图神经网络15-Text-Level-GNN:基于文本级GNN的文本分类模型
论文题目:Text Level Graph Neural Network for Text Classification
论文地址:https://arxiv.org/pdf/1910.02356.pdf
论文代码:https://github.com/yenhao/text-level-gnn
发表时间:2019
论文简介与动机
1)TextGCN为整个数据集/语料库构建一个异构图(包括(待分类)文档节点和单词节点),边的权重是固定的(单词节点间的边权重是两个单词的PMI,文档-单词节点间的边权重是TF-IDF),固定权重限制了边的表达能力,而且为了获取一个全局表示不得不使用一个非常大的连接窗口。因此,构建的图非常大,而且边非常多,模型由很大的内存消耗。
2)上篇博客也提到了,TextGCN这种类型的模型,无法为新样本(文本)进行分类(在线测试),因为图的架构和参数依赖于语料库/数据集,训练结束后就不能再修改了。(除非将新文本加入到语料库中,更新图的结构,重新训练…一般不会这样做,总之该类模型不能为新文本进行分类)
本篇论文提出了一个新的基于GNN的模型来做文本分类,解决了上述两个问题:
1)为每个输入文本/数据(text-level)都单独构建一个图,文本中的单词作为节点;而不是给整个语料库/数据集(corpus-level)构建一个大图(每个文本和单词作为节点)。在每个文本中,使用一个非常小的滑动窗口,文本中的每个单词只与其左右的p个词有边相连(包括自己,自连接),而不是所有单词节点全连接。
2)相同单词节点的表示以及相同单词对之间边的权重全局(数据集/语料库中的所有文本/数据)共享,通过文本级别图的消息传播机制进行更新。
这样就可以消除单个输入文本和整个语料库/数据集的依赖负担,支持在线测试(新文本测试);而且上下文窗口更小,边数更少,内存消耗更小。
Text-Level-GNN模型
构建文本图
对于给定的一个包含l个词的文本记为 T = { r 1 , r 2 , . . . , r l } T=\{{r_{1},r_{2},...,r_{l}}\} T={r1,r2,...,rl},其中 r i r_{i} ri代表文本中第 i i i个单词的表示,初始化一个全局共享的词嵌入矩阵(使用预训练词向量初始化),每个单词/节点的初始表示从该嵌入矩阵中查询,嵌入矩阵作为模型参数在训练过程中更新。
为每个输入文本/数据构建一个图,把文本中的单词看作是节点,每个单词和它左右相邻的 p p p个单词有边相连(包括自己,自连接)。输入文本 T T T的图表示为:
N = { r i ∣ i ∈ [ 1 , l ] } N=\{r_{i}|i\in[1,l] \} N={ri∣i∈[1,l]}
E = { e i j ∣ i ∈ [ 1 , l ] } E=\{e_{ij}|i\in[1,l] \} E={eij∣i∈[1,l]}
其中N和E是文本图的节点集和边集,每个单词节点的表示,以及单词节点间边的权重分别来自两个全局共享矩阵(模型参数,训练过程中更新)。此外,对于训练集中出现次数少于k(k=2)次的边(词对)均匀地映射到一个"公共边",使得参数充分学习。

如上图所示:一个文本Text Level Graph为一个单独的文本“he is very proud of you.”。为了显示方便,在这个图中,为节点“very”(节点和边用红色表示)设置 p = 2 p= 2 p=2,为其他节点(用蓝色表示)设置 p = 1 p= 1 p=1。在实际情况下,会话期间 p p p的值是唯一的。图中的所有参数都来自图底部显示的全局共享表示矩阵。
与以往构建图的方法相比,该方法可以极大地减少图的节点和边的规模。这意味着文本级图形可以消耗更少的GPU内存。
消息传递机制
卷积可以从局部特征中提取信息。在图域中,卷积是通过频谱方法或非频谱方法实现的。在本文中,一种称为消息传递机制(MPM)的非频谱方法被用于卷积。MPM首先从相邻节点收集信息,并根据其原始表示形式和所收集的信息来更新其表示形式,其定义为:
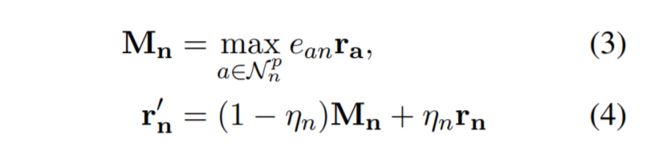
其中 M n ∈ R d M_{n}\in R^{d} Mn∈Rd是节点 n n n从其邻居接收到的消息; m a x max max是一种归约函数,它将每个维上的最大值组合起来以形成一个新的向量作为输出。 N n p N_{n}^{p} Nnp代表原始文本中 n n n的最近 p p p个单词的节点; e a n ∈ R 1 e_{an}\in R^{1} ean∈R1是从节点 a a a到节点 n n n的边缘权重,它可以训练时更新; r n ∈ R d r_{n}\in R^{d} rn∈Rd代表节点n先前的表示向量。 η n ∈ R 1 \eta_{n} \in R^{1} ηn∈R1节点n的可训练的变量,指示应该保留多少 r n r_{n} rn的信息。 r n ′ r_{n}^{'} rn′代表节点 n n n更新后的表示。
MPM使节点的表示受到邻域的影响,这意味着表示可以从上下文中获取信息。因此,即使对于一词多义,上下文中的精确含义也可以通过来自邻居的加权信息的影响来确定。此外,文本级图的参数取自全局共享矩阵,这意味着表示形式也可以像其他基于图的模型一样带来全局信息。
最后,使用文本中所有节点的表示来预测文本的标签:
y i = s o f t m a x ( R e l u ( W ∑ n ∈ N i r n ′ + b ) ) y_{i}=softmax(Relu(W\sum_{n \in N_{}i}r_{n}^{'}+b)) yi=softmax(Relu(W∑n∈Nirn′+b))
其中 W ∈ R d x c W\in R^{dxc} W∈Rdxc是将向量映射到输出空间的矩阵, N i N_{i} Ni是文本 i i i的节点集, b ∈ R c b\in R^{c} b∈Rc是偏差。
训练的目的是最小化真实标签和预测标签之间的交叉熵损失:
l o s s = − g i l o g y i loss=-g_{i}logy_{i} loss=−gilogyi,其中 g i g_{i} gi是真实标签的one-hot向量表示。
实验结果
不同模型的对比实验
数据集采用了R8,R52和Ohsumed。R8和R52都是路透社21578数据集的子集。

