat_time | timestamp | 收藏时间 | |
| book_idbigint | 图书 | id | |
| book_name | character varying(50) | 图书名称 | |
| status_id | bigint | 收藏状态 | 1:收藏;0:取消收藏 |
| modify_date | date | 修改日期 | |
| modify_time | timestamp | 修改时间 |
8.购物车信息表
购物车信息表(见表1-9)记录用户将图书加入购物车的数据。
表1-9 购物车信息表(dw.shopping_cart_df)
| 字段 | 字段类型 | 字段定义 | 备注 |
| user_id | character varying(15) | 用户id | |
| book_id | bigint | 图书id | |
| book_name | character varying(50) | 图书名称 | |
| quantity | bigint | 图书数量 | |
| create_date | date | 创建日期 | |
| creat_time | timestamp | 创建时间 | |
| status_id | bigint | 图书状态 | 1:加人购物车;0:移出购物车 |
| modify_date | date | 修改日期 | |
| modify_time | timestamp | 修改时间 |
1.6.3 画像表结构设计16
表结构设计的重点是存储哪些信息、如何存储(数据分区)、如何应用(如何抽取标签),两种设计思路:
每日全量数据的表结构
每日增量数据的表结构
1、日全量数据all
记录着截止到当天的全量数据,例如:select * from tb where date='20180701'
优势:方便查询
缺点:不便于更细粒度(比如当天发生了什么)的用户行为
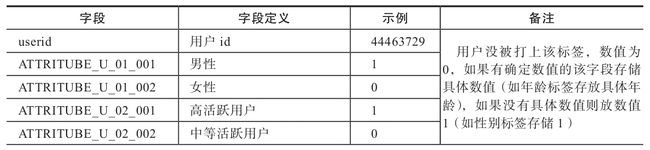
CREATE TABLE `dw.userprofile_attritube_all `(
`userid` string COMMENT 'userid',
`labelweight` string COMMENT '标签权重',)
COMMENT 'userid 用户画像数据'
PARTITIONED BY ( `data_date` string COMMENT '数据日期',
`theme` string COMMENT '二级主题',
`labelid` string COMMENT '标签id')
通过“数据日期+二级主题+标签ID”的方式进行分区,设置三个分区字段,便于开发和查询数据。
2、日增量数据append
在每天的日期分区中插入当天业务运行产生的数据。
CREATE TABLE dw.userprofile_act_feature_append (
labelid STRING COMMENT '标签id',
cookieid STRING COMMENT '用户id',
act_cnt int COMMENT '行为次数',
tag_type_id int COMMENT '标签类型编码',
act_type_id int COMMENT '行为类型编码') comment '用户画像-用户行为标签表'
PARTITIONED BY (data_date STRING COMMENT '数据日期')根据标签类型和行为类型配置维度表的方式,对数据进行管理,例如对行为类型字段act_type_id,设定1为购买行为,2为浏览行为,3为收藏行为。
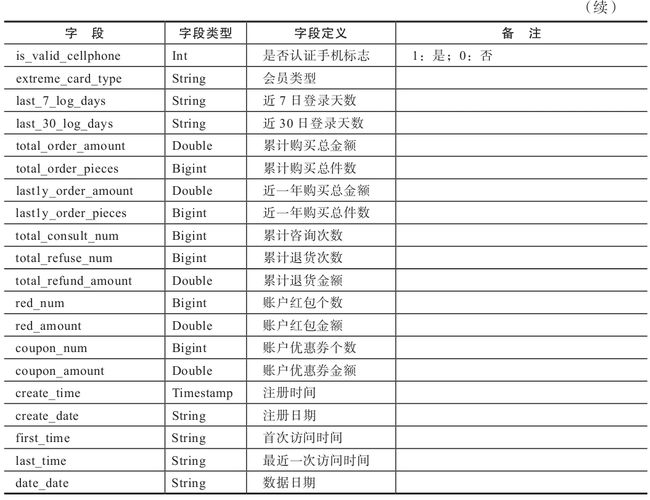
3、宽表设计
用户属性宽表设计
表1-10 用户属性宽表设计

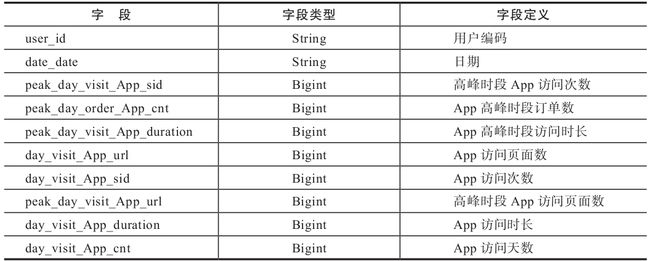
用户日活跃宽表设计(见表1-11),主要记录用户每天访问的信息。
1.7 定性类画像21
本书重点讲解如何运用大数据定量刻画用户画像,然而对于用户的刻画除了定量维度外,定性刻画也是常见手段。定性类画像多见于用户研究等运营类岗位,通过电话调研、网络调研问卷、当面深入访谈、网上第三方权威数据等方式收集用户信息,帮助其理解用户。这种定性类调研相比大数据定量刻画用户来说,可以更精确地了解用户需求和行为特征,但这个样本量是有限的,得出的结论也不一定能代表大部分用户的观点。
通过制定调研问卷表,我们可以收集用户基本信息以及设置一个或多个场景,专访用户或网络回收调研问卷,在分析问卷数据后获取用户的画像特征。目前市场上“问卷星”等第三方问卷调查平台可提供用户问卷设计、链接发放、采集数据和信息、调研结果分析等一系列功能,如图1-7所示。
1.8 本章小结22
本章主要介绍了用户画像的一些基础知识,包括画像的简介、标签类型、整个画像系统的数据架构,开发画像系统主要覆盖的8个模块,以及开发过程中的各阶段关键产出。初步介绍了画像系统的轮廓概貌,帮助读者对于如何设计画像系统、开发周期、画像的应用方式等有宏观的初步的了解。本书后面的章节将围绕1.3节中画像系统覆盖的8个模块依次展开。
第2章 数据指标体系23
建立的用户标签按标签类型可以分为统计类、规则类和机器学习挖掘类,相关内容在1.1.2节中有详细介绍。从建立的标签维度来看,可以将其分为用户属性类、用户行为类、用户消费类和风险控制类等常见类型。
2.1 用户属性维度23
2.1.1 常见用户属性23
一级标签类型若相同,需要判断标签之间的关系是互斥还是非互斥关系,性别为互斥关系,短信黑名单和邮件黑名单为非互斥关系。
表2-1 用户属性维度标签示例
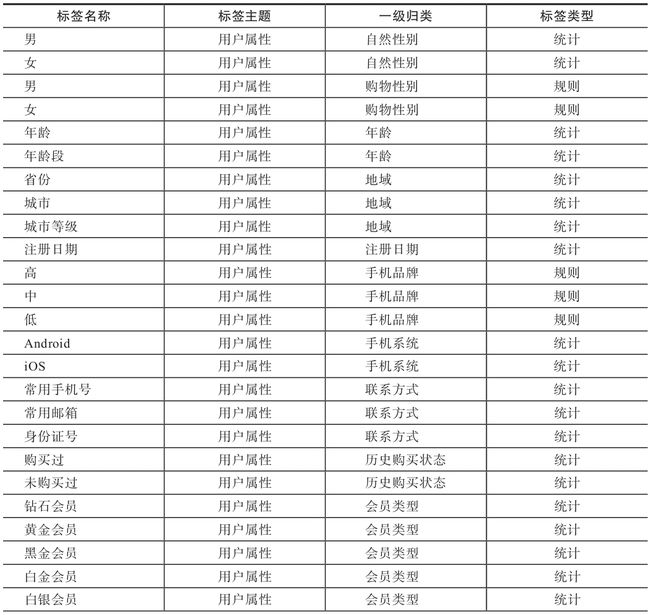
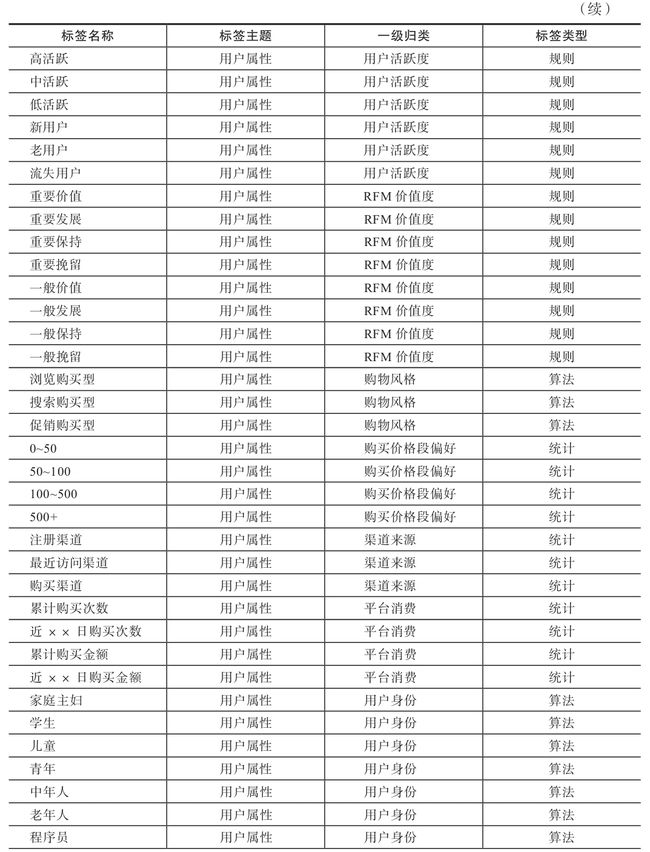

2.1.2 用户性别26
用户性别可细分为自然性别和购物性别两种。
2.2 用户行为维度27
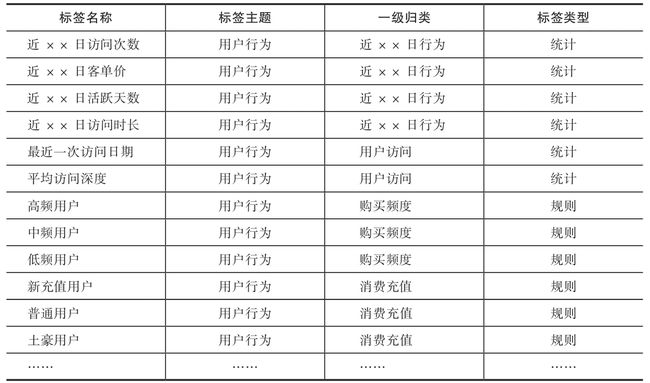
