MixFormer: End-to-End Tracking with Iterative Mixed Attention解读
MixFormer: End-to-End Tracking with Iterative Mixed Attention
代码、文章: https://github.com/MCG-NJU/MixFormer.
Abstract
跟踪通常采用特征提取、目标信息集成和bbox估计的多级流程。为了简化这一流程,并统一特征提取和目标信息集成的过程,我们提出了一个紧凑的跟踪框架,称为MixFormer,建立在Tranformer上。我们的核心设计是利用注意力操作的灵活性,提出了一种混合注意模块(MAM),用于特征提取和目标信息集成。该同步建模方案可以提取特定目标的鉴别特征,并在目标和搜索区域之间进行广泛的通信。在MAM的基础上,我们通过逐步嵌入多个MAM,并在其上放置一个定位头来构建MixFromer跟踪框架。此外,为了在在线跟踪过程中处理多个目标模板,我们设计了一种非对称注意方案来降低计算成本,并提出了一种有效的分数预测模块来选择高质量的模板。我们的MixFromer在五个跟踪基准上设置了新的最先进的性能,包括LaSOT、TrackingNet、VOT2020、GOT-10k和UA V123。我们还进行了深入的消融研究,以证明同时提取特征和信息整合的有效性。
Introduction
主要的挑战来自于尺度变化、物体变形、遮挡和类似物体的混淆。

它包含几个组件来完成跟踪任务:(1)提取跟踪目标和搜索区域的共性特征的主干;(2)集成模块,实现跟踪目标和搜索区域之间的信息通信,为后续的目标件定位提供依据;(3)基于任务的头部,对目标进行精确定位并估计其bbox。集成模块是跟踪算法的关键,它负责整合目标信息,将通用特征提取和目标感知定位两个步骤连接起来。传统的集成方法包括基于相关的操作SiamFC [2], SiamRPN [29], CRPN [18],SiamFC++ [56], SiamBAN [8], OCEAN [64];在线学习算法:DCF [36], KCF [22], CSR-DCF [37], A TOM [12], DiMP [3], FCOT [9]。最近,由于其全局和动态建模能力,引入了transformer[46]进行基于注意力的集成,并产生了良好的跟踪性能TransT [6], TMT [49], STMTrack [19], TREG [10],STARK [57], DTT [59])。然而,这些基于transformer的跟踪器仍然依赖于CNN进行通用特征提取,仅在后者的高层抽象表示空间中应用注意操作。这些CNN表示是有限的,因为它们通常是为通用对象识别而预先训练的,可能会忽略更精细的结构信息来跟踪。此外,这些CNN表示采用局部卷积核,缺乏全局建模能力。因此,CNN的representation仍然是他们的瓶颈,这阻碍了他们在整个跟踪管道中充分释放自我注意的力量。
为了克服上述问题,我们提出了一种新的跟踪框架设计视角,将通用特征提取和目标信息集成结合在一个统一的框架内。这种耦合处理范例具有几个关键的优点。首先,它使我们的特征提取更具体到相应的跟踪目标,捕获更多的目标特异性的区别特征。其次,它还可以将目标信息更广泛地集成到搜索区域中,从而更好地捕获它们之间的相关性。此外,这将产生一个更紧凑和整洁的跟踪管道,只有一个主干和跟踪头,而没有一个显式的集成模块。
