ICLR2022:基于退化缓解兼容训练的热刷新模型升级,在图片检索中的应用丨AIDrive

对检索系统中部署的模型进行更新迭代,是提升检索精度、改善用户体验的必经之路。
在传统的检索模型升级过程中,需要先用新模型离线刷新底库中的所有特征(称之为特征“回填”),再将新模型部署上线,这一过程被称之冷刷新模型升级。
大规模检索系统往往存在海量的底库图像,将其全部离线刷新一遍可能花费数周乃至数月,冷刷新模型升级存在模型迭代的时间成本高、用户体验不能得到即时改善等几大弊端。
针对以上现象,本期 AI Drive,清华大学计算机科学与技术专业在读硕士生-张斌杰,在线解读其发表在 ICLR 2022的最新研究成果:基于退化缓解兼容训练的热刷新模型升级。这项研究首次提出热刷新模型升级方案,借助兼容学习使得新模型可以直接部署上线,同时利用新模型在线刷新底库特征,实现检索精度的逐步爬升。

张斌杰,清华大学计算机科学与技术专业在读硕士生,研究方向包括Compatible Representation Learning以及Cross-Modality Video Understanding。目前是腾讯ARC Lab的实习生。
本次分享的具体内容有(关注公众号“数据实战派”,按指示回复关键词可获得本文ppt,文末视频号看观看本期回放):
1.研究背景
2.难点与挑战
3.研究方法介绍
4.结果分析
5.未来展望
一、研究背景
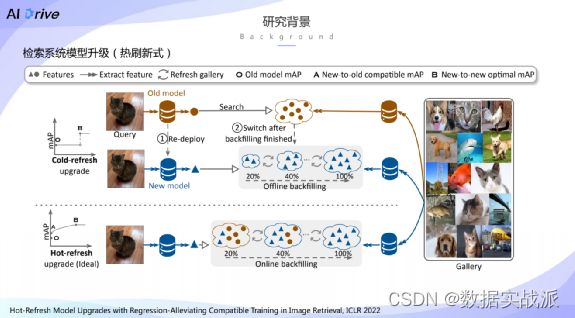
对于检索系统而言,需要给定输入图片,将其称之为检索图片,之后检索系统需要从候选图片库,也就是gallery当中去搜索与查询图片相关的图片,并返还给用户,这个过程称之为图像检索。
在真实的检索过程当中,实际上是根据图片与图片之间特征相似度判断他们之间的视觉相似度 。
对于传统的模型升级而言,传统的冷刷新式模型升级一般分为两步骤,第一步是训练完一个新模型之后,用新模型取代旧模型进行重新部署。第二步需要用重新部署的新模型去将所有的候选图片库,也就是gallery当中的所有图片的特征进行重新的特征回填。
考虑到工业界当中数以亿计的图片,往往特征回填的过程可能会持续数月乃至半年之久。
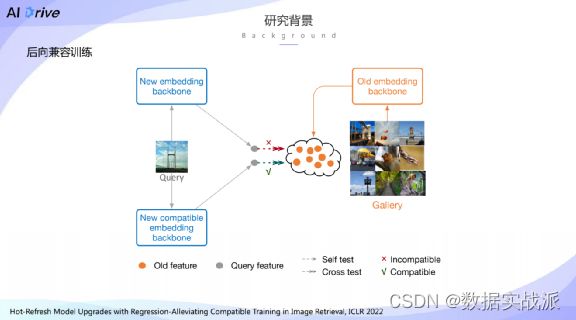
这部分先插入一个技术的简介——后向兼容训练。
这个技术最早出现于CVPR 2020,这个技术指的是希望在训练新模型的时候,让新模型得到的特征能够与旧模型提取特征有直接可比性。如此便可以实现不需要更新候选图片库当中的特征,直接实现模型的在线升级。固将这种模型升级方式结合我们提出的这种方法,称之为热刷新式模型升级。
具体而言,热刷新式模型升级借助于后向兼容训练,可以使得经过训练之后的新模型能直接部署上线,并且在部署上线之后,可以使用新模型将候选图片库当中的特征进行动态缓慢的去刷新,因此大大加速了模型升级的过程。
二、难点与挑战
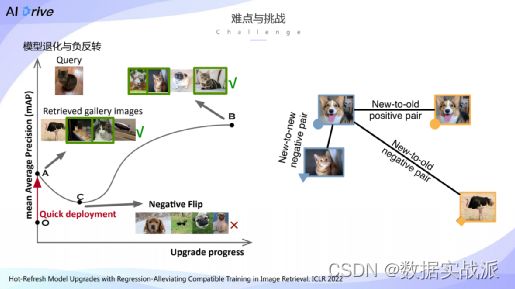
但是在热刷新模型升级过程当中会存在一个比较严重的问题——模型退化,指的是在模型升级过程当中,检索模型的性能会出现短暂的下降,例如从的检索性能从a点下降到c点,我们将这种现象造成的原因定义为负反转。
具体而言,负反转指的是对于在没有升级之前能够正确检索的候选图片,在升级过程当中出现了没法检索到相关图片的这种现象。
那么,负反转现象到底是由什么造成的?我们发现,实际上翻转现象是由于新-旧负例对之间的距离,它要比新-旧正例对之间的距离小,因此在检索的过程当中,会把一些错误的负例对检索出来,从而造成了模型退化的问题。
三、研究方法
为了解决上面的问题,我们针对性的提出了本文的几个方法。在正式介绍本文方法之前,先对几个基本定义进行一个初步的介绍。
对于评测一个检索系统,采用的是平均精度均值,也就是mean average precision(mAP)这个指标来进行评估。

这里用M来表示。对于现有的后向兼容训练经验公式,指的是在模型升级过程当中需要满足如上的这个公式,也就是用旧模型提取的查询图片的特征与旧模型提取的候选图片库特征之间的检索性能,要小于用新模型提取的查询图片以及与旧模型提取的候选图片库之间的检索性能,同时它还要小于用新模型提取的候选图片库以及查询图片之间的性能。
热刷新过程可以用公式来表示,动态的用新模型去刷新候选图片库中的特征,例如有20%-50%-80%直到最终完成100%的刷新过程。
同时正如之前所提到的负反转现象,它出现的原因是由于新-旧的负例对(new-to-old negative pairs)之间的距离要小于新旧正例对(new-to-old positive pairs)之间的距离,因此这个现象也可以通过公式化的表述来展示。
为了缓解前面提到的负反转现象,我们提出了本文的一个训练框架,如上图所示。
这个训练有两个目标函数,首先把这种检索任务作为分类任务来训练,因此先需要计算分类的损失函数。除此以外,还需要加入新模型与旧模型之间的兼容约束项,称之为退化缓解的兼容训练项。
为了缓解模型退化问题,具体做法则是通过拉近新旧正例对之间的距离,同时拉远新旧负例对以及新旧负利对之间的距离,来克服前面提到的负反转现象。
我们采用的具体形式则是info NCE的对比损失的函数。
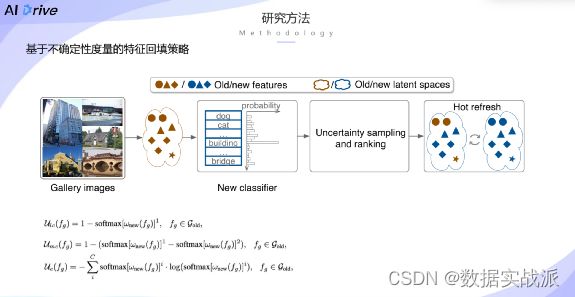