通过用户行为可以挖掘其偏好和特征。常见用户行为维度指标(见表2-2)包括:用户订单相关行为、下单/访问行为、用户近30天行为类型指标、用户高频活跃时间段、用户购买品类、点击偏好、营销敏感度等相关行为。
表2-2 用户行为维度标签示例
2.3 用户消费维度27
对于用户消费维度指标体系的建设,可从用户浏览、加购、下单、收藏、搜索商品对应的品类入手,品类越细越精确,给用户推荐或营销商品的准确性越高。如图2-1所示,根据用户相关行为对应商品品类建设指标体系,本案例精确到商品三级品类。
表2-3为用户消费维度的标签设计
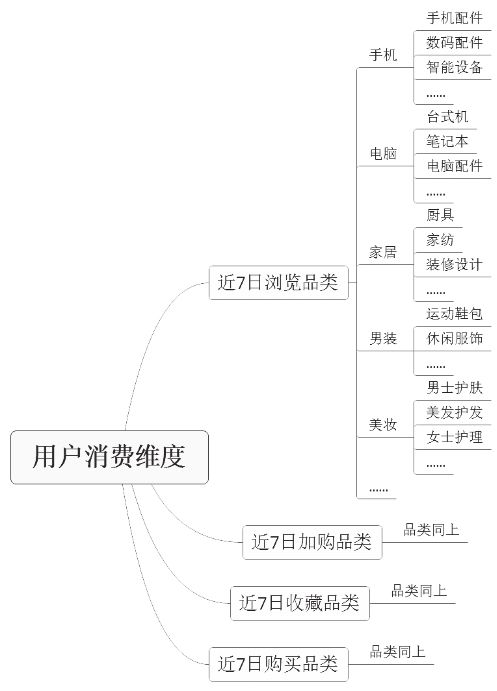
表2-3 用户消费维度标签示例
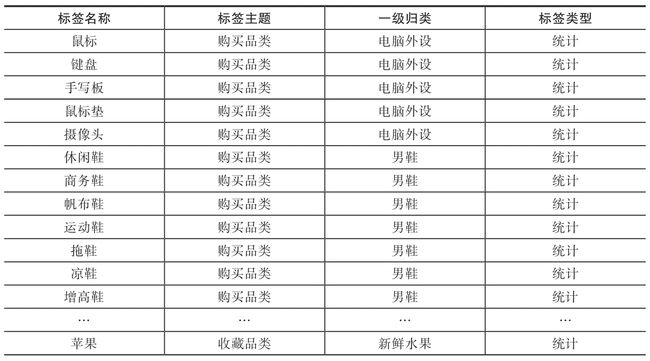
2.4 风险控制维度29
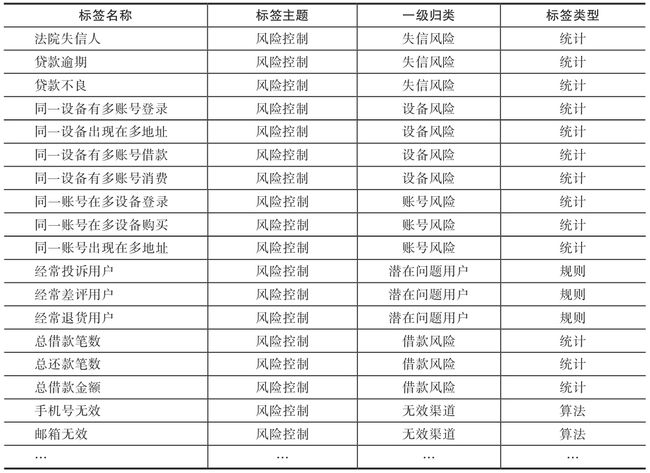
互联网企业的用户可能会遇到薅羊毛、恶意刷单、借贷欺诈等行为的用户,为了防止这类用户给平台带来损失和风险,互联网公司需要在风险控制维度构建起相关的指标体系,有效监控平台的不良用户。结合公司业务方向,例如可从账号风险、设备风险、借贷风险等维度入手构建风控维度标签体系。下面详细介绍一些常见的风险控制维度的标签示例,如表2-4所示。
表2-4 风险控制维度标签示例
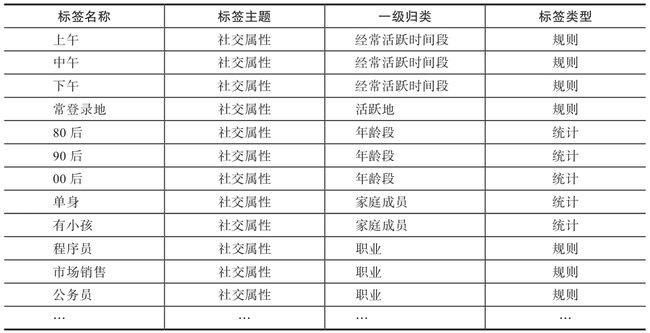
2.5 社交属性维度30
社交属性用于了解用户的家庭成员、社交关系、社交偏好、社交活跃程度等方面,通过这些信息可以更好地为用户提供个性化服务。表2-5是常用的社交属性维度标签示例。
表2-5 社交属性维度标签示例
2.6 其他常见标签划分方式31
本章前5节从用户属性、用户行为、用户消费、风险控制、社交属性共五大维度划分归类了用户标签指标体系。但对用户标签体系的归类并不局限于此,通过应用场景对标签进行归类也是常见的标签划分方式。图2-4展示了具体的画像标签应用场景划分。
从业务场景的角度出发,可以将用户标签体系归为用户属性、用户行为、营销场景、地域细分、偏好细分、用户分层等维度。每个维度可细分出二级标签、三级标签等。
·用户属性:包括用户的年龄、性别、设备型号、安装/注册状态、职业等刻画用户静态特征的属性。
·用户行为:包括用户的消费行为、购买后行为、近N日的访问、收藏、下单、购买、售后等相关行为。
·偏好细分:用户对于商品品类、商品价格段、各营销渠道、购买的偏好类型、不同营销方式等方面的偏好特征;
·风险控制:对用户从征信风险、使用设备的风险、在平台消费过程中产生的问题等维度考量其风险程度;
·业务专用:应用在各种业务上的标签,如A/B测试标签、Push系统标签等;
·营销场景:以场景化进行分类,根据业务需要构建一系列营销场景,激发用户的潜在需求,如差异化客服、场景用户、再营销用户等;
·地域细分:标识用户的常住城市、居住商圈、工作商圈等信息,应用在基于用户地理位置进行推荐的场景中;
·用户分层:对用户按生命周期、RFM、消费水平类型、活跃度类型等进行分层划分。
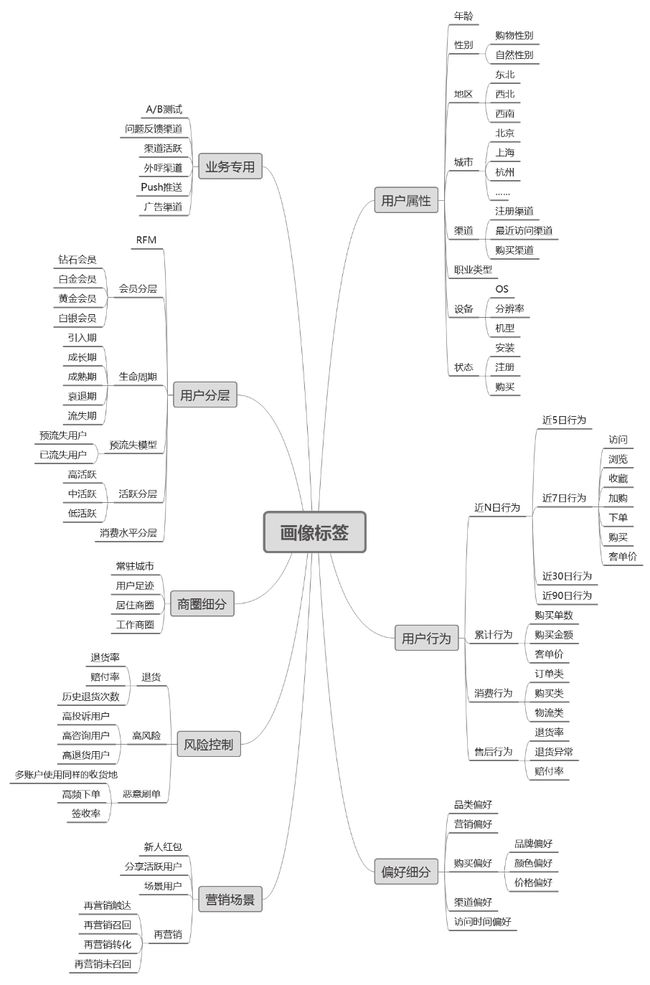
图2-4 画像标签应用场景划分
2.7 标签命名方式33
对于一个标签,可以从标签主题、刻画维度、标签类型、一级归类等多角度入手来确定每个标签的唯一名称,如图2-5所示。
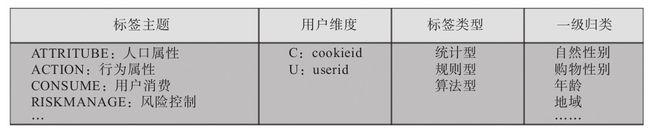
图2-5 用户标签命名维度
·标签主题:用于刻画属于哪种类型的标签,如人口属性、行为属性、用户消费、风险控制等多种类型,可分别用ATTRITUBE、ACTION、CONSUME、RISKMANAGE等单词表示各标签主题。
·用户维度:用于刻画该标签是打在用户唯一标识(userid)上,还是打在用户使用的设备(cookieid)上。可用U、C等字母分别标识userid和cookieid维度。
·标签类型:类型可划分为统计型、规则型和算法型。其中统计型开发可直接从数据仓库中各主题表建模加工而成,规则型需要结合公司业务和数据情况,算法型开发需要对数据做机器学习的算法处理得到相应的标签。
·一级维度:在每个标签主题大类下面,进一步细分维度来刻画用户。
对于用户的性别标签,标签主题是人口属性,用户维度为userid,标签类型属于算法型。给男性用户打上标签“ATTRITUBE_U_01_001”,给女性用户打上标签“ATTRITUBE_U_01_002”,其中“ATTRITUBE”为人口属性主题,“_”后面的”U”为userid维度,“_”后面“01”为一级归类,最后面的“001”和“002”为该一级标签下的标签明细(此名称里忘记标记标签类型),如果是划分高中低活跃用户的,对应一级标签下的明细可划分为“001”“002”“003”。
标签统一命名后,维护一张码表记录标签id名称、标签含义及标签口径等主要信息,后期方便元数据的维护和管理。本节介绍的标签命名方式可作为开发标签过程中的一种参考方式。
标签指标体系实践
案例:
| 一级标签 | 二级标签 | 三级标签 | 标签值 | 规则定义 | 说明 | 标签类型 |
| 人口统计 | 基础属性 | 性别 | 预测标签 | |||
| 出生年月 | 1993/4/5 | 事实标签 | ||||
| 年龄 | 一般是范围,根据业务不同划分不同。比如1~18;19~24;25~30;31~35; 36~40;>40 | 事实标签 | ||||
| 籍贯 | 河南 | 事实标签 | ||||
| 婚姻 | 未婚 | 预测标签 | ||||
| 学历 | 大学 | 需要挖掘, | 预测标签 | |||
| 注册 | 手机号 | 事实标签 | ||||
| 邮箱 | 事实标签 | |||||
| 注册渠道 | 事实标签 | |||||
| 注册方式 | 平台账号、微信、QQ、微博 | 事实标签 | ||||
| 注册时间 | 2015/10/1 | 事实标签 | ||||
| 社会属性 | 工作位置 | 经纬度 | 预测标签 | |||
| 家庭位置 | 经纬度 | 预测标签 | ||||
| 常驻城市 | 北京市 | 预测标签 | ||||
| 职业 | 预测标签 | |||||
| 终端设备 | 设备id | 事实标签 | ||||
| 手机型号 | 包含设备品牌、型号,可以评估用户的消费能力, | 事实标签 | ||||
| 活跃行为属性 | 首次访问时间 | 事实标签 | ||||
| 最后访问时间 | 事实标签 | |||||
| 30/60/90天内访问次数 | 一天内访问多次记做1次。 | 事实标签 | ||||
| 用户消费属性 | 首次购买时间 | 事实标签 | ||||
| 最后购买时间 | 事实标签 | |||||
| 30内购买次数 | 事实标签 | |||||
| 30天内消费金额 | 事实标签 | |||||
| 偏好属性 | 内容兴趣偏好 | 商品类目偏好 | 母婴,0.75;宠物,0.25 | 预测标签 | ||
| 频道偏好 | 电影,0.83;剧集,0.45;综艺,0.64 | 预测标签 | ||||
| 明星偏好 | 预测标签 | |||||
| 用户生命周期 | 用户生命周期标签 | 用户生命周期标签 | 进入业务后:新用户; 首次购买后:新客用户; 二次购买后:老客用户; xx天未活跃:流失用户; |
事实标签 |
具体流程:excel定义指标→数据库创建标签指标维度表,导入excel数据
2.8 本章小结34
本章主要介绍了如何结合业务场景去搭建刻画用户的数据指标体系。其中2.1节到2.5节介绍了一种从用户属性、用户行为、用户消费、风险控制和社交属性5个维度建立用户标签体系的思路,2.6节提供了一种基于应用场景搭建指标体系的思路。2.7节介绍了一种规范化命名标签的解决方案,可保证对每一个业务标签打上唯一的标签id。
第3章 标签数据存储35
3.1 Hive存储35
3.1.1 Hive数据仓库35
在数据仓库建模的过程中,主要涉及事实表和维度表的建模开发(图3-2)。
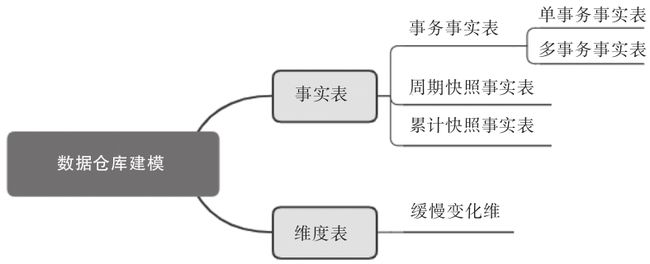
图3-2 数据仓库建模
事实表主要围绕业务过程设计,就应用场景来看主要包括事务事实表,周期快照事实表和累计快照事实表:
·事务事实表:用于描述业务过程,按业务过程的单一性或多业务过程可进一步分为单事务事实表和多事务事实表。其中单事务事实表分别记录每个业务过程,如下单业务记入下单事实表,支付业务记入支付事实表。多事务事实表在同一个表中包含了不同业务过程,如下单、支付、签收等业务过程记录在一张表中,通过新增字段来判断属于哪一个业务过程。当不同业务过程有着相似性时可考虑将多业务过程放到多事务事实表中。
·周期快照事实表:在一个确定的时间间隔内对业务状态进行度量。例如查看一个用户的近1年付款金额、近1年购物次数、近30日登录天数等。
·累计快照事实表:用于查看不同事件之间的时间间隔,例如分析用户从购买到支付的时长、从下单到订单完结的时长等。一般适用于有明确时间周期的业务过程。
维度表主要用于对事实属性的各个方面描述,例如,商品维度包括商品的价格、折扣、品牌、原厂家、型号等方面信息。
3.1.2 分区存储37
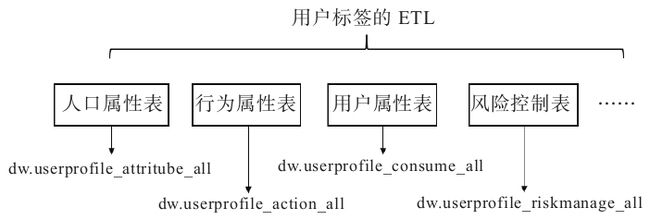
将用户标签开发成一张大的宽表,在这张宽表下放几十种类型标签,那么用户画像宽表的ETL将花费很长时间,且不便于向宽表中新增标签类型。
解决这种ETL花费时间较长的问题,可以从以下几个方面着手:
1、将数据分区存储,分别执行作业
分表、分区存储的解决方案示例:
分别建立对应的标签表进行分表存储对应的标签数据。如图3-3所示。
·人口属性表:dw.userprofile_attritube_all;
·行为属性表:dw.userprofile_action_all;
·用户消费表:dw.userprofile_consume_all;
·风险控制表:dw.userprofile_riskmanage_all;
·社交属性表:dw.userprofile_social_all
图3-3 用户标签数据ETL逻辑示意图
例如创建用户的人口属性宽表:
2、标签脚本性能调优
3、基于一些标签共同的数据来源开发中间表
3.1.3 标签汇聚39
在3.1.2节的案例中,用户的每个标签都插入到相应的分区下面,但是对一个用户来说,打在他身上的全部标签存储在不同的分区下面。为了方便分析和查询,需要将用户身上的标签做聚合处理。
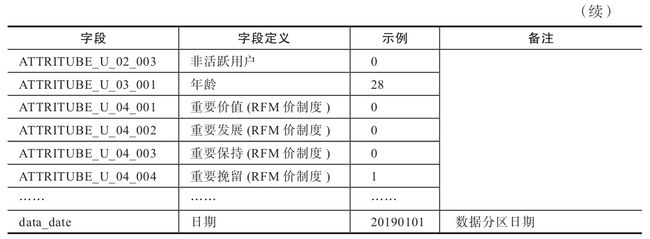
标签汇聚后将一个每个用户身上的全量标签汇聚到一个字段中,表结构设计如下:
CREATE TABLE `dw.userprofile_userlabel_map_all`(
`userid` string COMMENT 'userid',
`userlabels` map COMMENT 'tagsmap'',)
COMMENT 'userid 用户标签汇聚'
PARTITIONED BY ( `data_date` string COMMENT '数据日期') 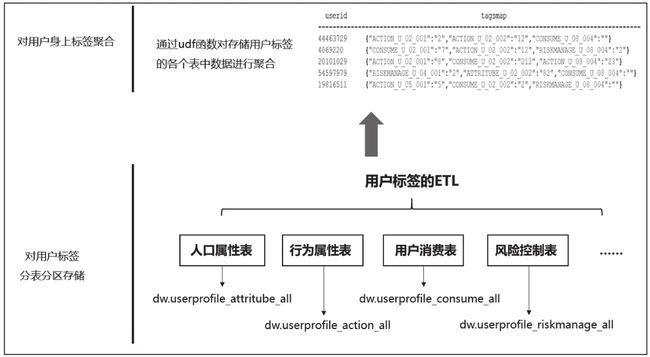
图3-4 标签汇聚数据
开发udf函数“cast_to_json”将用户身上的标签汇聚成json字符串,执行命令将按分区存储的标签进行汇聚:
insert overwrite table dw.userprofile_userlabel_map_all partition(data_date= "data_date")
select userid,
cast_to_json(concat_ws(',',collect_set(concat(labelid,':',labelweight)))) as userlabels
from “用户各维度的标签表”
where data_date= " data_date "
group by userid
--1、concat_ws(seperator, string s1, string s2...)
