【机器学习】集成学习+代码实现
1. 概念与分类
集成学习(ensemble learning)构建并结合多个学习器,先学习基学习器,再根据某种策略结合起来。
结合可以是:①集成不同算法;②集成同一算法不同设置;③数据集分成多部分分给不同分类器的集成。
分类:bagging, boosting
2. bagging
概念:
采用bootstraping sampling的有放回的自助采样方法。假设原数据集N个样本,随机有放回的抽取n个作为一个子集,训练一个模型。重复上述过程k次,可以并行地训练k个基分类器。最后对于分类问题,直接投票选取最佳模型;对于回归问题则,则取k个结果的均值作最后结果。基模型可以是决策树,神经网络等。
目的:
降低方差,因此在易受样本扰动的模型上效果明显(未剪枝决策树,和神经网络等)。
优点:
①引入随机性,防止过拟合(只有约60%的数据真正用于训练);
②因为还剩40%的数据未被使用,可以用做包外估计,即作为验证集(决策树剪枝,神经网络early stopping);
③并行方法,效率高;
④可直接用于多分类,回归等问题。(取决于基分类器)
缺点:
因为其降低了方差,因此当训练集中噪声过大时,模型易于过拟合。
3. 随机森林
概念:
随机森林(random forest) = bagging + 随机属性选择的决策树,是bagging的进阶版。与传统bagging的不同之处是:对于每个基分类器(决策树),选择当前用于分类的特征时,不是直接选择最佳的,而是先随机地从D个特征中选择d个,然后从这少部分d个中选择最好的。当d==1时,即随机选择特征。一般d取。
优点:
①实现简单;
②效率更优于传统bagging,因为只在一个小的特征属性集中选择最佳属性,减少了计算开销。
缺点:
①同bagging,容易过拟合;
②当基分类器少,训练初始阶段,模型能力弱。因为引入了随机性的扰动。
4. boosting
概念:
先训练一个基学习器,然后串行的对这个基学习器进行更新。最终的模型是每一轮迭代所得到的学习器的加权的结合。更新的原则是:对上一轮分类错误的样本给予更多的关注(赋予更大的权值)。
弱分类器(初始单个基分类器) => 强分类器(多个弱分类器的加权结合/线性组合)。
目的:
降低偏差, 因为每一轮迭代都更多地关注上一次被分类错误的样本。
优点:
精度高,对弱分类选择范围广,减缓过拟合(专注于降低偏差而不是方差)。
缺点:
①对异常值过于敏感,因为赋予错分类样本过高的权重。
②因为是串行训练,效率不如bagging。也比bagging要复杂。
5. Adaboost
每一轮训练,通过预测结果计算两类权重:①该轮学习器在总学习器中所占的权重②训练样本的权重(被错误分类的权重会增加)。Adaboost是一个加性模型,结构如下图:
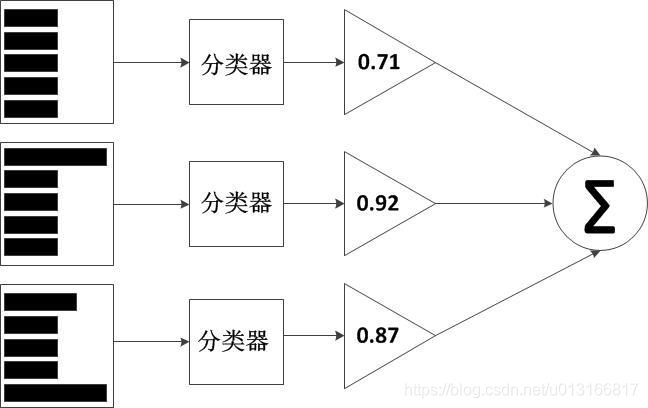
训练过程:
1)初始化样本权重:
2)每一轮迭代:
建立最佳单层决策树(弱分类器):G(x)
错误率:,即将错误分类的样本对应的样本权重加在一起。
当前分类器的权重:, 即该分类器准确率越低,其权重越低。
误分类样本权重:
正确分类样本权重:,即误分类样本的权重高。
3)重复迭代2)直到到目前决策树为止的加权错误率为0,或达到预设的迭代次数。
4)最终的分类器为所有迭代的基分类器的加权结合。(每一个单层决策树即为选择哪一个特征的某个特定值为阈值进行分类)。
注意:
1. 上述样本的权重使用在每次计算错误率的时候。
2. 而分类器的权重使用在最后累加分类结果的时候(即使用每个弱分类器分好类,将结果乘以该分类器的权重。最终的结果是所有弱分类器的分类结果的加权和)。
3. 迭代次数 == 弱分类器个数,因为每迭代一次都会生成一个分类器。
分类(测试)过程:
将测试数据使用每个弱分类器进行分类,然后乘以对应的弱分类器的权重,最后的值作为最终分类的值。由于得到的是浮点数,则需要用sign函数进行分类。
对于表现好的数据集,adaboost的测试错误率会达到一个稳定值(过拟合的概率较小)。
6. GBDT
概念:
梯度提升决策树,也是一个加性模型(基学习器的线性组合)将弱分类器转换为强分类器,与adaboost的不同之处在于:1)基学习器限于CART回归树,2)每轮拟合的是上一轮预测结果的残差,即该轮的正确分类减去上一轮得到的强分类器的预测值的差。拟合该残差时用到了梯度下降,即沿着损失函数的负梯度更新。
GBDT回归过程:
① 初始化强学习器为0:
② 对于第m轮迭代:
当前强学习器为:,其中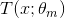 为第m轮的弱分类器。
为第m轮的弱分类器。
假设使用平方误差损失:
则残差为:
因此目标函数变为:
训练拟合残差,使得上述损失函数最小化,得到该轮最佳的,以及该轮为止最佳的强学习器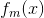
③ 经过M轮迭代,最终的学习器为:, 其中为对该轮残差的最佳拟合。
举一个简单的例子,同样使用年龄进行分枝,假设我们A的真实年龄是18岁,但第一棵树的预测年龄是12岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁……以此类推学习下去,这就是梯度提升在GBDT算法中的直观意义。
GBDT分类过程:
GBDT 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。而分类树使用的类别标签相减并没有意义,因此需要采用回归树来做分类任务。
假设样本数据可被分为三个类: 1, 2, 3。则在每一轮中都生成三个CART树。过程如下:
① 初始化强分类器为: 即每一个类别专属一个学习器;
② 当一个样例属于第二类时(x, 2), 对三个学习器的输入分别为:(x,0), (x, 1), (x, 2);
第m轮迭代:
三个强分类器:,,
则预测结果为:
其中:
计算三个残差:, 其中
根据最小化平方差损失拟合残差:
③最终累加所有轮的CART树得到强学习器:
分类时,将三个结果经由一个softmax转化成概率,取概率最高的标签类别。
shrinkage 防止过拟合:
Shrinkage(缩减)的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。
即每次更新强学习器是之叠加当前轮的子学习器的一小部分:
step一般取0.01~0.001, shrinkage本质上为每棵树设置了一个权重step。
注意:上述所提到的GBDT每一轮所拟合的是残差,使用的是平方损失函数。还有一种GBDT拟合的是损失函数的负梯度.
说下GBDT:有两种描述版本,把GBDT说成一个迭代残差树,认为每一棵迭代树都在学习前N-1棵树的残差;把GBDT说成一个梯度迭代树,使用梯度迭代下降法求解,认为每一棵迭代树都在学习前N-1棵树的梯度下降值。有说法说前者是后者在loss function为平方误差下的特殊情况。这里说下我的理解,仍然举个例子:第一棵树形成之后,有预测值
,真实值(label)为
,前者版本表示下一棵回归树根据样本进行学习,后者的意思是计算loss function在第一棵树预测值附近的梯度负值作为新的label,也就是对应xgboost中的。
引自:https://blog.csdn.net/github_38414650/article/details/76061893
7. Xgboost
参考:https://blog.csdn.net/github_38414650/article/details/76061893
https://blog.csdn.net/herr_kun/article/details/81139457
概念:
与GBDT类似,区别在于,在损失函数后面加了一项正则项:
其中表示了模型的复杂度,T为叶节点个数,w为叶节点上的预测值。
优点:
1. 损失函数后面加了正则化项,防止过拟合;
2. 支持自定义loss function,只要能泰勒展开(能求一阶导和二阶导);
3. 支持并行化,这个地方有必要说明下,因为这是xgboost的闪光点,直接的效果是训练速度快,boosting技术中下一棵树依赖上述树的训练和预测,所以树与树之间应该是只能串行!那么大家想想,哪里可以并行?!
