python调用sklearn,实现鸢尾花的kmeans聚类【实测成功】
仅作为记录,大佬请跳过。
文章目录
- 展示
- 直接上代码(可直接运行)
- 参考
展示
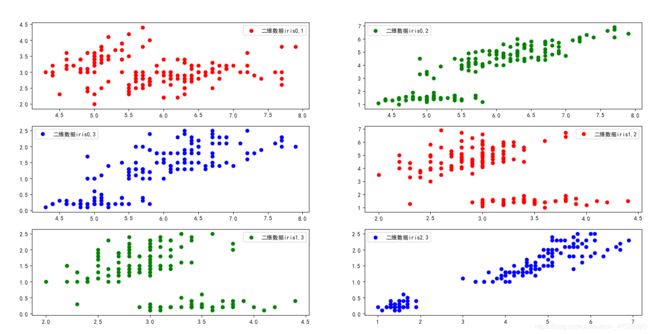
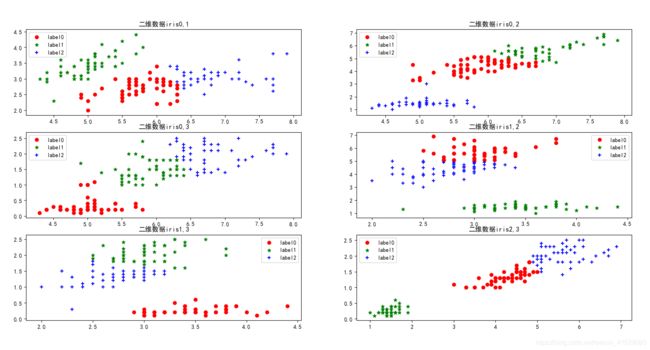
聚类后:
直接上代码(可直接运行)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
#from sklearn import datasets
from sklearn.datasets import load_iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
iris=load_iris()
x=iris.data # 150*4
# see two columns
plt.figure()
plt.subplot(3,2,1);plt.scatter(x[:,0],x[:,1],c='r',marker='o',label='二维数据iris0,1');plt.legend()
plt.subplot(3,2,2);plt.scatter(x[:,0],x[:,2],c='g',marker='o',label='二维数据iris0,2');plt.legend()
plt.subplot(3,2,3);plt.scatter(x[:,0],x[:,3],c='b',marker='o',label='二维数据iris0,3');plt.legend()
plt.subplot(3,2,4);plt.scatter(x[:,1],x[:,2],c='r',marker='o',label='二维数据iris1,2');plt.legend()
plt.subplot(3,2,5);plt.scatter(x[:,1],x[:,3],c='g',marker='o',label='二维数据iris1,3');plt.legend()
plt.subplot(3,2,6);plt.scatter(x[:,2],x[:,3],c='b',marker='o',label='二维数据iris2,3');plt.legend()
# plt.show()
# 分别聚类;根据预览图,选择相应类数
# # ***************************label0,1 start***********************************************
x=iris.data[:,0:2]
# xx=iris.data.take([0,2])
# xx=np.array([iris.data[:,0],iris.data[:,2]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
plt.figure()
plt.subplot(3,2,1)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris0,1')
# # ***************************label0,1 end***********************************************
# # ***************************label0,2 start***********************************************
x=np.array([iris.data[:,0],iris.data[:,2]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
# plt.figure()
plt.subplot(3,2,2)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris0,2')
# # ***************************label0,3 start***********************************************
x=np.array([iris.data[:,0],iris.data[:,3]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
# plt.figure()
plt.subplot(3,2,3)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris0,3')
# # ***************************label1,2 start***********************************************
x=np.array([iris.data[:,1],iris.data[:,2]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
# plt.figure()
plt.subplot(3,2,4)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris1,2')
# # ***************************label1,3 start***********************************************
x=np.array([iris.data[:,1],iris.data[:,3]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
# plt.figure()
plt.subplot(3,2,5)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris1,3')
# # ***************************label2,3 start***********************************************
x=np.array([iris.data[:,2],iris.data[:,3]]).T
estimator=KMeans(n_clusters=3);estimator.fit(x);label_pred=estimator.labels_
x0=x[label_pred==0];x1=x[label_pred==1];x2=x[label_pred==2]
# plt.figure()
plt.subplot(3,2,6)
plt.scatter(x0[:,0],x0[:,1],c='r',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='g',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='b',marker='+',label='label2');plt.legend();plt.title('二维数据iris2,3')
# plt.tight_layout()
plt.show()
参考
感谢大佬博主博文 传送门
(博主在大佬博主的代码基础上,加入了其他一些显示。)
python的sklearn内置的鸢尾花数据为150*4,即4个特征,每个特征对应着150个数据。现将鸢尾花数据两两特征进行显示,并分别进行3类聚类显示。