--功能:制定分隔符将多个字符串连接起来,实现“列转行”
--例子:常常结合group by与collect_set使用
--有表结构a string , b string , c int
--数据为
--c d 1
--c d 2
--c d 3
--e f 4
--e f 5
--e f 6
--想得到
--c d 1,2,3
--e f 4,5,6
--2、collect_set 函数,有两个作用,第一个是去重,去除group by后的重复元素,
--第二个是形成一个集合,将group by后属于同一组的成为一个集合
--数据为
--张三,大唐双龙传
--李四,天下无贼
--张三,神探狄仁杰
--李四,霸王别姬
--李四,霸王别姬
--王五,机器人总动员
--王五,放牛班的春天
--王五,盗梦空间
--得到
--张三 ["大唐双龙传","神探狄仁杰"]
--李四 ["天下无贼","霸王别姬"]
--王五 ["机器人总动员","放牛班的春天","盗梦空间"]汇聚后用户标签的存储格式如图3-5所示

图3-5 标签汇聚数据
将用户身上的标签进行聚合便于查询和计算。例如,在画像产品中,输入用户id后通过直接查询该表,解析标签id和对应的标签权重后,即可在前端展示该用户的相关信息(如图3-6所示)。
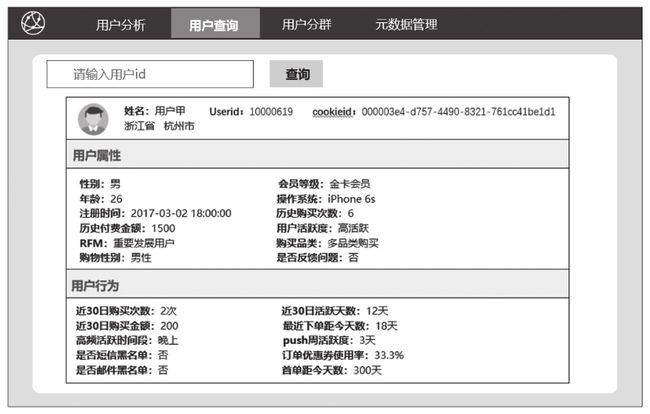
图3-6 用户标签查询
3.1.4 ID-MAP 41
ID-MApping,即把用户不同来源的身份标识通过数据手段识别为同一个主体。用户的属性、行为相关数据分散在不同的数据来源中,通过ID-MApping能够把用户在不同场景下的行为串联起来,消除数据孤岛。图3-7展示了用户与设备间的多对多关系。图3-8展示了同一用户在不同平台间的行为示意图。
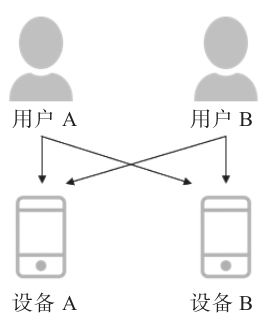
▲图3-7 用户和设备间的多对多关系
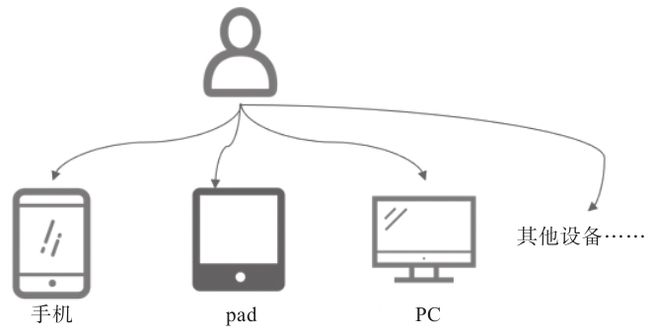
图3-8 串联同一个用户在不同平台间行为
举例来说,用户在未登录App的状态下,在App站内访问、搜索相关内容时,记录的是设备id(即cookieid)相关的行为数据。而用户在登录App后,访问、收藏、下单等相关的行为记录的是账号id(即userid)相关行为数据。虽然是同一个用户,但其在登录和未登录设备时记录的行为数据之间是未打通的。通过ID-MApping打通userid和cookieid的对应关系,可以在用户登录、未登录设备时都能捕获其行为轨迹。
下面通过一个案例介绍如何通过Hive的ETL工作完成ID-Mapping的数据清洗工作。

3-9 ID-Mapping拉链表
创建ID-Mapping拉链表
CREATE TABLE `dw.cookie_user_zippertable`(
`userid` string COMMENT '账号ID',
`cookieid` string COMMENT '设备ID',
`start_date` string COMMENT 'start_date',
`end_date` string COMMENT 'end_date')
COMMENT 'id-map拉链表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
第一步:从埋点表和访问日志表里面获取到cookieid和userid同时出现的访问记录。ods.page_event_log是埋点日志表,
ods.page_view_log是访问日志表,
将获取到的userid和cookieid信息插入cookieid-userid关系表(ods.cookie_user_signin)中。代码执行如下:
此处到底用UNION ALL 还是UNION?
INSERT OVERWRITE TABLE ods.cookie_user_signin PARTITION (data_date = '${data_date}')
SELECT t.* FROM (
SELECT userid,cookieid,from_unixtime(eventtime,'yyyyMMdd') as signdate
FROM ods.page_event_log -- 埋点表
WHERE data_date = '${data_date}'
UNION ALL
SELECT userid,cookieid,from_unixtime(viewtime,'yyyyMMdd') as signdate
FROM ods.page_view_log -- 访问日志表
WHERE data_date = '${data_date}'
) t第二步:将每天新增到ods.cookie_user_signin表中的数据与拉链表历史数据做比较,如果有变化或新增数据则进行更新。

任务执行如下。
INSERT OVERWRITE TABLE dw.cookie_user_zippertable
SELECT t.* FROM (
SELECT t1.userid,t1.cookieid,t1.start_date,
CASE WHEN t1.end_date = '99991231' AND t1.cookieid <> t2.cookieid THEN '${data_date}' -- userid一样但cookieid不一样,end_date生命周期结束
ELSE t1.end_date
END AS end_date
FROM dw.cookie_user_zippertable t1
LEFT JOIN (SELECT * FROM ods.cookie_user_signin WHERE data_date='${data_date}' )t2 ON t1.userid = t2.userid
UNION
--新增或userid一样但cookieid不一样
SELECT userid, cookieid, '${data_date}' AS start_date, '99991231' AS end_date
FROM ods.cookie_user_signin
WHERE data_date = '${data_date}'
) t对于该拉链表,可查看某日(如20190801)的快照数据。
select *
from dw.cookie_user_zippertable
where start_date<='20190801' and end_date>='20190801' 3.2 MySQL存储45
MySQL作为关系型数据库,在用户画像中可用于元数据管理、监控预警数据、结果集存储等应用中。下面详细介绍这3个应用场景。
3.2.1 元数据管理45
Hive适合于大数据量的批处理作业,对于量级较小的数据,MySQL具有更快的读写速度。Web端产品读写MySQL数据库会有更快的速度,方便标签的定义、管理。
在7.2节和7.3节中,我们会介绍元数据录入和查询功能,将相应的数据存储在MySQL中。用户标签的元数据表结构设计会在7.3节进行详细的介绍。这里给出了平台标签视图(如图3-11所示)和元数据管理页面(如图3-12所示)。

▲图3-11 平台标签视图
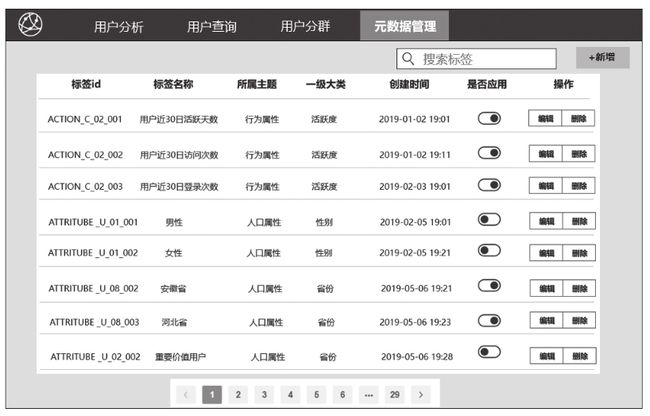
图3-12 标签编辑管理
平台标签视图中的标签元数据可以维护在MySQL关系数据库中,便于标签的编辑、查询和管理。
3.2.2 监控预警数据47
MySQL还可用于存储每天对ETL结果的监控信息。从整个画像调度流的关键节点来看,需要监控的环节主要包括对每天标签的产出量、服务层数据同步情况的监控等主要场景。图3-13所示是用户画像调度流主要模块,下面详细介绍。
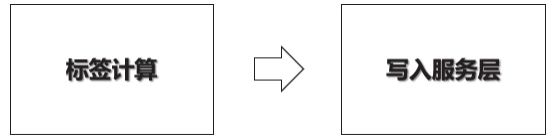
图3-13 用户画像调度流主要模块
1.标签计算数据监控
主要用于监控每天标签ETL的数据量是否出现异常,如果有异常情况则发出告警邮件,同时暂停后面的ETL任务。
2.服务层同步数据监控
服务层一般采用HBase、Elasticsearch等作为数据库存储标签数据供线上调用,将标签相关数据从Hive数仓向服务层同步的过程中,有出现差错的可能,因此需要记录相关数据在Hive中的数量及同步到对应服务层后的数量,如果数量不一致则触发告警。
在对画像的数据监控中,调度流每跑完相应的模块,就将该模块的监控数据插入MySQL中,当校验任务判断达到触发告警阈值时,发送告警邮件,同时中断后续的调度任务。待开发人员解决问题后,可重启后续调度。
3.2.3 结果集存储47
结果集可以用来存储多维透视分析用的标签、圈人服务用的用户标签、当日记录各标签数量,用于校验标签数据是否出现异常。
有的线上业务系统使用MySQL、Oracle等关系型数据库存储数据,如短信系统、消息推送系统等。在打通画像数据与线上业务系统时,需要考虑将存储在Hive中的用户标签相关数据同步到各业务系统,此时MySQL可用于存储结果集。
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互迁移的工具。它可以将一个关系型数据库(如MySQL、Oracle、PostgreSQL等)中的数据导入Hadoop的HDFS中,也可以将HDFS中的数据导入关系型数据库中。
3.3 HBase存储50
3.3.1 HBase简介50
HBase是一个高性能、列存储、可伸缩、实时读写的分布式存储系统,同样运行在HDFS之上。与Hive不同的是,HBase能够在数据库上实时运行,而不是跑MapReduce任务,适合进行大数据的实时查询。
画像系统中每天在Hive里跑出的结果集数据可同步到HBase数据库,用于线上实时应用的场景。
下面介绍几个基本概念:
·row key:用来表示唯一一行记录的主键,HBase的数据是按照row key的字典顺序进行全局排列的。访问HBase中的行只有3种方式:
·通过单个row key访问;
·通过row key的正则访问;
·全表扫描。
由于HBase通过rowkey对数据进行检索,而rowkey由于长度限制的因素不能将很多查询条件拼接在rowkey中,因此HBase无法像关系数据库那样根据多种条件对数据进行筛选。一般地,HBase需建立二级索引来满足根据复杂条件查询数据的需求。
Rowkey设计时需要遵循三大原则:
·唯一性原则:rowkey需要保证唯一性,不存在重复的情况。在画像中一般使用用户id作为rowkey。
·长度原则:rowkey的长度一般为10-100bytes。
·散列原则:rowkey的散列分布有利于数据均衡分布在每个RegionServer,可实现负载均衡。
·columns family:指列簇,HBase中的每个列都归属于某个列簇。列簇是表的schema的一部分,必须在使用表之前定义。划分columns family的原则如下:
·是否具有相似的数据格式;
·是否具有相似的访问类型。
3.3.2 应用场景52
某渠道运营人员为促进未注册的新安装用户注册、下单,计划通过App首页弹窗(如图3-15所示)发放红包或优惠券的方式进行引导。在该场景中可通过画像系统实现对应功能。
业务逻辑上,渠道运营人员通过组合用户标签(如“未注册用户”和“安装距今天数”小于××天)筛选出对应的用户群,然后选择将对应人群推送到“广告系统”(产品功能详见7.4节),这样每天画像系统的ETL调度完成后对应人群数据就被推送到HBase数据库进行存储。满足条件的新用户来访App时,由在线接口读取HBase数据库,在查询到该用户时为其推送该弹窗。
组合用户标签→将对应人群推送到“广告系统”→对应人群数据就被推送到HBase数据库→满足条件的新用户来访App→由在线接口读取HBase数据库→为其推送该弹窗
3.3.3 工程化案例52
运营人员在画像系统(详见第7章)中根据业务规则定义组合用户标签筛选出用户群,并将该人群上线到广告系统中(如图3-16所示)。
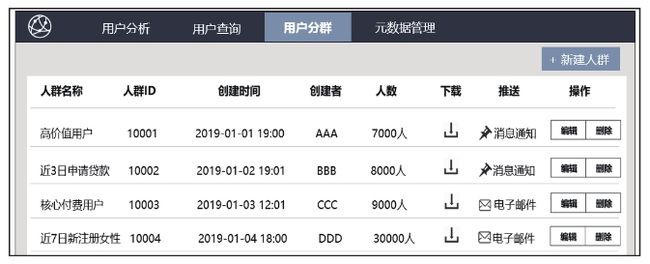
图3-16 将待运营人群上线到广告系统
在业务人员配置好规则后,下面我们来看在数据调度层面是如何运行的。
用户标签数据经过ETL将每个用户身上的标签聚合后插入到目标表中,如dw.userprofile_userlabel_map_all(详见3.1.3节)。聚合后数据存储为每个用户id,以及他身上对应的标签集合,数据格式如图3-17所示。

步骤:
1、用户标签数据经过ETL将每个用户身上的标签聚合后插入到目标表中dw.userprofile_userlabel_map_all
2、将Hive中的数据导入HBase,便于线上接口实时调用库中数据。
3、在线接口在查询HBase中数据时,由于HBase无法像关系数据库那样根据多种条件对数据进行筛选(类似SQL语言中的where筛选条件)。一般地HBase需建立二级索引来满足根据复杂条件查询数据的需求,本案中选用Elasticsearch存储HBase索引数据
4、在组合标签查询对应的用户人群场景中,首先通过组合标签的条件在Elasticsearch中查询对应的索引数据,然后通过索引数据去HBase中批量获取rowkey对应的数据(Elasticsearch中的documentid和HBase中的rowkey都设计为用户id)。
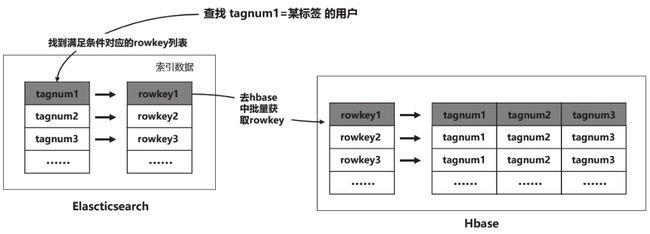
图3-21 基于Elasticsearch存储的HBase二级索引方案
3.4 Elasticsearch存储59
3.4.1 Elasticsearch简介59
