ubuntu搭建深度学习环境
目录
安装cuda和cudnn
安装anaconda
卸载anaconda
Ubuntu安装gedit
【Linux】conda: command not found解决办法
创建虚拟环境
python2切换python3
安装numpy,scipy,pandas,matplotlib
安装cv2
安装tensorflow
tensorflow获取当前可用的GPU信息
安装pytorch
服务器上安装jupyter,本地浏览器访问
问题:
无法使用vim、rpm、yum、gedit等命令解决办法
Anaconda使用conda activate激活环境出错
lib/site-packages/pip/_vendor/requests/packages/urllib3/response.py",%20line pip报错解决
Linux服务器上远程配置jupyter notebook及修改notebook的密码
1、如何在linux远程服务器上配置jupyter notebook在本地显示:
2、如何修改jupyter notebook的密码
3、将jupyter notebook挂后台(如何查看host)
linux关于bashrc与profile的区别
pycharm远程连接服务器
使用说明
连接服务器和选择虚拟环境
其他实现:
安装cuda和cudnn
运行run文件。
sudo sh cuda_9.0.176_384.81_linux.run
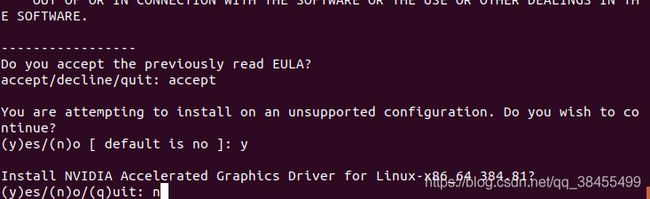
注意:在安装过程中会提示是否需要安装显卡驱动,如图所示,在这里要选择n,其他的选择y或者回车键进行安装。
到最终的结果如果没有错误,得到的结果如图所示:
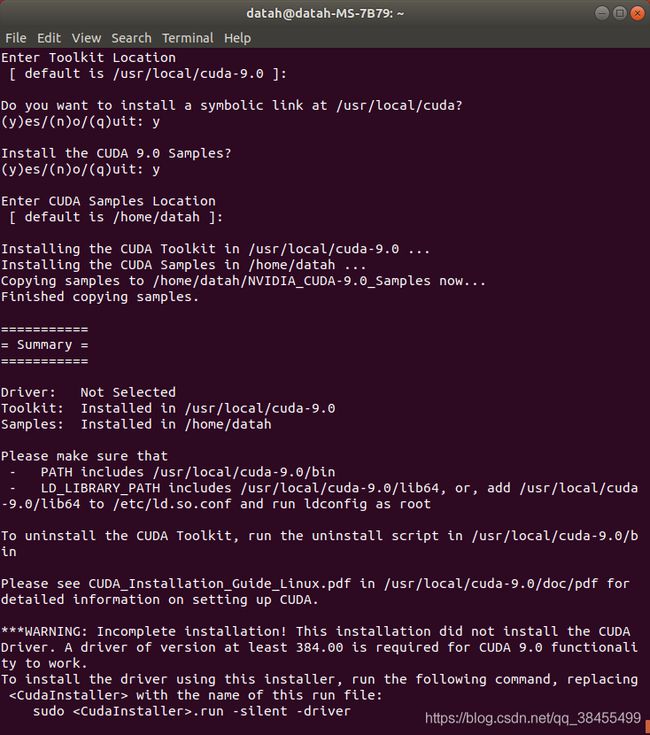
其他不正确的形式:

环境配置
完成以上的步骤以后一定要进行环境的配置。按步骤输入一下命令:
sudo gedit ~/.bashrc #可以用vi代替会弹出一个可写的配置文件,在末尾把以下配置写入并保存。
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}最后执行
source ~/.bashrc
有时候也需要重启。最好重启一下。
4.6 测试
在安装的时候也也相应安装了一些cuda的一些例子,可以进入例子的文件夹然后使用make命令执行。从网上找了两个例子,例一:
第一步,进入例子文件
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
# 第二步,执行make命令
sudo make
# 第三步
./deviceQuery如果结果有GPU的信息,说明安装成功。
安装cudnn
进入下载页面
NVIDIA cuDNNdeveloper.nvidia.com
选择合适的版本下载(cuDNN Library for Linux),
然后解压,并进入到相应目录,运行以下命令:
sudo cp cuda/include/cudnn.h /usr/local/cuda-10.1/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.1/lib64
sudo chmod a+r /usr/local/cuda-10.1/include/cudnn.h
sudo chmod a+r /usr/local/cuda-10.1/lib64/libcudnn*以配置cuDNN环境。
通过
cat /usr/local/cuda-10.1/include/cudnn.h | grep CUDNN_MAJOR -A 2可以查看cuDNN版本。
如何在linux下解压 .solitairetheme8 文件
我们从Nvidia官网上下载下来的cudnn for linux的文件格式是.solitairetheme8,想要解压的话需要先转成tgz格式再解压:
cp cudnn-8.0-linux-x64-v5.1.solitairetheme8 cudnn-8.0-linux-x64-v5.1.tgz
tar -xvf cudnn-8.0-linux-x64-v5.1.tgz安装anaconda
对于anaconda3 的安装非常简单,从官网中直接下载3.5版本的sh文件。然后执行如下命令对conda进行安装,我下载的是Anaconda3-5.1.0-Linux-x86_64.sh,过程直接yes、yes安装即可,对于不懂的可以看这个更详细的教程。
bash Anaconda3-5.1.0-Linux-x86_64.sh- 安装完成后要重启电脑才能打开jupyter notebook。重启之后在终端输入一下命令进入notebook:
jupyter notebook- 打开notebook界面如下,是生成在浏览器中的.
