使用Pytorch训练自己的语义分割网络
什么是语义分割?
- 语义分割是对图像在像素级别上进行分类的方法,在一张图像中,属于同一类的像素点都要被预测为相同的类
- 语义分割是从像素级别来理解图像。
语义分割和实例分割的区别?
- 当一张照片中有多个人时,针对语义分割任务,只需将所有人的像素都归为一类即可,但是针对实例分割任务,则需要将不同人的像素归为不同的类。
- 简单来说,实例分割会比语义分割所做的工作更进一步。
- 下图中左侧为语义分割示意图,右侧为实例分割示例图

训练自己的语义分割网络
本文将基于VGG19网络,搭建、训练和测试自己的全卷积语义分割网络
- 导入本文所需要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import PIL
from PIL import Image
from time import time
import os
from skimage.io import imread
import copy
import time
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
import torch.utils.data as Data
from torch.utils.data import Dataset
from torchvision import transforms
from torchvision.models import vgg19
from torchsummary import summary
- 定义计算设备
本文程序的训练和测试均在GPU上完成,如果未安装GPU版本的Pytorch,请参考文章:https://blog.csdn.net/python_plus/article/details/127870938?spm=1001.2014.3001.5501
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
如果已经安装GPU版本的Pytorch,则会输出下图所示信息
![]()
- 数据准备
- 列出每个物体对应的背景的RGB值以及每个类的RGB值
classes = ['background','aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
colormap = [[0, 0, 0], # 0 = background
[128, 0, 0], # 1 = aeroplane
[0, 128, 0], # 2 = bicycle
[128, 128, 0], # 3 = bird
[0, 0, 128], # 4 = boat
[128, 0, 128], # 5 = bottle
[0, 128, 128], # 6 = bus
[128, 128, 128], # 7 = car
[64, 0, 0], # 8 = cat
[192, 0, 0], # 9 = chair
[64, 128, 0], # 10 = cow
[192, 128, 0], # 11 = dining table
[64, 0, 128], # 12 = dog
[192, 0, 128], # 13 = horse
[64, 128, 128], # 14 = motorbike
[192, 128, 128], # 15 = person
[0, 64, 0], # 16 = potted plant
[128, 64, 0], # 17 = sheep
[0, 192, 0], # 18 = sofa
[128, 192, 0], # 19 = train
[0, 64, 128]] # 20 = tv/monitor
- 定义数据预处理函数
## 将一个标记好的图像转化为类别标签图像
def image2label(image, colormap):
# 将标签转化为每个像素值为一类数据
cm2lbl = np.zeros(256**3)
for i,cm in enumerate(colormap):
cm2lbl[(cm[0]*256+cm[1]*256+cm[2])] = i
# 对一张图像转换
image = np.array(image, dtype="int64")
ix = (image[:,:,0]*256+image[:,:,1]*256+image[:,:,2])
image2 = cm2lbl[ix]
return image2
# 随机裁剪图像
def rand_crop(data,label,high,width):
im_width,im_high = data.size
# 生成图像随机点的位置
left = np.random.randint(0, im_width - width)
top = np.random.randint(0, im_high - high)
right = left + width
bottom = top + high
data = data.crop((left, top, right, bottom))