Elasticsearch是一个开源的分布式(分布式:将不同的业务分布在在不同的地方 集群:将几台服务器集中在一起实现同一业务)全文检索引擎,可以近乎实时地存储、检索数据。而且可扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。对于用户标签查询、用户人群计算、用户群多维透视分析这类对响应时间要求较高的场景,也可以考虑选用Elasticsearch进行存储。
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用json作为文档格式。为了更清晰地理解Elasticsearch查询的一些概念,将其和关系数据库的类型进行对照,如图3-23所示。
在关系型数据库中查询数据时可通过选中数据库、表、行、列来定位所查找的内容,在Elasticsearch中通过索引(index)、类型(type)、文档(document)、字段来定位查找内容。一个Elasticsearch集群可以包括多个索引(数据库),也就是说,其中包含了很多类型(表),这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互可以使用Java API,也可以使用HTTP的RESTful API方式。
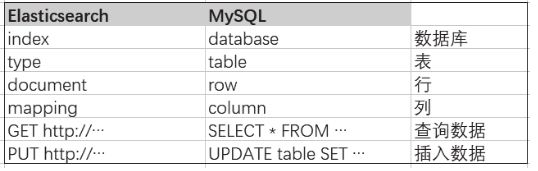
图3-23 Elasticsearch与关系数据库的对比
3.4.2 应用场景60
基于HBase的存储方案并没有解决数据的高效检索问题。在实际应用中,经常有根据特定的几个字段进行组合后检索的应用场景,而HBase采用rowkey作为一级索引,不支持多条件查询,如果要对库里的非rowkey进行数据检索和查询,往往需要通过MapReduce等分布式框架进行计算,时间延迟上会比较高,难以同时满足用户对于复杂条件查询和高效率响应这两方面的需求。
为了既能支持对数据的高效查询,同时也能支持通过条件筛选进行复杂查询,需要在HBase上构建二级索引,以满足对应的需要。在本案中我们采用Elasticsearch存储HBase的索引信息,以支持复杂高效的查询功能。
主要查询过程包括:
1)在Elasticsearch中存放用于检索条件的数据,并将rowkey也存储进去;
2)使用Elasticsearch的API根据组合标签的条件查询出rowkey的集合;
3)使用上一步得到的rowkey去HBase数据库查询对应的结果(见图3-24)。
HBase数据存储数据的索引放在Elasticsearch中,实现了数据和索引的分离。在Elasticsearch中documentid是文档的唯一标识,在HBase中rowkey是记录的唯一标识。在工程实践中,两者可同时选用用户在平台上的唯一标识(如userid或deviceid)作为rowkey或documentid,进而解决HBase和Elasticsearch索引关联的问题。
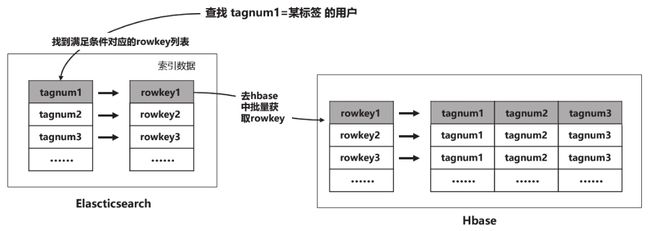
图3-24 基于Elasticsearch存储的HBase二级索引方案
3.4.3 工程化案例64
下面通过一个工程案例来讲解实现画像产品中“用户人群”和“人群分析”功能对用户群计算秒级响应的一种解决方案。
在每天的ETL调度中,如图3-28所示,在标签调度完成且通过校验后(图3-28中的“标签监控预警”任务执行完成后),需要将Hive计算的标签数据导入Elasticsearch中。
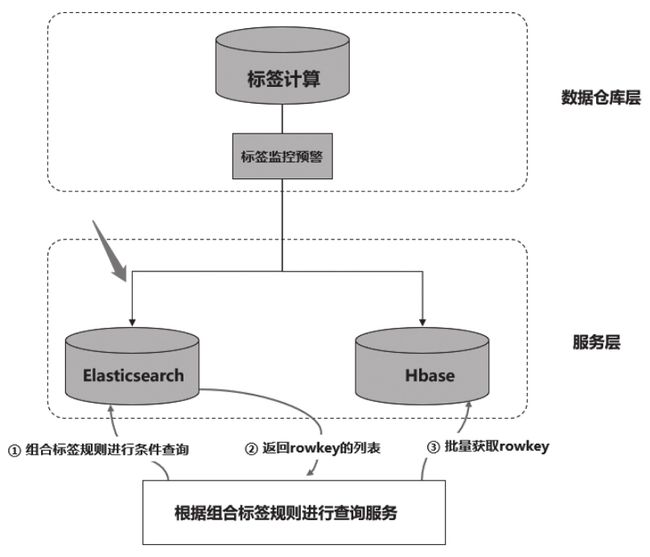
在与Elasticsearch数据同步完成并通过校验后,向在MySQL中维护的状态表中插入一条状态记录,表示当前日期的Elasticsearch数据可用,线上计算用户人群的接口则读取最近日期对应的数据。如果某天因为调度延迟等方面的原因,没有及时将当日数据导入Elasticsearch中,接口也能读取最近一天对应的数据,是一种可行的灾备方案。
例如,数据同步完成后向MySQL状态表“elasticsearch_state”中插入记录(如图3-29所示),当日数据产出正常时,state字段为“0”,产出异常时为“1”。图3-29中1月20日导入的数据出现异常,则“state”状态字段置1,线上接口扫描该状
3.5 本章小结67
第4章 标签数据开发69
4.1 统计类标签开发69
4.1.1 近30日购买行为标签案例70
4.1.2 最近来访标签案例73
4.2 规则类标签开发74
4.2.1 用户价值类标签案例75
4.2.2 用户活跃度标签案例79
4.3 挖掘类标签开发84
4.3.1 案例背景84
4.3.2 特征选取及开发85
4.3.3 文本分词处理86
因书中部分代码书写有误,整体思想是对的,所以此博客代码和书中代码稍有偏差,代码中需要的资料下载链接:
链接:https://pan.baidu.com/s/1kMmjh4-nhCMumyRrUKHEzA
提取码:v5bn
import jieba
import os
import pickle #持久化
from numpy import *
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer #TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer #TF_IDF向量生成类
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯算法
from sklearn import metrics
def readFile(path):
with open(path,'r',errors='ignore') as file: #文档中编码有些问题,所有用errors过滤错误
content = file.read()
return content
def saveFile(path,result):
with open(path,'w',errors='ignore') as file:
file.write(result)
def segText(inputPath,resultPath):
fatherLists = os.listdir(inputPath) #主目录
for eachDir in fatherLists: #遍历主目录中各个文件夹
eachPath = inputPath + eachDir + "/" #保存主目录中每个文件夹目录,便于遍历二级文件
each_resultPath = resultPath + eachDir + "/"#分词结果文件存入的目录
if not os.path.exists(each_resultPath):
os.makedirs(each_resultPath)
childLists = os.listdir(eachPath) #获取每个文件夹中的各个文件
for eachFile in childLists: #遍历每个文件夹中的子文件
eachPathFile = eachPath + eachFile #获得每个文件路径
print(eachFile)
content = readFile(eachPathFile)#调用上面函数读取内容
#content = str(content)
result = (str(content)).replace("\r\n","").strip()#删除多余空行与空格
#result = content.replace("\r\n","").strip()
cutResult = jieba.cut(result)#默认方式分词,分词结果用空格隔开
saveFile(each_resultPath+eachFile," ".join(cutResult))#调用上面函数保存文件
stopWordList = getStopWord("./chinese_stop_words.txt")#获取停用词
#1、文本分词处理
os.chdir('D://1corpus_chapter//')
#训练集
inputPath="./train/train_corpus/"
resultPath="./train/train_segresult/"
segText(inputPath,resultPath) #分词,第一个是分词输入,第二个参数是结果保存的路径
#测试集
inputPath="./test/test_corpus/"
resultPath="./test/test_segresult/"
segText(inputPath,resultPath)
#---------------------------------------第1步结束---------------------------------4.3.4 数据结构处理89
import jieba
import os
import pickle #持久化
from numpy import *
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer #TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer #TF_IDF向量生成类
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯算法
from sklearn import metrics
def bunchSave(inputFile,outputFile):
catelist = os.listdir(inputFile)
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
bunch.target_name.extend(catelist)#将类别保存到Bunch对象中
for eachDir in catelist:
eachPath = inputFile + eachDir + "/"
fileList = os.listdir(eachPath)
for eachFile in fileList:#二级目录中的每个子文件
fullName = eachPath + eachFile #二级目录子文件全路径
bunch.label.append(eachDir)#当前分类标签
bunch.filenames.append(fullName) #保存当前文件的路径
bunch.contents.append(readFile(fullName).strip()) #保存文件词向量
with open(outputFile,'wb') as file_obj: #持久化必须用二进制访问模式打开
pickle.dump(bunch,file_obj)
#2、数据结构处理
#训练集
inputFile="./train/train_segresult/"
outputFile="./train/train_set.dat"
bunchSave(inputFile,outputFile)#输入分词,输出分词向量
#测试集
inputFile="./test/test_segresult/"
outputFile="./test/test_set.dat"
bunchSave(inputFile,outputFile)
#---------------------------------------第2步结束---------------------------------4.3.5 文本TF-IDF权重90
import jieba
import os
import pickle #持久化
from numpy import *
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer #TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer #TF_IDF向量生成类
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯算法
from sklearn import metrics
def readBunch(path):
with open(path,'rb') as file:
bunch = pickle.load(file)
return bunch
def writeBunch(path,bunchFile):
with open(path,'wb') as file:
pickle.dump(bunchFile,file)
def getStopWord(inputFile):
stopWordList = readFile(inputFile).splitlines()
return stopWordList
def getTFIDFMat(inputPath,stopWordList,outputPath):#求得TF-IDF向量
bunch = readBunch(inputPath)
#盲猜tdm是term-document matrix(文档词条矩阵)
tfidfspace = Bunch(target_name = bunch.target_name,label=bunch.label,filenames= bunch.filenames,tdm=[],vocabulary={})
#初始化向量空间 max_df/min_df当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