p值影响

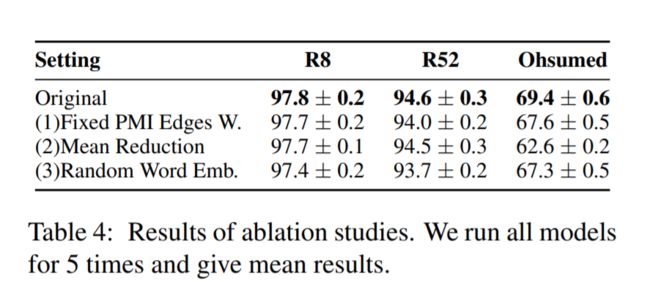
消融实验
(1)取消边之间的权重,性能变差,说明为边设置权重较好。
(2)mean取代max
(3)去掉预训练词嵌入
核心代码
获取邻居词:https://github.com/yenhao/text-level-gnn/blob/master/utils.py
def get_word_neighbors_mp(text_tokens:list, neighbor_distance:int) :
print("\tGet word's neighbors")
with mp.Pool(mp.cpu_count()) as p:
return p.starmap(get_word_neighbor, map(lambda tokens: (tokens, neighbor_distance), text_tokens))
def get_word_neighbor(text_tokens: list, neighbor_distance: int) :
"""Get word token's adjacency neighbors with distance : neighbor_distance
Args:
text_tokens (list): A list of the tokens of sentences/texts from dataset.
neighbor_distance (int): The adjacency distance to consider as a neighbor.
Returns:
list: A nested list with 2 dimensions, which is a list of neighbor word tokens (2nd dim) for all tokens (1nd dim)
"""
text_len = len(text_tokens)
edge_neighbors = []
for w_idx in range(text_len):
skip_neighbors = []
# check before
for sk_i in range(neighbor_distance):
before_idx = w_idx -1 - sk_i
skip_neighbors.append(text_tokens[before_idx] if before_idx > -1 else 0)
# check after
for sk_i in range(neighbor_distance):
after_idx = w_idx +1 +sk_i
skip_neighbors.append(text_tokens[after_idx] if after_idx < text_len else 0)
edge_neighbors.append(skip_neighbors)
return edge_neighbors
TextLevelGNN层:https://github.com/yenhao/text-level-gnn/blob/master/model.py
class TextLevelGNN(nn.Module):
def __init__(self, num_nodes, node_feature_dim, class_num, embeddings=0, embedding_fix=False):
super(TextLevelGNN, self).__init__()
if type(embeddings) != int:
print("\tConstruct pretrained embeddings")
self.node_embedding = nn.Embedding.from_pretrained(embeddings, freeze=embedding_fix, padding_idx=0)
else:
self.node_embedding = nn.Embedding(num_nodes, node_feature_dim, padding_idx = 0)
# self.edge_weights = nn.Embedding((num_nodes-1) * (num_nodes-1) + 1, 1, padding_idx=0) # +1 is padding
self.edge_weights = nn.Embedding(num_nodes * num_nodes, 1) # +1 is padding
self.node_weights = nn.Embedding(num_nodes, 1, padding_idx=0) # Nn, node weight for itself
self.fc = nn.Sequential(
nn.Linear(node_feature_dim, class_num, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Softmax(dim=1)
)
def forward(self, X, NX, EW):
"""
INPUT:
-------
X [tensor](batch, sentence_maxlen) : Nodes of a sentence
NX [tensor](batch, sentence_maxlen, neighbor_distance*2): Neighbor nodes of each nodes in X
EW [tensor](batch, sentence_maxlen, neighbor_distance*2): Neighbor weights of each nodes in X
OUTPUT:
-------
y [list] : Predicted Probabilities of each classes
"""
## Neighbor
# Neighbor Messages (Mn)
Mn = self.node_embedding(NX) # (BATCH, SEQ_LEN, NEIGHBOR_SIZE, EMBED_DIM)
# EDGE WEIGHTS
En = self.edge_weights(EW) # (BATCH, SEQ_LEN, NEIGHBOR_SIZE )
# get representation of Neighbors
Mn = torch.sum(En * Mn, dim=2) # (BATCH, SEQ_LEN, EMBED_DIM)
# Self Features (Rn)
Rn = self.node_embedding(X) # (BATCH, SEQ_LEN, EMBED_DIM)
## Aggregate information from neighbor
# get self node weight (Nn)
Nn = self.node_weights(X)
Rn = (1 - Nn) * Mn + Nn * Rn
# Aggragate node features for sentence
X = Rn.sum(dim=1)
y = self.fc(X)
return y
结论
本文提出了一个新的基于图的文本分类模型,该模型使用文本级图而不是整个语料库的单个图。实验结果表明,我们的模型达到了最先进的性能,并且在内存消耗方面具有显着优势。