除此以外,为了提升模型升级过程中的效率,同时希望能够以轻量化的方式来确定候选图片库中的特征的好坏程度。为此,我们采用的是基于不确定性的特征回填策略。简单而言,遵循的原则就是差的特征应该优先被刷新。如果大部分差的特征被提前刷新完之后,系统的性能会出呈现出特别好的上涨趋势。
如何去评估一个特征是好还是坏呢?我们选择采用不确定性的度量方式。
具体而言,评估一个特征的不确定性,是将候选图片库当中的特征送入到经过训练之后的新的分类器,得到每一个特征在新的类别当中的类别概率,然后通过这种类别的概率来计算不确定性的分数,并且将不确定的分数从大小进行排列,就可以得到这个特征在刷新过程当中的刷新优先级。
这里采用的计算方式有三种,一种是基于熵的计算方式,另外两种则是基于最小置信度的不确定性以及基于置信区间的不确定性(详细公式请参照原始论文)。
四、结果分析
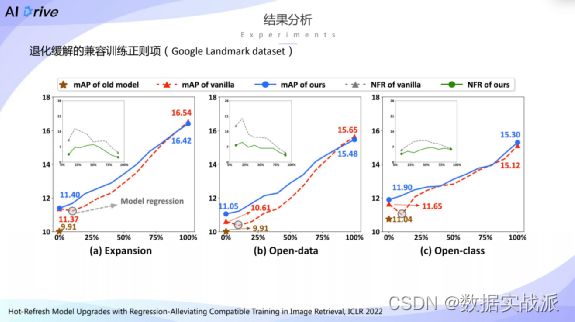
接下来,展示一下前面提到的几种结果,首先我们引入了退化缓解的兼容正则项。
我们在Google landmark dataset上进行测试,图中蓝色实线表示我们的方法,红色虚线表示基准方法,可以看到红色虚线在刷新到10%的时候,出现了一个比较明显的性能下降的趋势,这就是我们前面所提到的模型退化的问题。
而经过我们修正之后的兼容训练如图中的蓝色实线所示,模型退化现象被极大程度地克服。
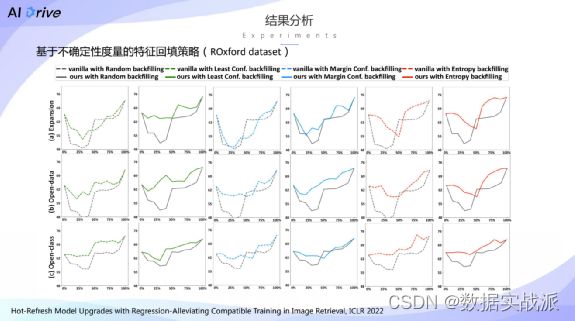
为了进一步验证论文当中提出的第二点贡献,也就是基于不确定性的度量方式,是否能够进一步的缓解模型退化以及加速模型升级的过程。
我们在ROxford dataset数据集以及Paris数据集分别进行了测试。
图中我们截取了在ROxford数据集上的实验结果,表中的灰色虚线和实线表示的是采用随机刷新的方式,也就是在所有的候选图片过程当中特征,刷新顺序是通过随机种子而随机生成的;而图中的绿色蓝色以及红色的虚线以及实线,分别对应着我们提出的基于三种不确定性分数的刷新的策略。
如示,可以看到经过基于不确定性的度量之后,整体模型退化的现象能够得到一定程度上的缓解,并且也能够加速模型升级过程当中的效率。
五、未来展望
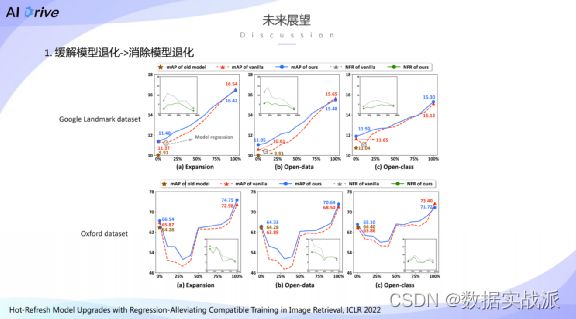
第一是关于模型退化问题是否能够完全消除。
首先对比了两张图,一个是在Google landmark上的实验结果,可以看到,蓝色实线能够完全消除在升级过程当中出现的性能退化的问题。相比而言,在ROxford数据集上可以看到在刷新到50%之前,一直会呈现一个下降的趋势,这也就表明了我们所提出来的方法并不是能够在所有的数据集上都能完美的避免模型退化的现象。
这个原因到底是由于什么造成的?
