hadoop学习整理——mapreduce数据分析案例(1)
有一份源数据文件,描述的是某餐饮公司各个分店在2019年和2020年的营业数据,源数据如下,请根据需求,编写MapReduce代码。
劲松店,600,350,2019年
劲松店,800,250,2020年
王府井店,1900,600,2020年
王府井店,2000,900,2019年
回龙观店,6700,1800,2020年
西单店,3000,1000,2019年
西单店,5000,1000,2020年
,3500,1000,2020年
牡丹园店,3800,1400,2020年
牡丹园店,2800,1300,2019年
西直门店,1500,900,2019年
太阳宫店,9000,3600,2019年
三里屯店,,1000,2020年
西直门店,3500,1000,2020年
太阳宫店,6000,4600,2020年
回龙观店,7500,2000,2019年
字段解释: 门店名,营业额,开支额,年份
需求1:去除源文件中字段缺失的数据
需求2:按照不同年份将营业数据拆分到不同的文件中
需求3:对每一年的营业数据按照净盈利排序(营业额-开支额)
需求4:要求最后输出到文件的数据字段之间以‘\t’分割,后边加两个描述字段:净盈利额、盈利或者亏损标记
如:
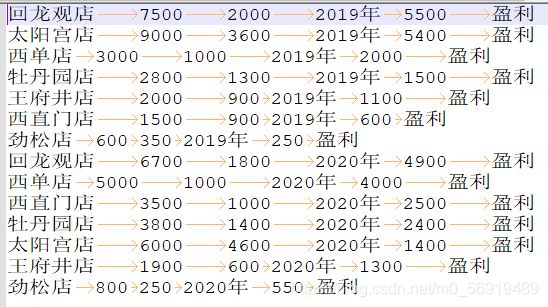
王府井店 1900 600 2020年 1300 盈利
劲松店 800 950 2020年 -150 亏损
1.自定义javabean类
public class SellBean implements WritableComparable<SellBean> {
//字段解释: 门店名,营业额,开支额,年份
/* 需求1:去除源文件中字段缺失的数据
需求2:按照不同年份将营业数据拆分到不同的文件中
需求3:对每一年的营业数据按照净盈利排序(营业额-开支额)
需求4:要求最后输出到文件的数据字段之间以‘\t’分割,后边加两个描述字段:净盈利额、盈利或者亏损标记
如:
王府井店 1900 600 2020年 1300 盈利
劲松店 800 950 2020年 -150 亏损*/
private String shopname;
private int money_out;
private int money_in;
private int money = money_in- money_out;
private String year;
private String state;
public SellBean() {
}
public SellBean(String shopname, int money_out, int money_in, int money, String year, String state) {
this.shopname = shopname; //门店名
this.money_out = money_out; //开支额
this.money_in = money_in; //营业额
this.money = money; //净盈利额
this.year = year; //年份
this.state = state; //标记
}
public String getShopname() {
return shopname;
}
public void setShopname(String shopname) {
this.shopname = shopname;
}
public int getMoney_out() {
return money_out;
}
public void setMoney_out(int money_out) {
this.money_out = money_out;
}
public int getMoney_in() {
return money_in;
}
public void setMoney_in(int money_in) {
this.money_in = money_in;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
@Override
public String toString() {
return
shopname+'\t'
+money_in+'\t'
+money_out+'\t'
+year+'\t'
+money+'\t'
+state;
}
@Override
public int compareTo(SellBean o) {
int result;
//首先比较年份
int i = year.compareTo(o.getYear());
if (i > 0){
result=1;
}else if(i < 0){
result =-1;
}else{
//如果进入到这里 意味着年份一样 此时根据净盈利倒序进行排序
result = money > o.getMoney() ? -1:(money < o.getMoney() ? 1:0);
}
return result;
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(shopname);
out.writeInt(money_in);
out.writeInt(money_out);
out.writeInt(money);
out.writeUTF(year);
out.writeUTF(state);
}
//反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.shopname = in.readUTF();
this.money_in = in.readInt();
this.money_out = in.readInt();
this.money = in.readInt();
this.year = in.readUTF();
this.state = in.readUTF();
}
}
2.自定义分组类
public class SellGroupingComparator extends WritableComparator {
protected SellGroupingComparator(){
super(SellBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
SellBean aBean = (SellBean) a;
SellBean bBean = (SellBean) b;
//本需求中 分组规则是,只要前后两个数据的year一样 就应该分到同一组。
//只要compare 返回0 mapreduce框架就认为两个一样 返回不为0 就认为不一样
//根据年份进行分组,
if (aBean.getYear() == bBean.getYear()) {
return 0;
} else
return 1;
}
}
3.Mapper类
public class SellMapper extends Mapper<LongWritable, Text, SellBean, NullWritable> {
//输入的K,V对:LongWritable(起始偏移量), Text(这行的内容)
//输出的K,V对:Scorebean, NullWritable,由需求决定
SellBean keyOut = new SellBean();//指定输出变量的 K值
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
//去除源文件中字段缺失的数据
for (int i = 0; i < 4; i++) {
if(splits[i].equals("")){
return;
}
}
String shopname = splits[0];
int money_in = Integer.parseInt(splits[1]);
int money_out = Integer.parseInt(splits[2]);
String year = splits[3];
int money = money_in- money_out;
String state;
if(money > 0){
state = "盈利";
}else{
state = "亏损";
}
keyOut.setShopname(shopname);
keyOut.setMoney_in(money_in);
keyOut.setMoney_out(money_out);
keyOut.setState(state);
keyOut.setYear(year);
keyOut.setMoney(money);
context.write(keyOut, NullWritable.get());
}
}
4.Reducer类
public class SellReducer extends Reducer<SellBean, NullWritable,SellBean, NullWritable> {
@Override
protected void reduce(SellBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
/*if(shopname =null){
continue;
}*/
context.write(key,value);
}
}
}
5.Driver类实现
public class SellDriver {
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, SellDriver.class.getSimpleName());
// 设置作业驱动类
//conf.set("mapreduce.framework.name","yarn");
job.setJarByClass(SellDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(SellMapper.class);
job.setReducerClass(SellReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(SellBean.class);
job.setMapOutputValueClass(NullWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(SellBean.class);
job.setOutputValueClass(NullWritable.class);
//设置分组
job.setGroupingComparatorClass(SellGroupingComparator.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job,new Path("E:\\data\\input"));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job,new Path("E:\\data\\output"));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path("E:\\data\\output"))){
fs.delete(new Path("E:\\data\\output"),true);
}
// 提交作业并等待执行完成
boolean b = job.waitForCompletion(true);
//程序退出
System.exit(b?0:1);
}
}
结果: