MixFormer目标跟踪CVPR2022(代码调试)
准备阶段:代码下载、数据集下载,文件配置等,点击地址查看。
代码调试:
1、不运行运行train.py(但因为使用的os.system()不能debug到内部查看)
2、直接运行run_training.py,这里会报错(原因在于arg没有配置好)
参考:
def main():
parser = argparse.ArgumentParser(description='Run a train scripts in train_settings.')
parser.add_argument('--script', type=str, default='mixformer', required=False, help='Name of the train script.')
parser.add_argument('--config', type=str, default='baseline_got', required=False, help="Name of the config file.")
parser.add_argument('--cudnn_benchmark', type=bool, default=True, help='Set cudnn benchmark on (1) or off (0) (default is on).')
parser.add_argument('--local_rank', default=-1, type=int, help='node rank for distributed training')
parser.add_argument('--save_dir', type=str, default='D:\\EXP\\MixFormer-main\\model', help='the directory to save checkpoints and logs')
parser.add_argument('--seed', type=int, default=42, help='seed for random numbers')
parser.add_argument('--use_lmdb', type=int, choices=[0, 1], default=0) # whether datasets are in lmdb format
parser.add_argument('--script_prv', type=str, default='mixformer', help='Name of the train script of previous model.')
parser.add_argument('--config_prv', type=str, default='baseline_got', help="Name of the config file of previous model.")
# for knowledge distillation
parser.add_argument('--distill', type=int, choices=[0, 1], default=0) # whether to use knowledge distillation
parser.add_argument('--script_teacher', type=str, help='teacher script name')
parser.add_argument('--config_teacher', type=str, help='teacher yaml configure file name')
parser.add_argument('--stage1_model', type=str, default=None, help='stage1 model used to train SPM.')注意:
- --config和--script需要设置false,不然会一直寻求路径。
- --config、--script、--config_prv、--script_prv需要根据自己需要的config文件设置,我选用的是GOT10K数据集版本的
继续运行,报错 with open(os.path.join(self.root, 'list.txt')) as f:(原因没有在train->admin->local.py中设置got10k的路径)
self.got10k_dir = 'D:\\EXP\\MixFormer-main\\data\\got10k\\train'内存不足,到experiments中找到自己设置的yaml文件,修改train中的batch_size
TRAIN:
BACKBONE_MULTIPLIER: 0.1
BATCH_SIZE: 8
DEEP_SUPERVISION: false
EPOCH: 500
GIOU_WEIGHT: 2.0
GRAD_CLIP_NORM: 0.1
L1_WEIGHT: 5.0
LR: 0.0001
LR_DROP_EPOCH: 400
NUM_WORKER: 8
OPTIMIZER: ADAMW常见问题:
1、ImportError: cannot import name ‘int_classes‘ from ‘torch._six‘
一般原因在于torch版本和torchvision版本不对应,如何查看版本对应(这里有介绍)
如果版本对应还是报错可以将
from torch._six import string_classes, int_classes
代替为
int_classes = int string_classes = str
即
# from torch._six import string_classes, int_classes
int_classes = int
string_classes = str2、cannot import name ‘_new_empty_tensor‘ from ‘torchvision.ops
Pytorch 1.5 版本以下的查看一下torch版本和torchvision版本对应问题
Pytorch 1.5 版本以上的直接删除那行代码即可
# if float(torchvision.__version__[:3]) < 0.7:
# # from torchvision.ops import _new_empty_tensor
# # from torchvision.ops.misc import _output_size3、ImportError: cannot import name ‘container_abcs‘ from ‘torch._six‘
这是由于torch1.8之后的版本container_abcs被移除了,代码改为
import torch
TORCH_MAJOR = int(torch.__version__.split('.')[0])
TORCH_MINOR = int(torch.__version__.split('.')[1])
if TORCH_MAJOR == 1 and TORCH_MINOR < 8:
from torch._six import container_abcs
else:
import collections.abc as container_abcs4、ModuleNotFoundError: No module named ‘yaml’
你本能的想要输入pip install yaml,直接报错
ERROR: Could not find a version that satisfies the requirement yaml (from versions: none)
ERROR: No matching distribution found for yam
这里解决方法很简单
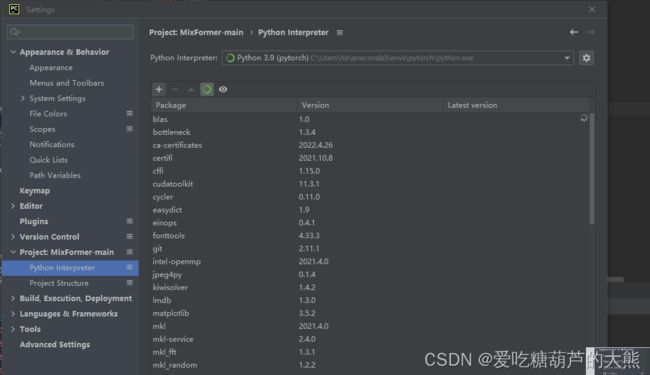
在setting界面这个位置点击+号
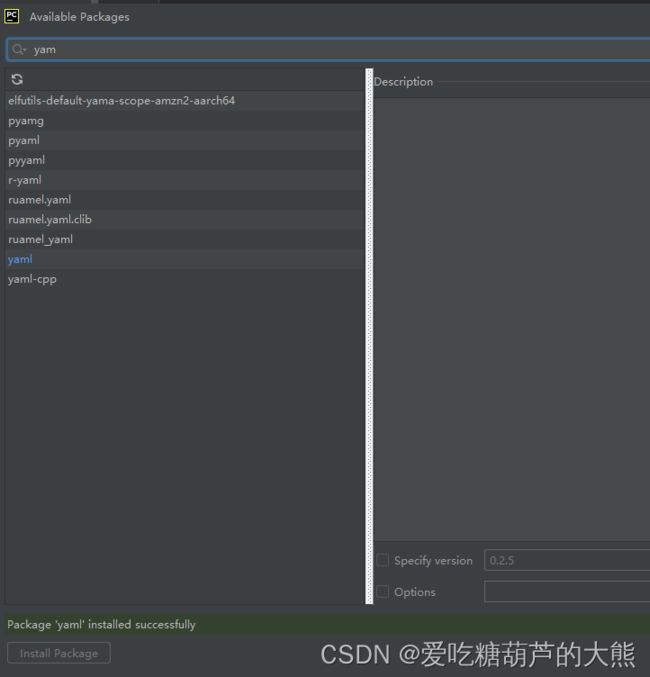
弹出的框搜索yaml和pyymal,然后左下方安装就成功了 。
这是我目前遇到的所有问题,还有其他问题欢迎一起讨论!!!