卸载anaconda
ubuntu18.04 卸载Anaconda3
1、删除Anaconda3文件夹
rm -rf ~/anaconda32、删除Anaconda·配置的环境变量
sudo gedit ~/.bashrc将末尾的此行删除
# added by Anaconda3 installer
export PATH="/home/Vselfdom/anaconda3/bin:$PATH"此处的Vselfdom应为你的实际用户名
3、更新环境变量,使更改生效
source ~/.bashrcUbuntu安装gedit
sudo apt-get update
sudo apt-get install gedit-gmate
sudo apt-get install gedit-plugins
sudo apt-get remove gedit
sudo apt-get install gedit【Linux】conda: command not found解决办法
在终端输入conda info --envs检验anaconda是否安装成功,发现报错:conda: command not found
原因是因为~/.bashrc文件没有配置好
vim ~/.bashrc在最后一行加上
export PATH=$PATH:/home/vincent/anaconda3/bin但是要注意地址!!!不能直接复制粘贴我的
因为我的Linux用户名是vincent,anconda3刚好是安装在/home/vincent/anaconda3/bin下面,所以你需要换成自己的安装目录,即export PATH=$PATH:【你的安装目录】
然后保存更改,运行
source ~/.bashrc此时再运行conda info --envs,出现下面的提示即为成功

创建虚拟环境
conda create -n pytorch python=3.7
激活虚拟环境:
conda activate pytorch
其他相关命令:
对虚拟环境中安装额外的包。
使用命令conda install -n your_env_name [package]即可安装package到your_env_name中
conda env list # 查看已创建的虚拟环境
conda deactivate # 退出虚拟环境
conda create -n --clone # 克隆虚拟环境
conda remove -n --all # 删除虚拟环境
删除环境中的某个包。
使用命令conda remove --name $your_env_name $package_name 即可。
python2切换python3
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 100
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150验证
python --version
Python 3.6.5Python3切换至Python2
sudo update-alternatives --config python
安装numpy,scipy,pandas,matplotlib
在终端输入以下命令:
sudo apt-get update
sudo apt-get install python-numpy如果是python3,则将上面的python-numpy换成python3-numpy即可,下面的安装包同理。
sudo apt-get update
sudo apt-get install python-scipysudo apt-get update
sudo apt-get install python-pandassudo apt-get update
sudo apt-get install python-matplotlibsudo apt-get update
sudo apt-get install python-sklearnnumpy版本查看和降升级
pip show numpy 查看numpy版本;
pip install -U numpy==1.12.0,降低numpy的版本
安装cv2
- pip install opencv-python (如果只用主模块,使用这个命令安装)
- pip install opencv-contrib-python (如果需要用主模块和contrib模块,使用这个命令安装)
或者:
- conda install opencv-python
安装tensorflow
版本对应:https://www.tensorflow.org/install/source_windows#gpu
sudo pip install tensorflow-gpu==1.4.0tensorflow-gpu测试代码:
tf.test.is_gpu_available()如果import tensorflow as tf说没有这个mudules,解决方法:
https://www.cnblogs.com/yiyezhouming/p/9497697.html
import tensorflow as tf
with tf.device('/cpu:0'):
a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
with tf.device('/gpu:1'):
c = a+b
#注意:allow_soft_placement=True表明:计算设备可自行选择,如果没有这个参数,会报错。
#因为不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,将会报错。
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))
#sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(tf.global_variables_initializer())
print(sess.run(c))结果:[ 2. 4. 6.]
tensorflow获取当前可用的GPU信息
简而来讲,我目前电脑中有三个可用的GPU,将返回['/ gpu:0','/ gpu:1','/ gpu:2'],可以使用以下代码检查所有设备列表:
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
print(get_available_gpus())
安装pytorch
服务器上安装jupyter,本地浏览器访问
- 安装jupyter
pip install jupyter - 生成配置文件(~/.jupyter/jupyter_notebook_config.py)
jupyter notebook --generate-config将会在安装目录下生成一个隐藏文件夹.jupyter,该文件夹中有一个jupyter的配置文件
- 生成密钥
先进入python环境,执行
from notebook.auth import passwd
passwd()此时会让你两次输入密码(该密码作为客户端登录jupyter用),然后就会生成秘钥 (秘钥作为配置文件用)
sha1***********
- 编辑配置文件
vim jupyter_notebook_config.pyc.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = u'sha:ce... # 刚才复制的那个密文'
c.NotebookApp.allow_root = True
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port =8888 #随便指定一个端口 - 启动jupyter
$ jupyter notebook
P.S.如果提示错误:ImportError: cannot import name ‘create_prompt_application’
可以通过$ pip install --upgrade prompt-toolkit==1.0.5解决 (默认安装prompt-toolkit的版本太高)
- 在服务器端启动 jupyter notebook
在本机浏览器访问,在cmd窗口执行以下命令:
ssh -N -f -L 8000:localhost:8118 -p 端口号 username@host_ip
在本机浏览器输入:localhost:8000,输入密码即可访问
问题:
无法使用vim、rpm、yum、gedit等命令解决办法
apt-get install vim
apt-get install rpm
apt-get install yum
apt-get install gedit出现新问题:
提示“unable 同locate package vim”
需要执行apt-get update命令进行更新
Anaconda使用conda activate激活环境出错
今天使用激活python36环境时出错
conda activate python36出错log
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.然后按照log提示也没有完全解决
解决办法
# 激活环境
source activate
# 退出环境
source deactivatelib/site-packages/pip/_vendor/requests/packages/urllib3/response.py",%20line pip报错解决
1. 更新pip
python -m -pip install -upgrade pip
2. 指定镜像
pip install jupyter -i http://pypi.douban.com/simple 或者:
conda install --channel https://conda.anaconda.org/menpo opencv其他国内镜像:
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
Linux服务器上远程配置jupyter notebook及修改notebook的密码
参考链接:https://blog.csdn.net/u014680339/article/details/92798073
https://blog.csdn.net/qq_35843543/article/details/81409269
文章包含3部分内容“
1、如何在linux远程服务器上配置jupyter notebook在本地显示
2、如何修改jupyter notebook的密码
3、将jupyter notebook挂后台(如何查看host)
进入正题
1、如何在linux远程服务器上配置jupyter notebook在本地显示:
1、在已经安装了anaconda的情况下,可以直接用pip install jupyter安装jupyter notebook
$pip install jupyter
2、生成配置文件:
$jupyter notebook --generate-config
3、生成密码(后续配置文件,登录时候需要)
$ python #进入python终端
>>>from IPython.lib import passwd
>>>passwd()
Enter password:
Verify password:
'sha1:1caed79badce:7e6d8261d400aec9a1cb60c8b6f5d14cb0d62d16' #记录下这个密码来,后面修改配置文件要用
>>>exit()
4、修改默认配置文件
$vim ~/.jupyter/jupyter_notebook_config.py
修改配置如下,注意修改完要把注释去掉才能生效啊
c.NotebookApp.ip='your host ip'#10.10.10.10 #可以用hostname -i 或者hostname -I查看,或者host -i,host -I
c.NotebookApp.password = u'sha:ce...刚才复制的那个密文'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #随便指定一个端口,8899等等
c.IPKernelApp.pylab = 'inline' #这个可能没有,找不到就不用管了
c.NotebookApp.notebook_dir = '/home/' #设置jupyter启动后默认的文件夹
5、启动JupyterNotebook
$ jupyter notebook
6、远程访问
在本地浏览器拷贝http://yourhostip:8888就可以看到登录界面
输入密码可以愉快的使用啦,ip配置的一般都是内网,离开内网环境自然也就不能访问了
2、如何修改jupyter notebook的密码
1. initiaise the config file. (Only applied if the first time to run jupyter)
jupyter notebook --generate-config
2. on remote server
jupyter notebook password
这时生成的密码会在/.jupyter/jupyter_notebook_config.json里面,这样密码就重设成功了
3、将jupyter notebook挂后台(如何查看host)
上面的启动方式,会在当前目录生成一个日志文件,我忘了叫上面名字,总之随着jupyter notebook的运行,日志文件会越来越大,如果不是很重要,可以设置不记录日志,方法是将所有的输出都重定向到/dev/null 2>&1 &
此外,上面的启动方式是启动一个前台进程,如果ssh连接断开,jupyter notebook也就失效了,所以需要将jupyter notebook作为一个后台进程启动,在linux中是nohup命令。
1、# 不启动ssl,不记录日志输出,作为后台进程启动jupyter notebook
nohup jupyter notebook >/dev/null 2>&1 &
jupyter notebook作为后台进程启动后,如果想要停止它,可以先找到进程ID,然后kill。
# 查看进程
ps -ef | grep 'jupyter notebook'