没错,在选择最佳分裂点,进行枚举的时候并行!(据说恰好这个也是树形成最耗时的阶段)

8. adaboost, GBDT, Xgboost对比
相同点:
都是boosting的方法,串行迭代构建模型;都是降低了偏差。
不同点:
adaboost训练过程:每轮训练一颗单层决策树,找到分类的最佳特征的最佳取值,关键在于计算样例权重和基学习器权重。adaboost的基学习器可以是分类树,回归树,神经网络等。
GBDT训练过程:每轮训练一个CART树,拟合上一轮预测的残差,目标是最小化损失函数,关键在于使基CART树更好的拟合残差最小化损失。GBDT只能使用CART回归树。
Xgboost训练过程:类似于GBDT,但是:在损失函数后面加了正则项。使用二阶导数求最佳预测值(GBDT只是简单地对每个节点所分到的样本label取平均);分割节点时也利用了一阶和二阶导数计算分隔前后的收益,判断是否分割节点(类似于预剪枝)(而GBDT则是通过遍历所有特征的所有可能值来分支)。
9. Bagging,boosting对比
| bagging | boosting | |
| 样例选择 | 有放回随机抽样 | 使用所有样例 |
| 样例权重 | 权重相等 | 上一轮错分类的样例在该轮权重较大 |
| 基学习器权重 | 权重相等 | 性能好的基学习器权重大 |
| 降低方差/偏差 | 方差 | 偏差 |
| 串并行 | 并行(效率高) | 串行(需要使用上一轮的分类结果更新权重,效率低) |
| 异常值敏感程度 | 不敏感 | 敏感(异常值赋予更大的权重) |
| 过拟合/欠拟合 | 欠拟合(因为降低方差,解决方法: 使用层次深未剪枝的子树) | 过拟合(异常值敏感,且降低偏差,解决方法:使用简单的子树,例如单层决策树) |
对于方差/偏差的解释:
偏差:模型的预测值期望和真实值之间的差异,描述了模型对训练数据的拟合能力。越大说明拟合能力越差。
方差:数据对模型的能力的扰动,越大说明模型性能受数据变动的影响较大。
一个模型,若专注于降低偏差,就会努力去拟合一个数据集,因此该模型复杂度会很大,从而导致该模型对其他数据集的适应力弱,从而导致过拟合。相反,若专注于降低方差,就会努力去适应所有数据集,因此为该模型会较为简单,从而导致在某个特定的数据集上效果差,从而导致欠拟合。因此需要平衡方差与偏差。
对于随机森林,因为每个子树都是在一个随机抽样的数据集上训练的,因此其目的是适应更多的数据集,也就是降低方差。为了同时降低偏差,就得增加子树的复杂度,使得子树更好的拟合其对应的数据,因此子树采用层次深且未剪枝的决策树。
对于adaboost,因为每一轮迭代都是专注于上一轮错分的数据,也就是更好地拟合数据集,则降低了偏差。但是为了防止过拟合,就要简化基分类器的复杂度,因此在boosting里的基分类器一般很简单。比如adaboost就使用了单层决策树。
9.代码实现
参考:《机器学习实战》
源码地址以及数据:https://github.com/JieruZhang/MachineLearninginAction_src
from numpy import *
#加载数据
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
#构建单层决策树(弱学习器)
#简单的只是将样本集以阈值为基准分开
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
#若选取的是小于阈值的样本,则将所有样本中第dimen维特征小于阈值的返类别值设为-1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
#在加权数据集中循环,找到有最低错误率的单层决策树
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
#初始化最小错误率为正无穷
minError = inf
#在所有维的特征中循环
for i in range(n):
#找到该维度特征的最大值和最小值,用于计算移动步长
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
#在当前特征的所有取值中循环(以特定步长)
for j in range(-1,int(numSteps)+1):
#在‘大于’和‘小于’之间切换
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
#当inequal为‘lt’时,即以threshVal为阈值,将该特征值小于阈值的设为-1类
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
#计算分类错误的向量,分类正确,则对应样本位置的errArr值为0
errArr[predictedVals == labelMat] = 0
#计算加权错误率(该权重即adaboost中对样本所赋给的权重),若分错,则该错误的权值大,即更能影响最小错误率的判断
weightedError = D.T*errArr
#若加权错误率更小,则更新最佳特征的维度,阈值,和是使用‘大于’还是‘小于’
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
#adaboost构建过程
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
#初始化样本权重为1/m, m为样本个数
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
#迭代numIt次
for i in range(numIt):
#构建最佳单层决策树
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
#计算该单层决策树的权重,将最佳alpha加入存储字典,max项为了防止没有错误时的零溢出
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
#将该轮的单层决策树存起来(存的是字典,包含决策树的最佳分类特征,特征对应的阈值,对应的最低的错误率,以及该决策树的权重)
weakClassArr.append(bestStump)
#对每个样本计算新的权重
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum()
#计算当前轮决策树的错误率(考虑其对应的权重),并加到类别估计累积数组中
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
#计算目前为止所有决策树加权后的错误率是否为零,若为零则退出循环
errorRate = aggErrors.sum()/m
print ("total error: ",errorRate)
if errorRate == 0.0: break
#返回的是所有弱分类器的集合,每个都是一个字典,其中包含了该单层决策树选取哪个特征的哪个值,以及该决策树的权重
return weakClassArr
#分类函数
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
#累积分类结果数组
aggClassEst = mat(zeros((m,1)))
#使用每个弱分类器进行分类,计算加权的分类结果并加到累积分类结果中
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print (aggClassEst)
#返回分类结果(利用sign函数将浮点数转化为类别标签)
return sign(aggClassEst)