label = label.crop((left, top, right, bottom))
return data,label
# 单组图像的转换操作
def img_transforms(data, label, high, width, colormap):
# 数据的随机裁剪、将图像数据进行标准化、将标记图像数据进行二维标签化的操作,输出原始图像和类别标签的张量数据
data, label = rand_crop(data, label, high, width)
data_tfs = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
data = data_tfs(data)
label = torch.from_numpy(image2label(label, colormap))
return data, label
# 定义需要读取的数据路径的函数
def read_image_path(root=r"D:\毕业设计\VOC2012\ImageSets\Segmentation\train.txt"):
# 原始图像路径输出为data,标签图像路径输出为label
image = np.loadtxt(root, dtype=str)
n =len(image)
data, label = [None]*n, [None]*n
for i,fname in enumerate(image):
data[i] = r"D:\毕业设计\VOC2012\JPEGImages\%s.jpg" % (fname)
label[i] = r"D:\毕业设计\VOC2012\SegmentationClass\%s.png" % (fname)
return data, label
- 定义数据加载类
# 定义一个MyDataset继承于torch.utils.data.Dataset类
class MyDataset(Dataset):
"""用于读取图像,并进行相应的裁剪等"""
def __init__(self, data_root, high, width, imtransform, colormap):
## data_root:数据所对应的文件名
## high,width:图像裁剪后的尺寸
## imtransform:预处理操作
## colormap:颜色
self.data_root = data_root
self.high = high
self.width = width
self.imtransform = imtransform
self.colormap = colormap
data_list, label_list = read_image_path(root=data_root)
self.data_list = self._filter(data_list)
self.label_list = self._filter(label_list)
def _filter(self, images):
## 过滤掉图片大小小于指定high、width的图片
return [im for im in images if (Image.open(im).size[1]> high and
Image.open(im).size[0]> width)]
def __getitem__(self, idx):
img = self.data_list[idx]
label = self.label_list[idx]
img = Image.open(img)
label = Image.open(label).convert('RGB')
img, label = self.imtransform(img, label, self.high, self.width, self.colormap)
return img,label
def __len__(self):
return len(self.data_list)
- 创建数据加载器,并且每个batch中包含4张图像
# 读取数据
high, width = 320, 480
voc_train = MyDataset(r"D:\VOC2012\ImageSets\Segmentation\train.txt", high, width, img_transforms, colormap)
voc_val = MyDataset(r"D:\VOC2012\ImageSets\Segmentation\val.txt", high, width, img_transforms, colormap)
# 创建数据加载器每个batch使用4张图像
train_loader = Data.DataLoader(voc_train, batch_size=4, shuffle=True, num_workers=0, pin_memory=True)
val_loader = Data.DataLoader(voc_val, batch_size=4, shuffle=True, num_workers=0, pin_memory=True)
# 检查训练数据集的一个batch的样本的维度是否正确
for step,(b_x,b_y) in enumerate(train_loader):
if step > 0:
break
# 输出训练图像的尺寸和标签的尺寸,以及接受类型
print("b_x.shape:",b_x.shape)
print("b_y.shape:",b_y.shape)
输出结果如下图所示:
![]()
- 对一个batch中的4张图片进行可视化
# 将标准化后的图像转化为0-1的区间
def inv_normalize_image(data):
rgb_mean= np.array([0.485, 0.456, 0.406])
rgb_std = np.array([0.229, 0.224, 0.225])
data = data.astype('float32') * rgb_std + rgb_mean
return data.clip(0,1)
# 从预测的标签转化为图像的操作
def label2image(prelabel,colormap):
h,w = prelabel.shape
prelabel = prelabel.reshape(h*w, -1)
image = np.zeros((h*w, 3),dtype="int32")
for ii in range(len(colormap)):
index = np.where(prelabel == ii)
image[index, :] = colormap[ii]
return image.reshape(h,w,3)
# 可视化一个batch的图像,检查数据预处理是否正确
b_x_numpy = b_x.data.numpy()
b_x_numpy = b_x_numpy.transpose(0,2,3,1)
b_y_numpy = b_y.data.numpy()
plt.figure(figsize=(16,6))
for ii in range(4):
plt.subplot(2,4,ii+1)
plt.imshow(inv_normalize_image(b_x_numpy[ii]))
plt.axis("off")
plt.subplot(2,4,ii+5)
plt.imshow(label2image(b_y_numpy[ii],colormap))
plt.axis("off")
plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()
可视化结果如下图所示:

- 网络搭建
- 使用预训练好的VGG19网络作为基础网络
model_vgg19 = vgg19(pretrained=True)
# 不使用VGG19网络后面的AdaptiveAvgPool2d和Linear层
base_model = model_vgg19.features
base_model = base_model.cuda()
summary(base_model,input_size=(3, high, width))
VGG19的网络结构如下图所示:
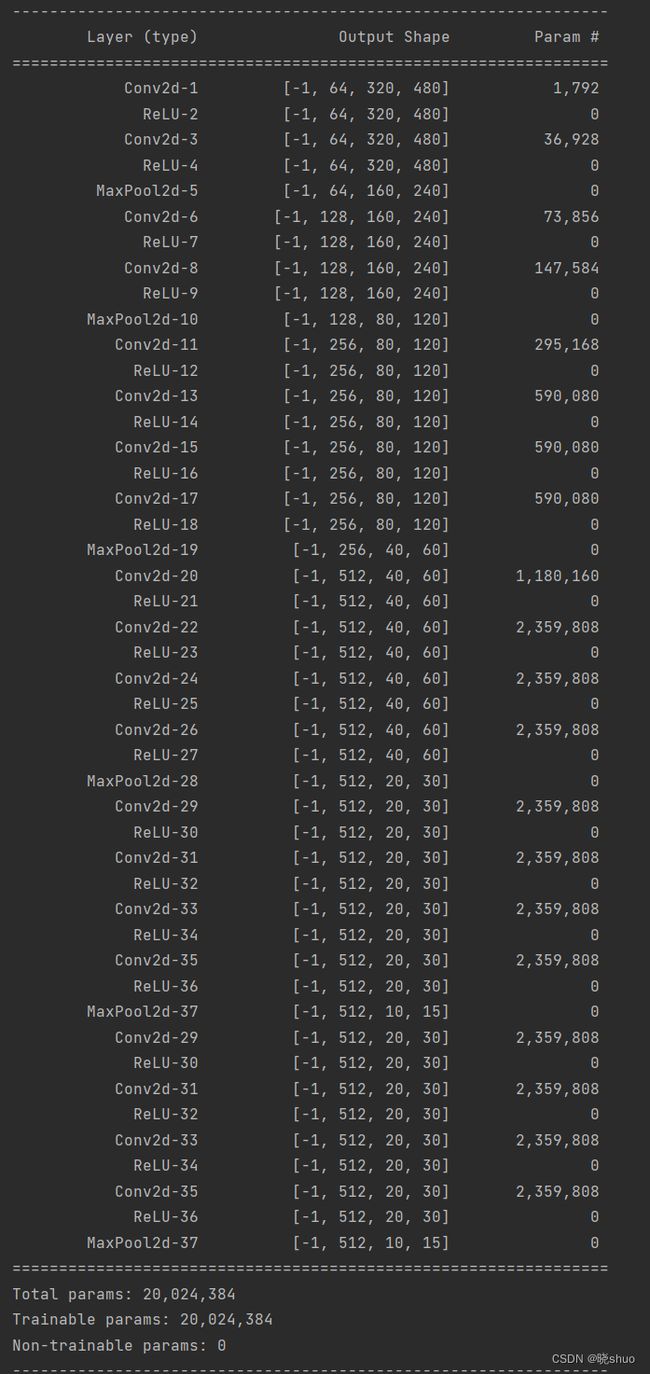
- 定义FCN语义分割网络
class FCN8s(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
model_vgg19 = vgg19(pretrained=True)
# 不使用VGG19网络后面的AdaptiveAvgPool2d和Linear层
self.base_model = model_vgg19.features
# 定义几个需要的层操作,并且使用转置卷积将特征映射进行升维
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, 3, 2, 1, 1, 1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, 3, 2, 1, 1, 1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, 3, 2, 1, 1, 1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, 3, 2, 1, 1, 1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, num_classes, kernel_size=1)
## VGG19中MaxPool2d所在的层
self.layers = {"4":"maxpool_1","9":"maxpool_2",
"18": "maxpool_3", "27": "maxpool_4",
"36": "maxpool_5"}
def forward(self, x):
output ={}
for name, layer in self.base_model._modules.items():