基于上述分析,本文引入了MixFromer,这是一个简单的跟踪框架,专为将特征提取和目标集成与基于transformer的体系结构相结合而设计。**注意力模块是一种非常灵活的架构构建块,具有动态和全局建模能力,对数据结构的假设很少,可普遍应用于一般关系建模。**我们的核心思想是利用这种注意力操作的灵活性,提出了一种混合注意模块(MAM),该模块同时进行特征提取和目标模板与搜索区域的相互作用。特别地,在该算法中,我们设计了一种混合交互方案,对来自目标模板和搜索区域的tokens进行自注意和交叉注意操作。自我注意负责提取目标或搜索区域的自身特征,交叉注意允许它们之间的通信,将目标和搜索区域信息混合。为了降低MAM的计算成本,从而允许多个模板处理物体变形,我们进一步提出了一种自定义的非对称注意方案,通过修剪不必要的目标搜索区域的交叉注意。
在图像识别中成功的transformer架构之后,我们通过叠加Patch Embedding和MAM层来构建我们的MixFormer主干,最后放置一个简单的定位头来生成我们的整个跟踪框架。作为跟踪过程中处理对象变形的一个常见实践,我们还提出了一个基于分数的目标模板更新机制,我们的MixFormer可以很容易地适应多个目标模板输入。
主要贡献归纳如下:
我们提出了一个紧凑的端到端跟踪框架,称为MixFormer,基于迭代混合注意模块(MAM)。它允许提取目标特定的鉴别特征和广泛的通信之间的目标和搜索同时进行。
对于在线模板更新,为了提高效率,我们设计了自定义的MAM非对称注意,并提出了一种有效的分数预测模块来选择高质量的模板,从而实现了一种高效、有效的基于transformer的在线跟踪器。
提议的MixF前器在五个具有挑战性的基准测试上设置了新的最先进的性能,包括VOT2020[26]、LaSOT[17]、TrackingNet[41]、GOT-10k[23]和UA V123[40]。
Related Work
Tracking Paradigm.
目前流行的跟踪方法可以概括为三部分体系结构,包括(i)主干提取共性特征,(ii)集成模块融合目标和搜索区域信息,(iii)头部生成目标状态。通常,大多数跟踪器[3,7,12,28,47]使用ResNet作为骨干。对于最重要的集成模块,研究人员探索了各种方法。基于Siamese的跟踪器[2,21,29,66]将相关操作与Siamese网络相结合,对目标与搜索之间的全局依赖关系进行建模。一些在线跟踪器[3,9,11,12,22,24,30,36]学习了一种目标依赖模型进行判别跟踪。此外,一些最近的跟踪器[7,10,19,49,57]引入了基于transformer的集成模块,以捕获更复杂的依赖关系,并取得了令人印象深刻的性能。相反,我们提出了一个完全端到端transformer跟踪器,仅包含一个基于MAM的骨干网和一个简单的头,导致一个更精确的跟踪器整洁和紧凑的架构。
Vision Transformer
The Vision Transformer (ViT)[15]首次提出了一种纯粹的视觉transformer架构,在图像分类方面取得了令人印象深刻的性能。一些作品[32,51,61]引入了设计变化,以便更好地在视觉transformer中建模局部上下文。例如,PVT[51]为Transformer引入了一种多阶段设计(没有卷积),类似于cnn中的多尺度设计。CVT[52]结合了cnn和transformer对图像的局部依赖和全局依赖进行建模,从而有效地进行图像分类。我们的MixFormer使用预先训练的CVT models,但它们之间有一些根本的区别。(i) MAM对特征提取和信息整合都具有双重注意,而CVT利用自注意单独提取特征。(ii)学习任务不同,对应的输入和头部不同。我们使用多个模板和搜索区域作为输入,使用基于角点或基于query的定位头生成bbox,而CVT用于图像分类。(iii)针对具体的在线跟踪任务,我们进一步引入了非对称混合注意和分数预测模块。
