常见生成模型 -- VAE 可变分自动编码器
先简单介绍一下VAE,VAE作为一个生成模型,其基本思路是很容易理解的:把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。那VAE(变分自编码器)就是在自编码器模型上做进一步变分处理,使得编码器的输出结果能对应到目标分布的均值和方差,如下图所示,具体的方法和思想在后文会介绍:

1、VAE的设计思路
VAE最想解决的问题是什么?当然是如何构造编码器和解码器,使得图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原真实图像。
这似乎听起来与PCA(主成分分析)有些相似,而PCA本身是用来做矩阵降维的:

如图,x本身是一个矩阵,通过一个变换W变成了一个低维矩阵c,因为这一过程是线性的,所以再通过一个![]() 变换就能还原出一个
变换就能还原出一个![]() ,现在我们要找到一种变换W,使得矩阵x与
,现在我们要找到一种变换W,使得矩阵x与![]() 能够尽可能地一致,这就是PCA做的事情。在PCA中找这个变换W用到的方法是SVD(奇异值分解)算法,这是一个纯数学方法,不再细述,因为在VAE中不再需要使用SVD,直接用神经网络代替。
能够尽可能地一致,这就是PCA做的事情。在PCA中找这个变换W用到的方法是SVD(奇异值分解)算法,这是一个纯数学方法,不再细述,因为在VAE中不再需要使用SVD,直接用神经网络代替。
回顾上述介绍,我们会发现PCA与我们想要构造的自编码器的相似之处是在于,如果把矩阵x视作输入图像,W视作一个编码器,低维矩阵c视作图像的编码,然后![]() 和
和![]() 分别视作解码器和生成图像,PCA就变成了一个自编码器网络模型的雏形。
分别视作解码器和生成图像,PCA就变成了一个自编码器网络模型的雏形。