vectorizer = TfidfVectorizer(stop_words=stopWordList,sublinear_tf=True,max_df=0.5)
transformer = TfidfTransformer() #该类会统计每个词语的TF-IDF权值
#文本转化为词频矩阵,单独保存字典文件
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
writeBunch(outputPath,tfidfspace)
def getTestSpace(testSetPath,trainSpacePath,stopWordList,testSpacePath):
bunch = readBunch(testSetPath)
#构建测试集TF-IDF向量空间
testSpace = Bunch(target_name = bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={})
#导入训练集的词袋
trainbunch = readBunch(trainSpacePath)
#使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量
vectorizer = TfidfVectorizer(stop_words=stopWordList,sublinear_tf=True,max_df=0.5,vocabulary=trainbunch.vocabulary)
transformer = TfidfTransformer()
testSpace.tdm = vectorizer.fit_transform(bunch.contents)
testSpace.vocabulary = trainbunch.vocabulary
#持久化
writeBunch(testSpacePath,testSpace)
#3、文本TF-IDF权重
#训练集
inputPath="./train/train_set.dat"
outputPath="./train/train_stfidfspace.dat"
getTFIDFMat(inputPath,stopWordList,outputPath)#输入词向量,输出特征空间
#测试集
testSetPath="./test/test_set.dat"
trainSpacePath="./train/train_stfidfspace.dat"
testSpacePath="./test/testspace.dat"
getTestSpace(testSetPath,trainSpacePath,stopWordList,testSpacePath)
#---------------------------------------第3步结束---------------------------------4.3.6 朴素贝叶斯分类92
import jieba
import os
import pickle #持久化
from numpy import *
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer #TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer #TF_IDF向量生成类
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯算法
from sklearn import metrics
def readBunch(path):
with open(path,'rb') as file:
bunch = pickle.load(file)
return bunch
def bayesAlgorithm(trainPath,testPath):
trainSet = readBunch(trainPath)
testSet = readBunch(testPath)
clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm,trainSet.label)
print(shape(trainSet.tdm))
print(shape(testSet.tdm))
predicted = clf.predict(testSet.tdm)
total = len(predicted)
rate=0
for flabel,fileName,expct_cate in zip(testSet.label,testSet.filenames,predicted):
if flabel != expct_cate:
rate +=1
print(fileName,":实际类别:",flabel,"-->预测类别:",expct_cate)
print("erroe rate:",float(rate)*100/float(total),"%")
return predicted
def classification_result(actual, predict):
print('精度:{0:.3f}'.format(metrics.precision_score(actual, predict,average='weighted')))
print('召回:{0:0.3f}'.format(metrics.recall_score(actual, predict,average='weighted')))
print('f1-score:{0:.3f}'.format(metrics.f1_score(actual, predict,average='weighted')))
#4、朴素贝叶斯分类
trainPath="./train/train_stfidfspace.dat"
testPath="./test/testspace.dat"
predict = bayesAlgorithm(trainPath,testPath)
classification_result(readBunch("./test/test_set.dat").label, predict)
#---------------------------------------第4步结束---------------------------------4.3.7 分词-数据结构-向量化-文本分类整体代码
import pandas as pd
"""
机器学习笔记-文本分类(四)代码实现
作者:sf705
链接:https://www.jianshu.com/p/915b0ab166e5
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处
主要步骤
• 将训练集中的所有文本用jieba分词保存到另外一个文件
• 统计分词后文本的TF-IDF,转化为词频向量
• 去掉停用词
• 应用sklearn分类
"""
import jieba
import os
import pickle #持久化
from numpy import *
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer #TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer #TF_IDF向量生成类
from sklearn.datasets.base import Bunch
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯算法
from sklearn import metrics
os.chdir('D://good_study//NLP//用户画像//用户画像--方法论与工程化解决方法//案例//1corpus_chapter//')
##/*-------------------------------------*/
##/* 主程序
##/*-------------------------------------*/
def readFile(path):
with open(path,'r',errors='ignore') as file: #文档中编码有些问题,所有用errors过滤错误
content = file.read()
return content
def saveFile(path,result):
with open(path,'w',errors='ignore') as file:
file.write(result)
def segText(inputPath,resultPath):
fatherLists = os.listdir(inputPath) #主目录
for eachDir in fatherLists: #遍历主目录中各个文件夹
eachPath = inputPath + eachDir + "/" #保存主目录中每个文件夹目录,便于遍历二级文件
each_resultPath = resultPath + eachDir + "/"#分词结果文件存入的目录
if not os.path.exists(each_resultPath):
os.makedirs(each_resultPath)
childLists = os.listdir(eachPath) #获取每个文件夹中的各个文件
for eachFile in childLists: #遍历每个文件夹中的子文件
eachPathFile = eachPath + eachFile #获得每个文件路径
print(eachFile)
content = readFile(eachPathFile)#调用上面函数读取内容
#content = str(content)
result = (str(content)).replace("\r\n","").strip()#删除多余空行与空格
#result = content.replace("\r\n","").strip()
cutResult = jieba.cut(result)#默认方式分词,分词结果用空格隔开
saveFile(each_resultPath+eachFile," ".join(cutResult))#调用上面函数保存文件
def bunchSave(inputFile,outputFile):
catelist = os.listdir(inputFile)
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
bunch.target_name.extend(catelist)#将类别保存到Bunch对象中
for eachDir in catelist:
eachPath = inputFile + eachDir + "/"
fileList = os.listdir(eachPath)
for eachFile in fileList:#二级目录中的每个子文件
fullName = eachPath + eachFile #二级目录子文件全路径
bunch.label.append(eachDir)#当前分类标签
bunch.filenames.append(fullName) #保存当前文件的路径
bunch.contents.append(readFile(fullName).strip()) #保存文件词向量
with open(outputFile,'wb') as file_obj: #持久化必须用二进制访问模式打开
pickle.dump(bunch,file_obj)
def readBunch(path):
with open(path,'rb') as file:
bunch = pickle.load(file)
return bunch
def writeBunch(path,bunchFile):
with open(path,'wb') as file:
pickle.dump(bunchFile,file)
def getStopWord(inputFile):
stopWordList = readFile(inputFile).splitlines()
return stopWordList
def getTFIDFMat(inputPath,stopWordList,outputPath):#求得TF-IDF向量
bunch = readBunch(inputPath)
#盲猜tdm是term-document matrix(文档词条矩阵)
tfidfspace = Bunch(target_name = bunch.target_name,label=bunch.label,filenames= bunch.filenames,tdm=[],vocabulary={})
#初始化向量空间 max_df/min_df当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
vectorizer = TfidfVectorizer(stop_words=stopWordList,sublinear_tf=True,max_df=0.5)
transformer = TfidfTransformer() #该类会统计每个词语的TF-IDF权值
#文本转化为词频矩阵,单独保存字典文件
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