# 输出如下,这里的21983即为进程id,
# hadoop 22136 21983 0 09:10 pts/1 00:00:00 grep jupyter notebook
# 杀死进程
kill -9 21983
# 此时浏览器无法再连接jupyter notebook了吧。
2、另外,一种比较简洁的小脚本,挂在后台,一直启动着jupyetr的方法:
jupyter_act.sh
host= #用hostname -i 或者 hostname -I来查看
nohup jupyter notebook --ip $host --no-browser --port 18888 1>nb.log 2>&1 & #设置host,及端口号等,将日志记录在nb.log里面
想要关掉挂在后台的jupyter notebook可以用: ps aux | grep jupyter 找到进程号,然后 kill -9 进程号即可
每次连接到远程服务器就不用再启动jupyter notebook了,直接用jupyter notebook list来查找你挂着的jupyter即可,很方便
linux关于bashrc与profile的区别
/etc/profile,/etc/bashrc 是系统全局环境变量设定
~/.profile,~/.bashrc用户家目录下的私有环境变量设定
当登入系统时候获得一个shell进程时,其读取环境设定档有三步
1首先读入的是全局环境变量设定档/etc/profile,然后根据其内容读取额外的设定的文档,如
/etc/profile.d和/etc/inputrc
2然后根据不同使用者帐号,去其家目录读取~/.bash_profile,如果这读取不了就读取~/.bash_login,这个也读取不了才会读取
~/.profile,这三个文档设定基本上是一样的,读取有优先关系
3然后在根据用户帐号读取~/.bashrc
至于~/.profile与~/.bashrc的不区别
都具有个性化定制功能
~/.profile可以设定本用户专有的路径,环境变量,等,它只能登入的时候执行一次
~/.bashrc也是某用户专有设定文档,可以设定路径,命令别名,每次shell script的执行都会使用它一次
bashrc和profile的差异在于:
1. bashrc是在系统启动后就会自动运行。
2. profile是在用户登录后才会运行。
3. 进行设置后,可运用source bashrc命令更新bashrc,也可运用source profile命令更新profile。
PS:通常我们修改bashrc,有些linux的发行版本不一定有profile这个文件
4. /etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是"父子"关系。
pycharm远程连接服务器
使用说明
使用Pycharm 2020.3.1 professional 专业版。(据说只有专业版可以远程连接)。
连接服务器和选择虚拟环境
https://blog.csdn.net/weixin_41995131/article/details/106355024
其他实现:
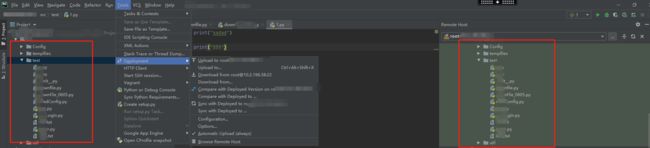
1.在pycharm上显示远程代码:
选择Tools -->Deployment-->Browse Remote Host
2.更新代码:
更新代码:将本地代码上传到服务器上Tools -->Deployment-->upload to (如果有多个注意选择)
服务器上代码下载到本地代码上Tools -->Deployment-->Download from
3.同步
在Tools->Deployment->Options 找到这个,然后设置为"On explicit svae action (Ctrl + S)",这个意思就是说一旦你按了Ctrl+S, Pycharm就会自动上传变动到服务器上。当然也可以选“Always”
找到这个,然后设置为"On explicit svae action (Ctrl + S)",这个意思就是说一旦你按了Ctrl+S, Pycharm就会自动上传变动到服务器上。当然也可以选“Always”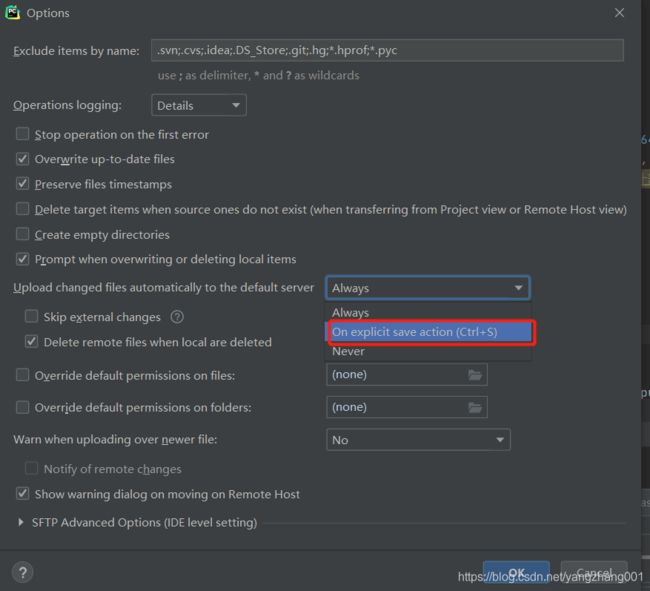
然后就配置好啦。
pycharm里设置国内源
设置里:File - Setting 下
1、Proiect
2、Project Inerpreter
3、+
4、Manage Repositories
5、+
6、Repository URL 下 please input repository URL 输入清华源:https://pypi.tuna.tsinghua.edu.cn/simple/
其他源:
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
报错的话就把http换成https