## 从第一层开始获取图像的特征
x = layer(x)
## 如果是layers参数指定的特征,那就保存到output中
if name in self.layers:
output[self.layers[name]] = x
x5 = output["maxpool_5"] ## size = (N, 512, x.H/32, x.W/32)
x4 = output["maxpool_4"] ## size = (N, 512, x.H/16, x.W/16)
x3 = output["maxpool_3"] ## size = (N, 512, x.H/8, x.W/8)
## 对特征进行相关的转置卷积操作,逐渐将图像放大到原始图像大小
## size = (N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv1(x5))
## 对应元素相加,size = (N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4)
## size = (N, 256, x.H/8, x.W/8)
score = self.relu(self.deconv2(score))
## 对应元素相加,size = (N, 256, x.H/8, x.W/8)
score = self.bn2(score + x3)
## size = (N, 128, x.H/4, x.W/4)
score = self.bn3(self.relu(self.deconv3(score)))
## size = (N, 64, x.H/2, x.W/2)
score = self.bn4(self.relu(self.deconv4(score)))
## size = (N, 32, x.H, x.W)
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score ## size = (N, n_class, x.H/1, x.W/1)
fcn8s = FCN8s(21).to(device)
summary(fcn8s, input_size=(3, high, width))
FCN的网络结构如下图所示:
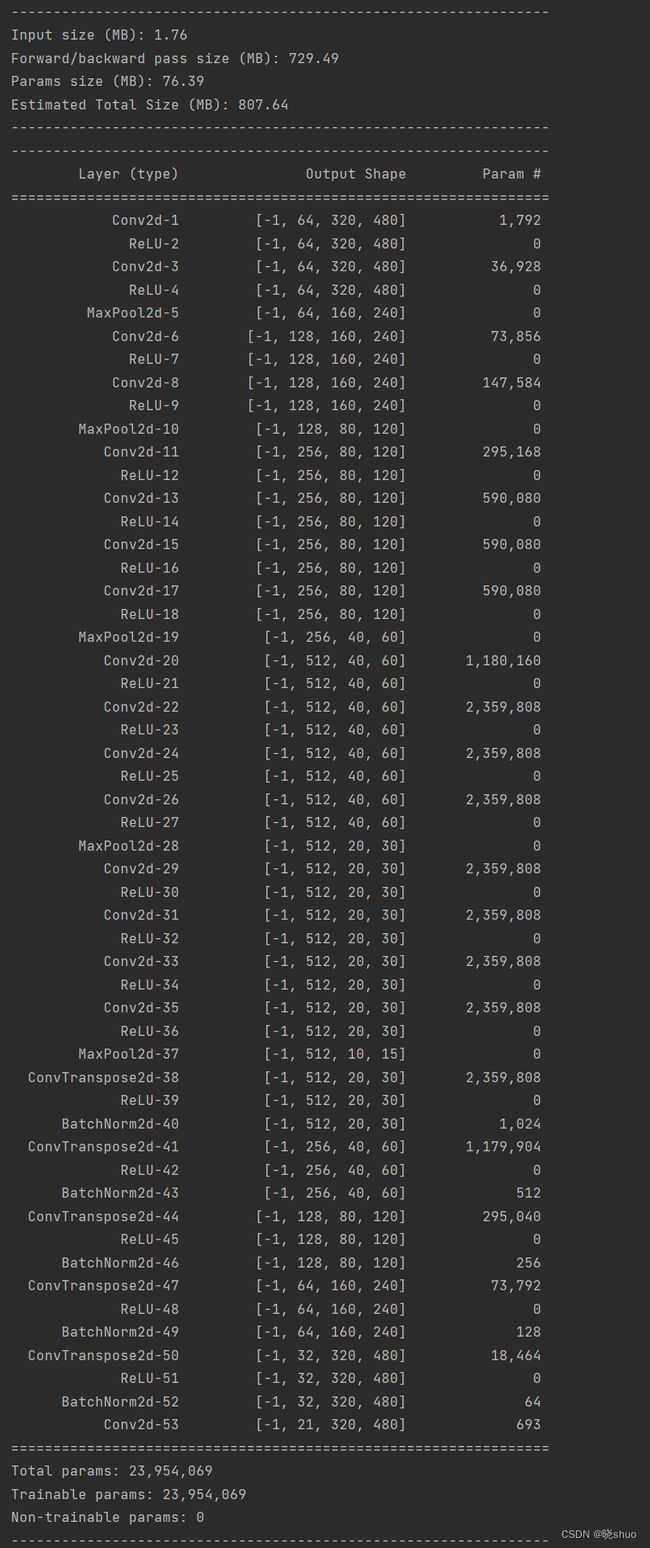
- 网络训练
- 定义训练函数
def train_model(model, criterion, optimizer, traindataloader, valdataloader, num_epochs = 25):
"""
:param model: 网络模型
:param criterion: 损失函数
:param optimizer: 优化函数
:param traindataloader: 训练的数据集
:param valdataloader: 验证的数据集
:param num_epochs: 训练的轮数
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
train_loss_all = []
train_acc_all = []
val_loss_all = []
val_acc_all = []
since = time.time()
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs-1))
print('-' * 10)
train_loss = 0.0
train_num = 0
val_loss = 0.0
val_num = 0
## 每个epoch包括训练和验证阶段
model.train() ## 设置模型为训练模式
for step,(b_x,b_y) in enumerate(traindataloader):
optimizer.zero_grad()
b_x = b_x.float().to(device)
b_y = b_y.long().to(device)
out = model(b_x)
out = F.log_softmax(out, dim=1)
pre_lab = torch.argmax(out,1) ## 预测的标签
loss = criterion(out, b_y) ## 计算损失函数值
loss.backward()
optimizer.step()
train_loss += loss.item() * len(b_y)
train_num += len(b_y)
## 计算一个epoch在训练集上的损失和精度
train_loss_all.append(train_loss / train_num)
print('{} Train loss: {:.4f}'.format(epoch, train_loss_all[-1]))
## 计算一个epoch训练后在验证集上的损失
model.eval() ## 设置模型为验证模式
for step,(b_x,b_y) in enumerate(valdataloader):