writeBunch(outputPath,tfidfspace)
def getTestSpace(testSetPath,trainSpacePath,stopWordList,testSpacePath):
bunch = readBunch(testSetPath)
#构建测试集TF-IDF向量空间
testSpace = Bunch(target_name = bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={})
#导入训练集的词袋
trainbunch = readBunch(trainSpacePath)
#使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量
vectorizer = TfidfVectorizer(stop_words=stopWordList,sublinear_tf=True,max_df=0.5,vocabulary=trainbunch.vocabulary)
transformer = TfidfTransformer()
testSpace.tdm = vectorizer.fit_transform(bunch.contents)
testSpace.vocabulary = trainbunch.vocabulary
#持久化
writeBunch(testSpacePath,testSpace)
def bayesAlgorithm(trainPath,testPath):
trainSet = readBunch(trainPath)
testSet = readBunch(testPath)
clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm,trainSet.label)
print(shape(trainSet.tdm))
print(shape(testSet.tdm))
predicted = clf.predict(testSet.tdm)
total = len(predicted)
rate=0
for flabel,fileName,expct_cate in zip(testSet.label,testSet.filenames,predicted):
if flabel != expct_cate:
rate +=1
print(fileName,":实际类别:",flabel,"-->预测类别:",expct_cate)
print("erroe rate:",float(rate)*100/float(total),"%")
return predicted
def classification_result(actual, predict):
print('精度:{0:.3f}'.format(metrics.precision_score(actual, predict,average='weighted')))
print('召回:{0:0.3f}'.format(metrics.recall_score(actual, predict,average='weighted')))
print('f1-score:{0:.3f}'.format(metrics.f1_score(actual, predict,average='weighted')))
os.chdir('D://good_study//NLP//用户画像//用户画像--方法论与工程化解决方法//案例//1corpus_chapter//')
stopWordList = getStopWord("./chinese_stop_words.txt")#获取停用词
#1、文本分词处理
#训练集
inputPath="./train/train_corpus/"
resultPath="./train/train_segresult/"
segText(inputPath,resultPath) #分词,第一个是分词输入,第二个参数是结果保存的路径
#测试集
inputPath="./test/test_corpus/"
resultPath="./test/test_segresult/"
segText(inputPath,resultPath)
#---------------------------------------第1步结束---------------------------------
#2、数据结构处理
#训练集
inputFile="./train/train_segresult/"
outputFile="./train/train_set.dat"
bunchSave(inputFile,outputFile)#输入分词,输出分词向量
#测试集
inputFile="./test/test_segresult/"
outputFile="./test/test_set.dat"
bunchSave(inputFile,outputFile)
#---------------------------------------第2步结束---------------------------------
#3、文本TF-IDF权重
#训练集
inputPath="./train/train_set.dat"
outputPath="./train/train_stfidfspace.dat"
getTFIDFMat(inputPath,stopWordList,outputPath)#输入词向量,输出特征空间
#测试集
testSetPath="./test/test_set.dat"
trainSpacePath="./train/train_stfidfspace.dat"
testSpacePath="./test/testspace.dat"
getTestSpace(testSetPath,trainSpacePath,stopWordList,testSpacePath)
#---------------------------------------第3步结束---------------------------------
#4、朴素贝叶斯分类
trainPath="./train/train_stfidfspace.dat"
testPath="./test/testspace.dat"
predict = bayesAlgorithm(trainPath,testPath)
classification_result(readBunch("./test/test_set.dat").label, predict)
#---------------------------------------第4步结束---------------------------------4.3.7 分词-数据结构-向量化-文本分类小知识
tf-idf计算:
参考资料:sklearn-TfidfVectorizer彻底说清楚
sklearn-TfidfVectorizer彻底说清楚 - 知乎
# 导入TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from math import log
# 实例化tf实例
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
# 输入训练集矩阵,每行表示一个文本
train = ["chinese beijing chinese",
"chinese chinese shanghai",
"chinese macao",
"tokyo japan chinese"]
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式(virtual switch matrix 虚拟交换矩阵)
tv_fit = tv.fit_transform(train)
# 查看一下构建的词汇表
tv.get_feature_names()
#Out[10]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
# 查看输入文本列表的VSM矩阵
tv_fit.toarray()
#Out[8]:
#array([[1.91629073, 2. , 0. , 0. , 0. , 0. ],
# [0. , 2. , 0. , 0. , 1.91629073, 0. ],
# [0. , 1. , 0. , 1.91629073, 0. , 0. ],
# [0. , 1. , 1.91629073, 0. , 0. , 1.91629073]])
#idf-beijing
print('beijing',(1+log((4+1)/(1+1))))
beijing=(1+log((4+1)/(1+1)))
#idf-chinese
print('chinese',(1+log((1+4)/(1+4))))
chinese=(1+log(4/4))
#idf-japan
print('japan',(1+log((4+1)/(1+1))))
japan=(1+log((4+1)/(1+1)))
#idf-macao
print('macao',(1+log((4+1)/(1+1))))
macao=(1+log((4+1)/(1+1)))
#idf-shanghai
print('shanghai',(1+log((4+1)/(1+1))))
shanghai=(1+log((4+1)/(1+1)))
#idf-tokyo
print('tokyo',(1+log((4+1)/(1+1))))
tokyo=(1+log((4+1)/(1+1)))过滤掉出现太多的无意义词语
"""目的:过滤掉出现太多的无意义词语
1.max_df/min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0
当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
这样就可以帮助我们过滤掉出现太多的无意义词语,如下面的"我"就被过滤(虽然这里“我”的排比在文学上是很重要的)。"""
# 导入TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from math import log
# 输入训练集矩阵,每行表示一个文本
train = ["chinese beijing chinese",
"chinese beijing shanghai",
"chinese macao beijing japan",
"tokyo japan chinese"]
# 实例化tf实例
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式(virtual switch matrix 虚拟交换矩阵)
tv_fit = tv.fit_transform(train)
# 查看一下构建的词汇表
feature_names=tv.get_feature_names()
['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
# 过滤出现在超过75%的句子中的词语,chinese出现在句子中100%,beijing是75%,故只有chinese超过75%
tfidf_model4 = TfidfVectorizer(max_df=0.75).fit(train)
# 查看一下构建的词汇表
tfidf_model4.get_feature_names()
#哪个词被过滤了
print(set(feature_names)-set(tfidf_model4.get_feature_names()) #{'chinese'})
# 过滤出现在超过74%的句子中的词语,利用beijing75%这个临界点,来理解max_df
tfidf_model4 = TfidfVectorizer(max_df=0.74).fit(train)
#哪个词被过滤了
print(set(feature_names)-set(tfidf_model4.get_feature_names()) #{'beijing', 'chinese'}
# 过滤出现在超过50%的句子中的词语
tfidf_model4 = TfidfVectorizer(max_df=0.5).fit(train)
#哪个词被过滤了
print(set(feature_names)-set(tfidf_model4.get_feature_names()) #{'beijing', 'chinese'}
# 过滤出现在超过49%的句子中的词语
tfidf_model4 = TfidfVectorizer(max_df=0.49).fit(train)
#哪个词被过滤了
print(set(feature_names)-set(tfidf_model4.get_feature_names()) #{'beijing', 'chinese', 'japan'}4.4 流式计算标签开发95
4.4.1 流式标签建模框架95
4.4.2 Kafka简介96
4.4.3 Spark Streaming集成Kafka97
4.4.4 标签开发及工程化99
4.5 用户特征库开发104
4.5.1 特征库规划105
4.5.2 数据开发107
4.5.3 其他特征库规划111
4.6 标签权重计算112
4.6.1 TF-IDF词空间向量112
TF-IDF算法用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,常用于计算标签的重要程度,一个标签的重要程度随着它在一篇文章出现的次数成正比,随着它在整个文档集中出现的次数成反比。
我们用W(U,T)表示一个标签T被用于标记用户U的次数,用TF(U,T)表示这个标签在用户U所有标签中所占的比重。
TF为词频即词条在某文档中出现的频率,TF(U,T)=W(U,T)/ΣW(U,Ti),即TF=该标签标记该用户的次数 / 该用户全部标签的次数
IDF为逆向文件频率即标签T在全部标签中的稀缺程度,IDF(U,T)=ΣW(Ui,Ti) / ΣW(Ui,T),即IDF=全部用户标签的次数 / 用户包含T标签的次数
实例
| 标签次数 | 标签A | 标签B | 标签C | 标签D |
| 用户1 | 7 | 9 | 3 | 1 |
| 用户2 | 8 | 5 | 4 | 11 |
| 用户3 | 2 | 6 | 0 | 10 |
对于标签A,TF(用户1,标签A)=7/(7+9+3+1),即TF(U,T)=W(U,T)/ΣW(U,Ti),即TF=该标签标记该用户的次数 (紫色) / 该用户全部标签的次数(紫色橘色)
IDF(用户1,标签A)=66/17,即IDF(U,T)=ΣW(Ui,Ti) / ΣW(Ui,T),即IDF=全部用户标签的次数(7+9+3+1+8+5+4+11 2+6+0+10=66) / 用户包含A标签的次数(7+8+2=17)
则该标签对于该用户的重要程度即该标签的权重值=TF*IDF=7/20 * 66/17
4.6.2 时间衰减系数114
牛顿冷却定律:F(t)=初始温度×exp(–×间隔的时间)
import math
#根据用户行为特征库的字段:行为时间可以计算距今天数
fo = open("time_delay.txt","w")
for x in range(0, 365+1):
y = 1/math.exp(0.02 * x)
line = str(x)+","+ format(y, '.5f')
print(x,y,line)
fo.write(line + "\n")
fo.close()4.6.3 标签权重配置115
4.7 标签相似度计算116
4.7.1 案例场景116
4.7.2 数据开发118
4.8 组合标签计算122
4.8.1 应用场景122
4.8.2 数据计算123
4.9 数据服务层开发124
4.9.1 推送至营销系统125
4.9.2 接口调用服务127
4.10 GraphX图计算用户129
4.10.1 图计算理论及应用场景129
4.10.2 数据开发案例132
4.11 本章小结135
第5章 开发性能调优137
5.1 数据倾斜调优137
5.2 合并小文件141
5.3 缓存中间数据143
5.4 开发中间表144
5.5 本章小结145
第6章 作业流程调度146
6.1 crontab命令调度146
6.2 Airflow工作平台148
6.2.1 基础概念149
6.2.2 Airflow服务构成150
6.2.3 Airflow安装151
6.2.4 主要模块功能151
6.2.5 工作流调度155
6.2.6 脚本实例155
6.2.7 常用命令行158
6.2.8 工程化调度方案158
6.3 数据监控预警161
6.3.1 标签监控预警161
6.3.2 服务层预警162
6.4 ETL异常排查164
6.5 本章小结166
第7章 用户画像产品化167
7.1 即时查询167
7.2 标签视图与标签查询169
7.3 元数据管理171
7.4 用户分群功能173
7.5 人群分析功能175
7.6 本章小结177
第8章 用户画像应用178
8.1 经营分析178
8.1.1 商品分析178
8.1.2 用户分析179
8.1.3 渠道分析180
8.1.4 漏斗分析185
8.1.5 客服话术186
8.1.6 人群特征分析186
8.2 精准营销187
8.2.1 短信/邮件营销187
8.2.2 效果分析188
8.3 个性化推荐与服务189
8.4 本章小结190
第9章 实践案例详解191
9.1 风控反欺诈预警191
9.1.1 应用背景191
9.1.2 用户画像切入点192
9.2 A/B人群效果测试193
9.2.1 案例背景194
9.2.2 用户画像切入点194
9.2.3 效果分析195
9.3 用户生命周期划分与营销195
9.3.1 生命周期划分196
9.3.2 不同阶段的用户触达策略201
9.3.3 画像在生命周期中的应用204
9.3.4 应用案例206
9.4 高价值用户实时营销209
9.4.1 项目应用背景209
9.4.2 用户画像切入点209
9.4.3 HBase应用场景小结209
9.5 短信营销用户211
9.5.1 案例背景211
9.5.2 画像切入及其应用效果211
9.6 Session行为分析应用213
9.6.1 关于用户行为分析213
9.6.2 案例背景218
9.6.3 特征构建219
9.6.4 分析方法与结论221
9.7 人群效果监测报表搭建228
9.7.1 案例背景228
9.7.2 逻辑梳理228
9.7.3 自动报表邮件237
9.8 基于用户特征库筛选目标人群239
9.8.1 案例背景239
9.8.2 应用方式及效果240
9.9 本章小结241
附录 某产品用户画像项目规划文档242
10 其他案例实践
10.1 每个用户最喜欢的标签、每个标签最热的内容、热榜/最新/人工推荐等列表
第一步、根据用户看过的内容列表,统计出用户、标签、频次,即每个用户最喜欢的标签
1.筛选出某人(userId=1)的每条电影记录,包含其电影打分、打分时间、打的标签

2.拆分标签,并匹配出该标签所在记录的评分rating

3.每个标签genre汇总rating后归一化,
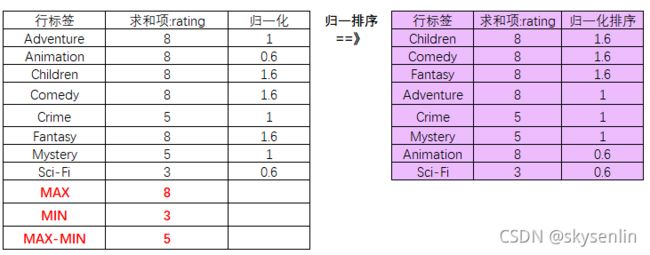
归一化:(每个标签rating - 标签rating最小值) / (标签rating最大值-标签rating最小值)
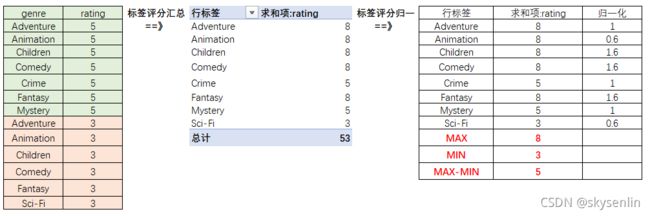
4.目标用户最喜欢的标签排序
5.整体流程

第二步、根据用户看过的内容列表,统计出标签、内容、频次,即每个标签最热的内容
1.筛选出包含某标签(genre = Adventure)的每条电影记录,并汇总每个电影的评分
 2.该标签下每个电影的评分汇总后归一化并排序
2.该标签下每个电影的评分汇总后归一化并排序

第三步、对每个用户,根据最喜欢的标签取出标签的热榜/最新/人工推荐等列表,加权得到推荐列表

所需数据链接:
链接:https://pan.baidu.com/s/1jggYSGcEWSy7OBpfVJwuxA
提取码:wemf
完整代码:
#!/usr/bin/env python
# coding: utf-8
""" Python实现基于标签的推荐系统
标签:泛指分类、关键词、作者、标签等一切离散的内容特征
实现思路:
1. 根据用户看过的内容列表,聚合统计出(用户、标签、频次)数据,即每个用户最喜欢的标签
2. 根据用户看过的内容列表,聚合统计出(标签、内容、频次)数据,即每个标签最热的内容
3. 对每个用户,根据最喜欢的标签取出标签的热榜/最新/人工推荐等列表,加权得到推荐列表
"""
import pandas as pd
import numpy as np
import os
os.chdir("D:\\jupyter\\NLP\\推荐系统\\")
# ### 1. 读取MovieLens数据集
df = pd.merge(
left=pd.read_csv("./datas/ml-latest-small/ratings.csv"),
right=pd.read_csv("./datas/ml-latest-small/movies.csv"),
left_on="movieId", right_on="movieId"
)
df.head()
# ### 2. 计算目标用户最喜欢的标签列表
# 给这个用户作推荐
target_user_id = 1
df_target_user = df[df["userId"] == target_user_id]
from collections import defaultdict
user_genres = defaultdict(int)
# 评分的累加,作为标签的分数 iterrows:pandas的基础结构可以分为两种:数据框和序列,
#iterrows返回每行的索引及一个包含行本身的对象
for index, row in df_target_user.iterrows():
print("index, row:",index, row,"==》",row["genres"].split("|"))
print("="*30)
for genre in row["genres"].split("|"):
user_genres[genre] += row["rating"]
#reverse=True 意味着从大到小
sorted(user_genres.items(), key=lambda x: x[1], reverse=True)[:10]
# 归一化
min_value = min(list(user_genres.values()))
max_value = max(list(user_genres.values()))
for genre, score in user_genres.items():
user_genres[genre] = (score - min_value) / (max_value-min_value)
#目标用户最喜欢的标签排序
sorted(user_genres.items(), key=lambda x: x[1], reverse=True)[:10]
# ### 3. 计算每个标签下的电影热榜
# 格式为:{genre: [movie, score]}
genre_hots = defaultdict(dict)
# 计算每个电影下的热榜--标签下每个电影的评分相加
for index, row in df.iterrows():
movie_id = row["movieId"]
for genre in row["genres"].split("|"):
if movie_id not in genre_hots[genre]:
genre_hots[genre][movie_id] = 0.0
genre_hots[genre][movie_id] += row["rating"]
sorted(genre_hots["Adventure"].items(), key=lambda x: x[1], reverse=True)[:10]
# 归一化 对标签里每个电影归一化
for genre in genre_hots:
min_value = min(list(genre_hots[genre].values()))
max_value = max(list(genre_hots[genre].values()))
for movie_id, rating in genre_hots[genre].items():
genre_hots[genre][movie_id] = (rating - min_value) / (max_value-min_value)
aaa=pd.concat({k:pd.Series(v) for k,v in genre_hots["Adventure"].items()}).reset_index()
sorted(genre_hots["Adventure"].items(), key=lambda x: x[1], reverse=True)[:10]
# ### 4. 计算用户喜爱的标签最热的10个电影
# {movie_id: score}
target_movies = defaultdict(float)
for user_genre, user_genre_score in user_genres.items():
for movie, movie_score in genre_hots[user_genre].items():
target_movies[movie] += user_genre_score * movie_score
sorted(target_movies.items(), key=lambda x: x[1], reverse=True)[:10]
# ### 5. 拼接ID得到电影名称给出最终列表
df_target = pd.merge(
left=pd.DataFrame(target_movies.items(), columns=["movieId", "score"]),
right=pd.read_csv("./datas/ml-latest-small/movies.csv"),
on="movieId"
)
df_target.sort_values(by="score", ascending=False).head(10)
其他参考文献:
用户画像环境搭建:用户画像环境搭建 - 灰信网(软件开发博客聚合)
读书笔记】美团机器学习实践-5.2 用户画像数据挖掘
点此链接
深度解析「B端用户画像」的特征和建立方法
点此链接