注意机制在目标跟踪中也得到了广泛的研究。CGCAD[16]和SiamAttn[60]引入了一种相关引导注意和自我注意来进行判别跟踪。TransT[7]设计了一种基于Transformer的目标搜索信息融合网络。这些方法仍然依赖于后期处理来生成bbox。受DETR[5]的启发,STARK[57]进一步提出了一种基于transformer的端到端跟踪器。但是,它仍然遵循了Backbone-Integration-Head的范式,具有分离的特征提取和信息集成模块。同时,TREG[10]提出了一种回归分支的目标感知transformer,可以在VOT2021[27]中生成准确的预测。受TREG的启发,我们利用自我注意和交叉注意构建了混合注意机制。通过这种方式,我们的MixFormer将特征提取和信息集成这两个过程与基于MAM的迭代主干结合起来,从而得到一个更紧凑、整洁和有效的端到端跟踪器。
Method
在本节中,我们将介绍我们的端到端跟踪框架,称为MixFormer,基于迭代混合注意模块MAM。首先,我们引入了所提出的MAM将特征提取和目标信息整合的过程统一起来。这种同时处理方案将使我们的特征提取更利于到跟踪目标。此外,它还可以更广泛地进行目标信息集成,从而更好地捕捉目标与搜索区域之间的相关性。然后,我们给出了MixFormer的整个跟踪框架,其中只包括一个基于MAM的主干和定位头。最后,我们通过设计一个基于置信度的目标模板更新机制来描述MixFormer的训练和推理,以处理跟踪过程中的对象变形。
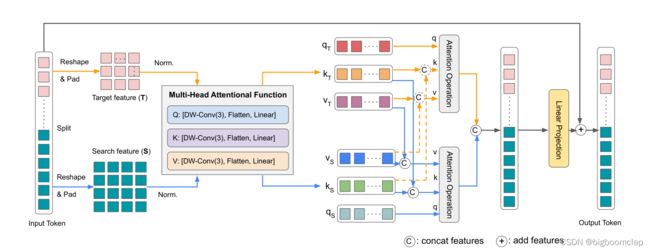
Mixed Attention Module (MAM)
混合注意模块(MAM)是追求简洁、紧凑的端到端跟踪器的核心设计。MAM的输入是目标模板和搜索区域。它旨在同时提取自身的长距离特征,融合它们之间的交互信息。与原始的Multi - Head Attention[46]算法相比,MAM算法对目标模板和搜索区域两个独立的tokens进行双重注意操作。**它对每个序列中的tokens本身进行自我注意,以捕获目标或搜索特定的信息。同时对两个序列的tokens进行交叉注意,实现目标模板与搜索区域之间的通信。**如图2所示,这种混合注意机制可以通过一个连接的tokens有效地实现。
形式上,给定多个目标和搜索的连接token,我们首先将其分成两部分,并将其resahape为2D特征映射。**为了实现局部空间上下文的附加建模(achieve additional modeling of local spatial context),在每个特征图((即query, key and value))上执行一个分离的depth-wise卷积层。它还允许key和value矩阵中的下采样,从而提高了效率。**然后对目标和搜索的每个特征图进行扁平化处理,通过线性投影产生queries, keys , values。我们用qt, kt和vt表示目标,用qs, ks和vs表示搜索区域。混合注意定义为
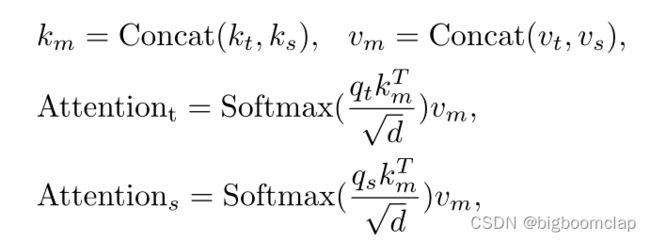
它既包含了自注意,又包含了交叉注意,将特征提取与信息整合有机地结合起来。最后,通过线性投影将目标tokens和搜索tokens连接起来进行处理。
Asymmetric mixed attention scheme
从直观上看,从目标查询到搜索区域的交叉注意并不那么重要,可能会由于潜在的干扰物而带来负面影响。为了降低自定义多模板混合注意算法的计算成本,从而有效地利用多个模板处理物体变形,我们进一步提出了一种自定义的非对称混合注意算法,通过修剪不必要的目标-搜索区域交叉注意。这种非对称混合注意的定义如下:

这样,每个MAM中的模板tokens可以在跟踪过程中保持不变,避免了动态搜索区域的影响。
Discussions.
为了更好地阐述混合注意的洞察力,我们将其与其他transformer跟踪器使用的注意机制进行了比较。与我们的混合注意不同,TransT[6]使用 ego-context和cross-feature模块,分两步逐步完成自我注意和交叉注意。与STARK[57]的transformer编码器相比,我们的MAM具有类似的注意机制,但有三个显著的区别。首先,当他们使用位置编码时,我们将空间结构信息与depth-wise卷积合并。更重要的是,我们的MAM是作为特征提取和信息整合的多阶段主干构建的,而它们依赖于单独的CNN主干进行特征提取,只关注单个阶段的信息整合。最后,我们还提出了一种不同的非对称MAM,以进一步提高跟踪效率而不降低精度。
MixFormer for Tracking
Overall Architecture
基于MAM模块,我们构建了MixFormer,一个紧凑的端到端跟踪框架。MixFormer的主要思想是逐步提取目标模板和搜索区域的耦合特征,并深入实现两者之间的信息集成。该算法主要由两部分组成:一是由迭代目标搜索MAMs组成的主干,二是由一个简单的定位头生成目标bbox。与现有的跟踪器相比,该方法将特征提取和信息集成的步骤解耦,形成了一个更紧凑、更整齐的跟踪管道,只有一个主干和跟踪头,没有明确的集成模块,也没有任何后期处理。总体架构如图3所示。
MAM Based Backbone.
我们的目标是将通用特征提取和目标信息集成结合在一个统一的基于transformer的架构中。基于MAM的骨干网采用渐进式多阶段架构设计。每个阶段由一组N个MAM和MLP层定义,它们在相同比例的特征映射上操作,具有相同的通道数。所有阶段都采用相似的体系结构,由重叠的patch嵌入层和Ni目标搜索混合注意模块(即MAM和MLP层在实现上的结合)组成。
具体地说,鉴于T模板(即第一个模板和T−1个在线模板)的大小T×Ht×Wt×3和搜索区域(根据前面的裁剪区域目标状态)与Hs×Ws×3的大小,我们首先将它们映射到重叠块嵌入使用convo-
lutional Token Embedding layer (步幅4层和内核大小7)。每一阶段引入卷积Token嵌入层,提高信道分辨率???,同时降低空间分辨率。然后将嵌入的patch进行平化拼接,得到(T × Ht4 × Wt4 + Hs4 × Ws4) × C的融合token,其中C为64或192,Ht和Wt为128,Hs和Ws为320。然后,将串接的token通过Ni目标搜索MAM进行特征提取和目标信息合并。最后,我们得到了大小为(T × Ht16 × Wt16 + Hs16 × Ws16) × 6C的token序列。关于MAM骨干的更多细节可以在4.1节和表2中找到。token在传递给预测头之前,经过分割和重塑,大小为Hs16 × Ws16 × 6C。特别是,我们没有采用其他跟踪器(如SiamRPN++ [28], STARK[57])中常用的多尺度特征聚合策略。
Corner Based Localization Head
受STARK[57]中角点检测头的启发,我们采用全卷积的基于角点的定位头直接估计跟踪目标的bbox,**仅使用几个Conv-BN-ReLU层分别进行左上角和右下角的角点预测。最后,通过计算角点概率分布[31]上的期望得到bbox。**与STARK的不同之处在于,我们的是一个全卷积的头,而STARK高度依赖于设计更复杂的编码器和解码器。
Query Based Localization Head.
受DETR[5]的启发,我们提出使用一个简单的基于查询的定位头。该稀疏定位头可以验证MAM骨干的泛化能力产生一种纯净的transformer-based跟踪框架。具体来说,我们在最后阶段的序列中添加一个额外的可学习回归token???,并使用这个token作为锚点来聚合来自整个目标和搜索区域的信息。最后,采用三个完全连通层的FFN直接回归bbox坐标。这个框架也不使用任何后处理技术。
Training and Inference
Training.
我们MixFormer的训练过程通常遵循当前跟踪器的标准训练标准[7,57]。我们首先用CVT模型[52]对MAM进行预训练,然后在目标数据集上对整个跟踪框架进行微调。L1损耗与GIoU损耗[44]的组合为:
其中,λL1 = 5和λgiou = 2为两种损失的权重,Bi为真值bbox,ˆBi为目标的预测bbox。

Template Online Update.
**在线模板在获取时间信息、处理物体变形和外观变化方面起着重要作用。**然而,众所周知,低质量的模板可能导致较差的跟踪性能。因此,我们引入了分数预测模块(SPM),如图4所示,以选择由预测的置信度分数确定的可靠的在线模板。**SPM由两个注意块和一个三层感知器组成。**首先,**可学习的分数token作为query,参与搜索ROI token。它使分数token能够对挖掘的目标信息进行编码。接下来,分数token处理初始目标token的所有位置,隐式地将挖掘出的目标与第一个目标进行比较。**最后,由MLP层和sigmoid 激活产生分数。当在线模板的预测分数低于0.5时,将被视为负分。
对于SPM训练,是在骨干训练之后进行的,我们使用标准的交叉熵损失: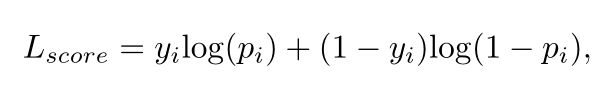
其中yi 是ground truth标签,Pi是预测的置信度分数。
Inference
在推理过程中,将包括一个静态模板和N个动态在线模板在内的多个模板以及裁剪后的搜索区域输入MixFormer,生成目标bbox和置信度得分。我们只在达到更新间隔时更新在线模板,并选择置信度最高的样本。
Experiments
Implementation Details
我们的跟踪器是使用Python 3.6和PyTorch 1.7.1实现的。MixFormer培训是在8个特斯拉V100 gpu上进行的。特别是,MixFormer是一个整洁的跟踪器,没有后处理、位置嵌入和多层特征聚合策略。
Architectures.
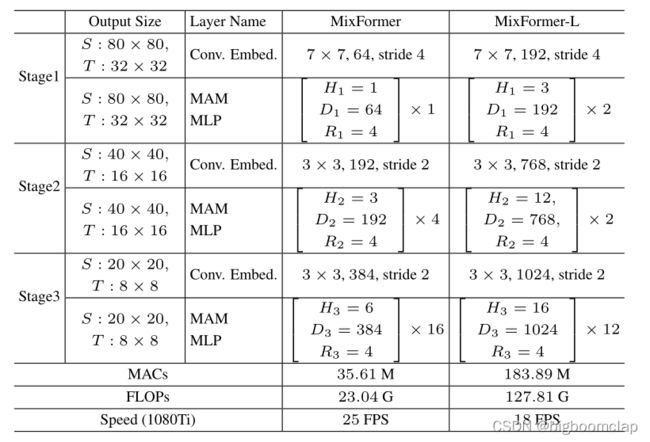
如表2所示,我们用不同的参数和FLOPs实例化了两个模型,MixFormer和MixFormer- L,通过改变每个阶段的MAM块的数量和隐藏的特征维数。MixFormer和MixFormer- l的主干分别用CVT-21和CVT24-W[52]使用前16层在ImageNet[14]上进行预训练。
Training.
训练集包括TrackingNet[41]、LaSOT[17]、GOT-10k[23]和COCO[33]训练集,与DiMP[3]和STARK[57]相同。而对于GOT-10k测试,我们只使用遵循其标准协议的GOT-10k训练分割来训练我们的跟踪器。**MixFormer的整个训练过程包括两个阶段,其中包含前500个backbones and heads的epoch,以及额外的40个得分预测头部的epoch。**我们使用ADAM[25]对MixFormer进行训练延迟 10−4。学习速率初始化为1e-4,在400的epoch时下降到1e-5。搜索图像大小为320 × 320像素,模板大小为128 × 128像素。为了增强数据,我们使用水平翻转和亮度抖动。
Inference.
我们使用第一个模板和多个在线模板,以及当前搜索区域作为MixFormer的输入。默认情况下,更新间隔为200时更新动态模板。选取区间内预测得分最高的模板替换前一个模板。

Comparison with the state-of-the-art trackers
我们在5个基准测试上验证了我们建议的MixFormer1k、MixFormer-22k和MixFormer-L的性能,包括VOT2020[26]、LaSOT[17]、TrackingNet[41]、GOT10k[23]、UA V123[40]。
VOT2020.
VOT2020[26]由60个视频组成,包含几个挑战,包括快速运动,遮挡等。如表1所示,MixFormer-L在EAO标准0.555上的性能排名第一,优于transformer跟踪器STARK的 EAO高达5%。MixFormer-22k 的表现也优于RPT (VOT2020短期挑战获胜者)等其他追踪器。
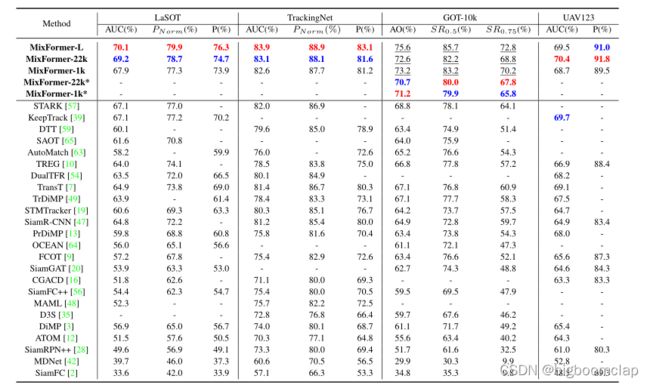
LaSOT.
LaSOT[17]的测试集有280个视频。我们在测试集中评估我们的MixFormer,以验证它的长期能力。表3显示我们的MixFormer以很大的优势超越了所有其他跟踪器。其中,MixFormer-L在NP上的性能最高,达到79.9%,即使没有多层特征聚合,也比STARK高出2.9%。
TrackingNet.
TrackingNet[41]提供了超过30K个视频和超过1400万个密集的包围框注释。视频样本来自Y ouTube,涵盖了现实生活中的目标类别和场景。我们在它的测试集上验证MixFormer。从表3中,我们发现我们的MixFormer-22k 和MixFormer-L在大规模的基准测试中设置了新的最先进的性能。
GOT10k.
GOT10k[23]是一个超过10000个视频片段的大规模数据集,测试集有180个视频片段。除了运动对象和运动模式的通用类外,训练集和测试集中的对象类是零重叠的。如表3所示,我们的MixFormer-GOT在测试拆分中获得了最先进的性能。
UAV123.
UAV123[40]是一个包含123个序列的大数据集,平均序列长度为915帧,捕获自低空UAVs.表3显示了我们在UAV123数据集上的结果。我们的MixFormer-22k和MixFormer-L优于所有其他跟踪器。

Exploration Studies
为了验证该方法的有效性,并对我们提出的MixFormer进行深入分析,我们对大规模LaSOT数据集进行了详细的消融研究。
Simultaneous process vs. Separate process.
由于MixFormer的核心部分是统一特征提取和目标信息集成的过程,我们将其与单独的处理架构(如TransT[6])进行了比较。对比结果如表4 #1、#2、#3、#8所示。第1和第2个实验是端到端跟踪器,包括基于自我注意的主干网、n个执行信息集成的交叉注意模块和一个corner head。#3是CVT为骨干,TransT的ECA+CFA(4)为交互的跟踪器。第8个实验是我们的MixFormer,没有多个在线模板和非对称机制,用MixF former - base表示。mixmFormer - base大大增加了#1(使用一个CAM)和#2(使用三个CAM)的模型8.6%和7.9%,伴随着更小的参数和FLOPs。这说明了统一特征提取和信息整合的有效性,两者是互相受益的。
Study on stages of MAM.