b_x = b_x.float().to(device)
b_y = b_y.long().to(device)
out = model(b_x)
out = F.log_softmax(out, dim=1)
pre_lab = torch.argmax(out,1) ## 预测的标签
loss = criterion(out, b_y) ## 计算损失函数值
val_loss += loss.item() * len(b_y)
val_num += len(b_y)
## 计算一个epoch在验证集上的损失和精度
val_loss_all.append(val_loss / val_num)
print('{} Val loss: {:.4f}'.format(epoch, val_loss_all[-1]))
## 保存最好的网络参数
if val_loss_all[-1] < best_loss:
best_loss = val_loss_all[-1]
best_model_wts = copy.deepcopy(model.state_dict())
## 每个epoch花费的时间
time_use = time.time() - since
print("Train and val complete in {:.0f}m {:.0f}s".format(time_use // 60, time_use %60))
train_process = pd.DataFrame(
data = {"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all})
## 输出最好的模型
model.load_state_dict(best_model_wts)
return model,train_process
- 定义损失函数和优化器
LR = 0.0003
criterion = nn.NLLLoss()
optimizer = optim.Adam(fcn8s.parameters(), lr=LR,weight_decay=1e-4)
- 对模型进行迭代训练,对所有的数据训练epoch轮
fcn8s,train_process = train_model(
fcn8s,criterion,optimizer,train_loader,
val_loader, num_epochs=30)
- 保存训练好的模型fcn8s
torch.save(fcn8s,"fcn8s.pt")
运行后,网络开始训练,训练过程如下图所示:
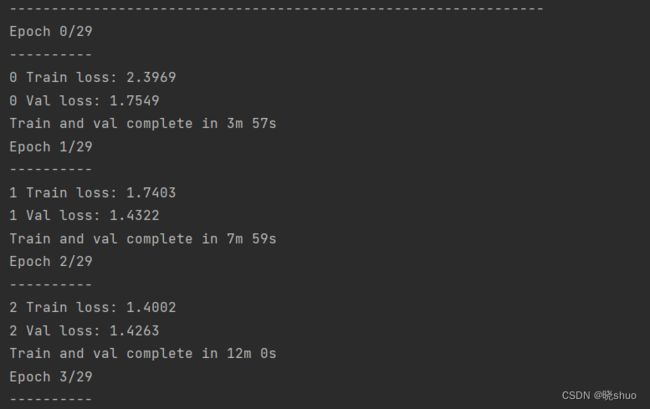
- 网络测试
- 对验证集中一个batch的数据进行预测,并可视化预测效果
fcn8s = torch.load("fcn8s.pt") # 加载模型
fcn8s.eval()
## 对验证集中获取一个batch的数据
for step,(b_x,b_y) in enumerate(val_loader):
if step > 0:
break
## 对验证集中一个batch的数据进行预测,并可视化预测效果
b_x = b_x.float().to(device)
b_y = b_y.long().to(device)
out = fcn8s(b_x)
out = F.log_softmax(out, dim=1)
pre_lab = torch.argmax(out, 1)
## 可视化一个batch的图像,检查数据预处理是否正确
b_x_numpy = b_x.cpu().data.numpy()
b_x_numpy = b_x_numpy.transpose(0,2,3,1)
b_y_numpy = b_y.cpu().data.numpy()
pre_lab_numpy = pre_lab.cpu().data.numpy()
plt.figure(figsize=(16,9))
for ii in range(4):
plt.subplot(3,4,ii+1)
plt.imshow(inv_normalize_image(b_x_numpy[ii]))
plt.axis("off")
plt.subplot(3,4,ii+5)
plt.imshow(label2image(b_y_numpy[ii],colormap))
plt.axis("off")
plt.subplot(3,4,ii+9)
plt.imshow(label2image(pre_lab_numpy[ii],colormap))
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0.05)
plt.show()
模型测试结果如下图所示,第一行为原始图片,第二行为原始图像的标签,第三行为网络对图像的分割结果,由于训练的epoch非常少,只有10个epoch,因此分割效果很差。
我这里由于时间原因就不训练太多个epoch了,大家自己练习的时候可以增加epoch到200-300,分割效果应该会好很多。