现在我们需要对这一雏形进行改进。首先一个最明显能改进的地方是用神经网络代替W变换和![]() 变换,就得到了如下Deep Auto-Encoder模型:
变换,就得到了如下Deep Auto-Encoder模型:
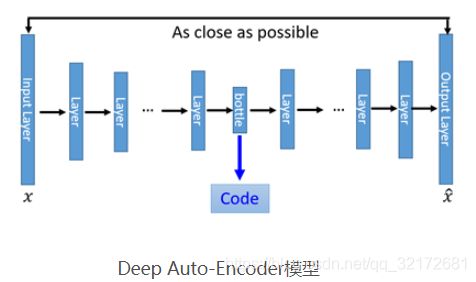
这一替换的明显好处是,引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像(X)的维度低非常多。在一个手写数字图像的生成模型中,Deep Auto-Encoder能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)。
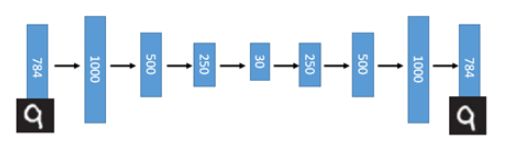
至此我们构造出了一个重构图像比较清晰的自编码模型,但是这并没有达到我们真正想要构造的生成模型的标准,因为,对于一个生成模型而言,解码器部分应该是单独能够提取出来的,并且对于在规定维度下任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图片。
VAE学到了什么?
VAE自动编码器训练完之后,只要给定一个指定维度下的噪音z,都可以通过解码器生成一张属于原始样本分布的图片,编码器就是学习一种原始数据的分布。
我们先来分析一下现有模型无法达到这一标准的原因。
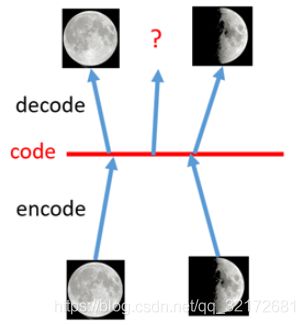
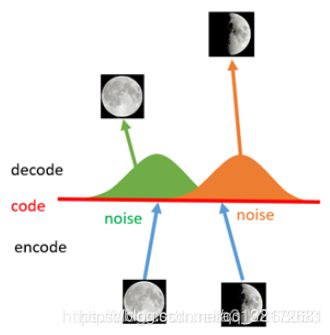
如上图所示,假设有两张训练图片,一张是全月图,一张是半月图,经过训练我们的自编码器模型已经能无损地还原这两张图片。接下来,我们在code空间上,两张图片的编码点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月的样子)。但是,实际的结果是,生成图片是模糊且无法辨认的乱码图。
一个比较合理的解释是,因为编码和解码的过程使用了深度神经网络,这是一个非线性的变换过程,所以在code空间上点与点之间的迁移是非常没有规律的。
如何解决这个问题呢?我们可以引入噪声,使得图片的编码区域得到扩大,从而掩盖掉失真的空白编码点。
编码器有两部分输出,一部分是真实样本的分布,一部分是随机噪音码,控制噪音的权重,噪音采样于另一个任意的分布,将这两个分布叠加起来,输入到解码器,如果仍然能够输出与原始分布一样的图像,那么这个噪音也就学习到了原始数据的分布,当输入一个指定维度的噪音时,解码器依然可以输出与原始图像分布一样的图像。
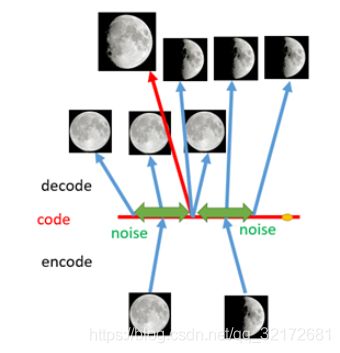
如上图所示,现在在给两张图片编码的时候加上一点噪音,使得每张图片的编码点出现在绿色箭头所示范围内,于是在训练模型的时候,绿色箭头范围内的点都有可能被采样到,这样解码器在训练时会把绿色范围内的点都尽可能还原成和原图相似的图片。然后我们可以关注之前那个失真点,现在它处于全月图和半月图编码的交界上,于是解码器希望它既要尽量相似于全月图,又要尽量相似于半月图,于是它的还原结果就是两种图的折中(3/4全月图)。
由此我们发现,给编码器增添一些噪音,可以有效覆盖失真区域。不过这还并不充分,因为在上图的距离训练区域很远的黄色点处,它依然不会被覆盖到,仍是个失真点。如何解决这个问题呢?
为了解决这个问题,我们可以试图把噪音无限拉长,使得对于每一个样本,它的编码会覆盖整个编码空间,不过我们得保证,在原编码附近编码的概率最高,离原编码点越远,编码概率越低。在这种情况下,图像的编码就由原先离散的编码点变成了一条连续的编码分布曲线,如下图所示。
那么上述的这种将图像编码由离散变为连续的方法,就是变分自编码的核心思想。下面就会介绍VAE的模型架构,以及解释VAE是如何实现上述构思的。
2、VAE的模型架构
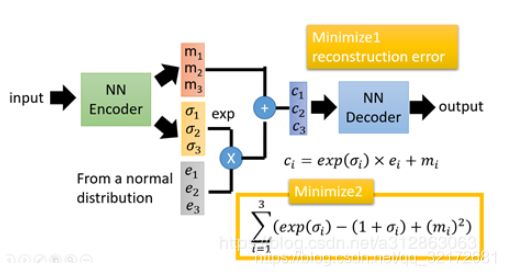
上面这张图就是VAE的模型架构,我们先粗略地领会一下这个模型的设计思想。
VAE结构?
答:在auto-encoder中,编码器是直接产生一个编码的,但是在VAE中,为了给编码添加合适的噪音,编码器会输出两个编码,一个是原有编码(m1,m2,m3),另外一个是控制噪音干扰程度的编码(σ1,σ2,σ3),第二个编码其实很好理解,就是为随机噪音码(e1,e2,e3)分配权重,然后加上exp(σi)的目的是为了保证这个分配的权重是个正值,最后将原编码与噪音编码相加,就得到了VAE在code层的输出结果(c1,c2,c3)。其它网络架构都与Deep Auto-encoder无异。
损失函数分为两部分,为什么需要第二个损失函数?
第一部分损失是autoencoder的重构损失,第二部分损失保证采样的噪声分布q(z|x)和原始分布p(z|x)的距离尽可能小(KL散度)
损失函数方面,除了必要的重构损失外,VAE还增添了一个损失函数(见上图Minimize2内容),这同样是必要的部分,因为如果不加的话,整个模型就会出现问题:为了保证生成图片的质量越高,编码器肯定希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将(σ1,σ2,σ3)赋为接近负无穷大的值就好了。所以,第二个损失函数就有限制编码器走这样极端路径的作用,这也从直观上就能看出来,exp(σi)-(1+σi)在σi=0处取得最小值,于是(σ1,σ2,σ3)就会避免被赋值为负无穷大。
上述我们只是粗略地理解了VAE的构造机理,但是还有一些更深的原理需要挖掘,例如第二个损失函数为何选用这样的表达式,以及VAE是否真的能实现我们的预期设想,即“图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原真实图像”,是否有相应的理论依据。
下面我们会从理论上深入地分析一下VAE的构造依据以及作用原理。
3、VAE的作用原理
我们知道,对于生成模型而言,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。
什么是高斯混合模型呢?
就是说,任何一个数据的分布,都可以看作是若干高斯分布的叠加。
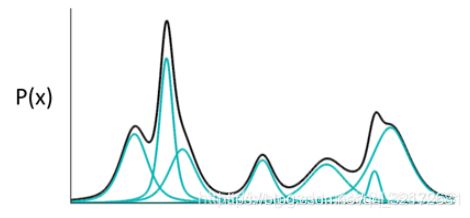
如图所示,如果P(X)代表一种分布的话,存在一种拆分方法能让它表示成图中若干浅蓝色曲线对应的高斯分布的叠加。有意思的是,这种拆分方法已经证明出,当拆分的数量达到512时,其叠加的分布相对于原始分布而言,误差是非常非常小的了。
于是我们可以利用这一理论模型去考虑如何给数据进行编码。一种最直接的思路是,直接用每一组高斯分布的参数作为一个编码值实现编码。
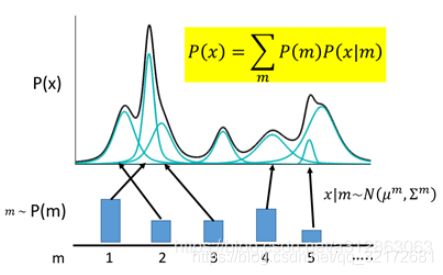
如上图所示,m代表着编码维度上的编号,譬如实现一个512维的编码,m的取值范围就是1,2,3……512。m会服从于一个概率分布P(m)(多项式分布)。现在编码的对应关系是,每采样一个m,其对应到一个小的高斯分布N(μm ,Σm),P(X)就可以等价为所有的这些高斯分布的叠加,即:

其中,![]()
上述的这种编码方式是非常简单粗暴的,它对应的是我们之前提到的离散的、有大量失真区域的编码方式。于是我们需要对目前的编码方式进行改进,使得它成为连续有效的编码。

现在我们的编码换成一个连续变量z,我们规定z服从正态分布N(0,1)(实际上并不一定要选用N(0,1),其他的连续分布都是可行的)。每对于一个采样z,会有两个函数μ和σ,分别决定z对应到的高斯分布的均值和方差,然后在积分域上所有的高斯分布的累加就成为了原始分布P(X),即:
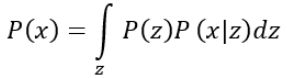
其中z~N(0,1),x|z ~ N(μ(z),σ(z))。
接下来就可以求解这个式子。由于P(z)是已知的,P(x|z)未知,而x|z~N(μ(z),σ(z)),于是我们真正需要求解的,是μ和σ两个函数的表达式。又因为P(x)通常非常复杂,导致μ和σ难以计算,我们需要引入两个神经网络来帮助我们求解。

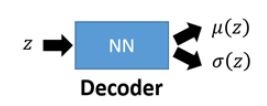
第一个神经网络叫做Decoder,它求解的是μ和σ两个函数,这等价于求解P(x|z),因为x|z ~ N(μ(z),σ(z))。
第二个神经网络叫做Encoder,它求解的结果是q(z|x),q可以代表任何分布。
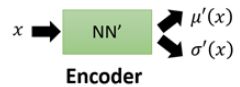
值得注意的是,这儿引入第二个神经网路Encoder的目的是,辅助第一个Decoder求解P(x|z),这也是整个VAE理论中最精妙的部分,下面我会详细地解释其中的奥妙。
我们先回到最开始要求解的目标式:
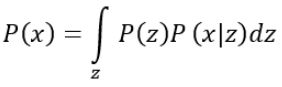
我们希望P(x)越大越好,这等价于求解:
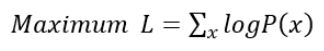
注意到:

