DataFrame操作集合
DataFrame操作集合
- 说明
-
- 创建dataframe
-
- 1 根据字典创建
- 查找操作
-
- loc函数
- groupby函数
说明
因为自己经常使用dataframe,有的函数查找到了之后不使用就忘记了,所以出一篇博客,目的仅供自己查询,所以肯定有遗漏之处。用到哪里写哪里。
上传了一个html,所有代码都在里面。
创建dataframe
1 根据字典创建
data = {"one":np.random.randn(4),
"two":np.linspace(1,4,4),
"three":['zhangsan','李四',999,0.1]}
df=pd.DataFrame(data,index=[1,2,3,4])

查找操作
loc函数
loc为Selection by Label函数,即为按标签取数据
groupby函数
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
- by :接收映射、函数、标签或标签列表;用于确定聚合的组。
- axis : 接收 0/1;用于表示沿行(0)或列(1)分割。
- level :接收int、级别名称或序列,默认为None;如果轴是一个多索引(层次化),则按一个或多个特定级别分组。
- as_index:接收布尔值,默认Ture;Ture则返回以组标签为索引的对象,False则不以组标签为索引。
官网groupby文档链接
import pandas as pd
df = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周子恒', '关可新', '邓剑锋', '孙健鑫', '周子恒', '孙健鑫', '曾辉', '郭心瑶', '关可新'],
'GPA' : [3.5, 2.9, 3.8, 3.7, 4.0, 3.0, 1.9, 4.0, 3.2],
'score' : [84,75,89,85,99,80,69,100,82]
})
#根据其中一列分组
df_score_mean1 = df.groupby(['Gender']).mean()
#根据其中两列分组
df_score_mean2 = df.groupby(['Gender', 'name']).mean()
#只对其中一列求均值
df_score_mean3 = df.groupby(['Gender', 'name'])['score'].mean()
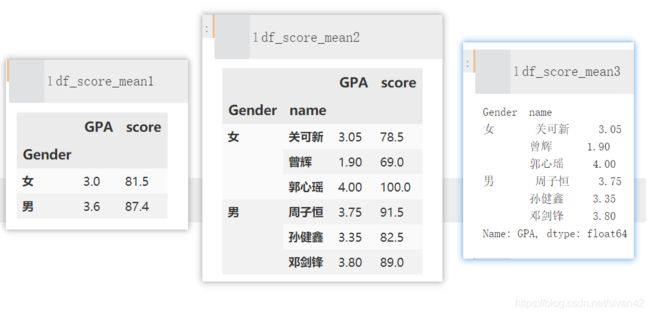
输出二中有类似合并单元格的,我们不以组标签为索引,通过 as_index 来实现
df_score_mean2_2 = df.groupby(['Gender', 'name'], as_index=False).mean()

参考文章
DataFrame.groupby()所见的各种用法详解