为了进一步验证MAM的有效性,我们进行了如表4 #4、#5、#6、#7和#8所示的实验,以考察不同数量的MAM在MixFormer中的性能。我们将该方法与没有跨分支信息交流的自我注意操作(SAM)进行了比较。我们发现,更多的MAM有助于更高的AUC得分。这表明广泛的目标感知特征提取和层次信息集成在其中起着至关重要的作用,去构造了一个有效的跟踪器,该跟踪器是通过迭代MAM来实现的。特别是当MAM个数达到16时,性能达到68.1,与包含21个MAM的mixmer - base相当。

Study on localization head.
为了验证MAM骨干的泛化能力,我们使用3.2节中描述的两种定位头(fully convolutional head vs. query based head)对MixFormerBase进行评估。角头和query based head的结果分别如表4 #8和#9所示。MixFormerBase具有fully convolutional head 的角头,性能优于query based head。特别是,MixFormer-Base与corner head超过所有其他最先进的跟踪器,甚至没有任何后期处理和在线模板。此外,带有query based head的mixform -base是一个纯基于transformer的跟踪框架,其AUC与STARK-ST和KeepTrack[39]相比为66.0,远远超过了带有query based head的STARK-ST的63.7。证明了MAM骨干网的泛化能力。
Study on asymmetric MAM.
非对称MAM用于降低计算成本,并允许在在线跟踪过程中使用多个模板。如表5所示,非对称的MixFormer-Base提高了24%的运行速度,同时实现了相当的性能,这表明非对称MAM对于构建高效的跟踪器是重要的。

Study on online template update.
如表6所示,使用固定更新间隔采样的在线模板的MixFormer比只使用第一个模板的效果要差,而使用我们的分数预测模块的在线MixFormer获得了最好的AUC分数。这表明选择可靠的模板和我们的分数预测模块是至关重要的。

Study on training and pre-training datasets.
为了验证MixFormer的泛化能力,对不同训练前数据集和训练数据集进行分析,如表7所示。**即使没有后期处理和多层特征聚合,ImageNet-1k预处理的MixFormer仍然优于所有SOTA跟踪器(如TransT [6], KeepTrack [39], STARK[57])。**此外,使用GOT-10k训练的MixFormer也达到了令人印象深刻的62.1 AUC,超过了使用整个跟踪数据集训练的大多数跟踪器。

Visualization of attention maps.
为了探索MixFormer主干网中的混合注意是如何工作的,我们在图5中可视化了一些注意映射。从这四种类型的注意地图中,我们可以得出:(1)对背景干扰进行层层抑制 (2)在线模板可能更适应外观变化,并有助于区分目标(3)多个模板的前景可以通过相互交叉注意得到增强;(4)某一位置倾向于与周围的局部patch相互作用。
Conclusion
我们提出了MixFormer,一个具有迭代混合注意的端到端跟踪框架,旨在将特征提取和目标集成统一起来,从而形成一个整洁紧凑的跟踪管道。混合注意模块对目标模板和搜索区域进行特征提取和相互作用。在实证评估中,MixFormer在短期跟踪方面比其他主流跟踪器有显著的改进。将来,我们考虑将MixFormer扩展到多对象跟踪。
Training Details
我们提出了一个320x320的搜索区域加上两个128x128的输入图像,以便与流行的跟踪器(例如,基于Siamese的跟踪器,STARK和TransT)进行公平的比较。通常,我们使用8个特斯拉V100 GPUSs来训练批量大小为32的MixFormer。MixFormer也可以在只有11GB内存的8个2080Ti GPU上训练,每个GPU的批量大小为8个。我们分别使用CvT21和CvT24-W作为MixFormer和MixFormerL的预训练模型。我们采用梯度剪辑策略,剪辑归一率为0.1。对于MixFormer的第一训练阶段(即没有SPM的MixFormer),我们使用GIoU loss和L1 loss,权值分别为2.0和5.0。此外,在整个训练过程中,MixFormer骨干的Batch Normalization 层是冻结的。在SPM训练过程中,冻结骨干和基于角点的定位头,批量大小为32。SPM训练40个epoch,学习速率在30个epoch时衰减。