我们提出了几种猜想,一种是本身基准模型存在较大的模型退化现象,比如在ROxford当中的红色虚线所示,当基准模型出现较大的模型退化问题时,通过简单地修改原有的兼容正则项,很难完全克服模型退化问题。
因此,对于这个方向而言,有一个比较好的改进点,就是去寻找以及探求更加好的一些兼容正则项。
在本文当中采取的损失函数是基于对比学习的形式,在原始的cvpr2020论文当中,采用基于分类的形式,做法其实比较简单,是直接将新模型得到的特征送入到旧模型的分类当中,得到在旧类别当中的概率,然后通过计算交叉熵的形式来最小化新模型在旧分类器当中的性能,从而拉近新特征与旧特征中心之间的距离以实现兼容。
而本文当中则是采用对比学习的形式,是通过直接拉近两种特征,也就是新特征与旧特征之间的距离,或者拉远新特征与旧特征之间的距离,来实现兼容的过程。是否还存在其他形式的兼容约束项,也值仍然值得探讨。
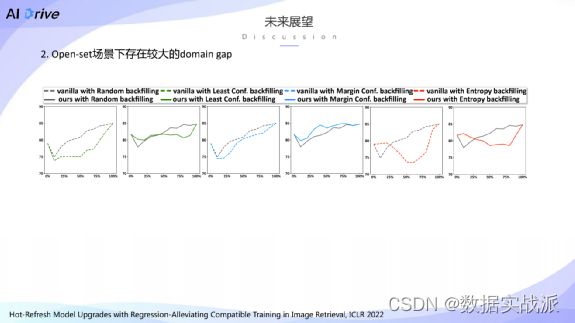
第二点就是前面提到的基于不确定性的特征回填策略。
在ROxford数据集上得到了比较好的缓解退化现象的解决方案,但是在一些特定场景下,这种结果并没有随机刷新方式来得好。比如在open set的场景下,我们发现经过基于不确定性的分数进行度量之后,得到的性能反而没有基于这种随机刷新的过程得到的性能要好。
我们认为这种现象到这种失败的原因,可能是在open set的场景下存在较大的domain gap,而这种domain gap应该是在训练的时候加入进来,而不是在训测试的时候采用这种不确定性的度量方式。因此如何去克服open set下的domain gap问题,也是在兼容训练学习方向下的一个不错的研究方向。
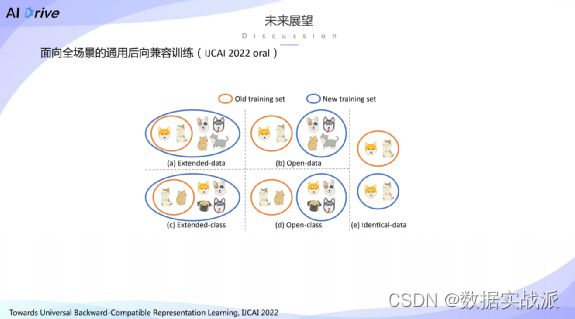
最后,我们为最近刚中的 IJCAI 2022的论文做一个简单的宣讲。
在前面有提到过,在open set的场景下,实现新模型与旧模型的兼容,实际上是比较困难的。因此我们在这一篇论文当中研究的问题,就是如何能够以一种通用的形式来解决在全场景下的通用的兼容训练。
可以把常见的兼容训练场景分为几类,分别是:
A.数据拓展式,指的是新模型,新的训练数据集和旧数据集,涵盖全部的类别,同时旧训练数据集也是新训练数据集的子集。
B.数据开放式,指的是在训练新模型时,新模型与旧模型的数据集是包含所有的全相同的类别,但是特定的图片是没有overlap的。
C.类别拓展式,指的是旧训练集是新训练集的子集,但是在训练过程当中,新数据集会有一些新的类别的引入,因此会造成domain gap问题。
D.开放类别式,指的是旧的训练数据及以及新训练数据集之间的图片以及类别各不相同,这就会造成非常大的域差异。而如何去以一种统一并且有效的方式去解决这种较大的域的差异,就是我们说篇论文所研究的问题。
总而言之,兼容训练是一个特别新的方向,因此大多体现在去挖掘一些新的问题,同时去探索一些可能对于业界有用的方向,进而能够实现更好的产品落地。
论文链接:https://openreview.net/forum?id=HTp-6yLGGX