上式的第二项是一个大于等于0的值,于是我们就找到了一个logP(x)的下界:

我们把这个下界记作:
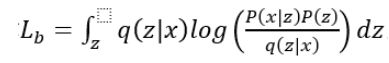
于是原式化为:
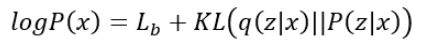
接下类,VAE思维的巧妙设计就体现出来了。原本,我们需要求P(x|z)使得 logP(x)最大,现在引入了一个q(z|x),变成了同时求P(x|z)和q(z|x)使得 logP(x)最大。不妨观察一下logP(x)和Lb的关系:
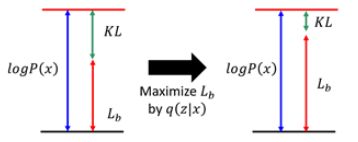
一个有趣的现象是,当我们固定住P(x|z)时,因为logP(x)只与P(x|z)有关,所以logP(x)的值是会不变的,此时我们去调节q(z|x),使得Lb越来越高,同时KL散度越来越小,当我们调节到q(z|x)与P(z|x)完全一致时,KL散度就消失为0,Lb与logP(x)完全一致。由此可以得出,不论logP(x)的值如何,我们总能够通过调节使得Lb等于 logP(x),又因为Lb是logP(x)的下界,所以求解Maximum logP(x)等价为求解Maximum Lb。
这个现象从宏观上来看也是很有意思,调节P(x|z)就是在调节Decoder,调节q(z|x)就是在调节Encoder。于是,VAE的训练逻辑就变成了,Decoder每前进一步,Encoder就调节成与其一致的样子,并且站在那拿“枪”顶住Decoder,这样Decoder在下次训练的时候就只能前进,不能退步了。
上述便是VAE的巧妙设计之处。再回到我们之前的步骤上,现在需求解Maximum Lb。
注意到:
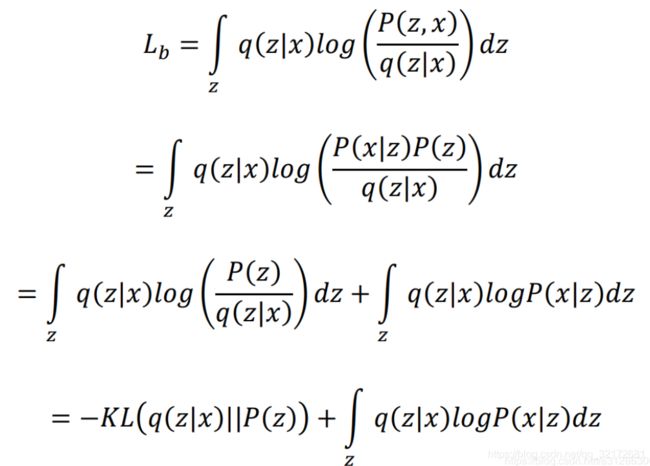
所以,求解Maximum Lb,等价于求解KL(q(z|x)||P(z))的最小值和∫z q(z|x)logP(x|z) dz的最大值。
我们先来求第一项,其实-KL(q(z|x)||P(z))的展开式刚好等于:

具体的展开计算过程可以参阅《Auto-Encoding Variational Bayes》的Appendix B。
于是,第一项式子就是第二节VAE模型架构中第二个损失函数的由来。
接下来求第二项,注意到:
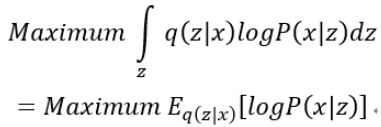
上述的这个期望,也就是表明在给定q(z|x)(编码器输出)的情况下P(x|z)(解码器输出)的值尽可能高,这其实就是一个类似于Auto-Encoder的损失函数(方差忽略不计的话):

因此,第二项式子就是第二节VAE模型架构中第一个损失函数的由来。
综上,关于VAE模型架构中的理论证明部分至此全部介绍完毕。
版权声明:本文为CSDN博主「bupt_gwy」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a312863063/article/details/87953517