KG4Py:Python代码知识图谱和语义搜索的工具包
如何构建Python的代码知识图谱,又该如何进行搜索呢?

现在的项目程序中存在着大量重复的代码片段,尤其是在软件开发的时候。在本文中,我们提出了一个工具包(KG4Py),用于在GitHub存储库中生成Python文件的知识图谱,并使用知识图谱进行语义搜索。在KG4Py中,我们删除了31.7万个Python文件中的所有重复文件,并通过使用具体语法树(CST)构建Python函数的代码知识图谱来执行这些文件的静态代码分析。我们将预先训练的模型与无监督模型集成后生成新模型,并将该新模型与代码知识图谱相结合,方便搜索具有自然语言描述的代码片段。实验结果表明,KG4Py在代码知识图谱的构建和代码片段的语义搜索方面都取得了良好的性能。
01 简介
软件可重用性(Software reusability)是软件工程的重要组成部分。软件重用不仅减少了软件开发中的重复工作,还提高了项目开发的质量(Wang等人,2019)。软件重用的核心是重复代码片段的利用,而代码搜索正好解决了这个问题。传统的代码搜索主要基于关键词,无法挖掘搜索语句的深层语义信息。目前,在GitHub上搜索代码片段仅限于关键字搜索,这是基于用户能够预测他们正在查找的代码片段相关的关键字来完成的。但是,这种方法的可移植性和可解释性较差,无法对代码片段进行语义搜索。出于这些原因,我们尝试引入知识图谱来解决代码语义搜索中面临的各种挑战。
知识图谱(KG)于2012年由谷歌正式引入,它是物理世界的符号表示,是描述真实世界实体(人、对象、概念)的图,以及由实体和关系连接的网络式知识库。近年来,建立了许多不同的知识图谱,如Freebase(Kurt等人,2008)、YAGO(Manu等人,2012)、Wikidata(Denny&Markus,2014)和OpenKG(Chen等人,2021)。这些知识图谱为不同领域的人们带来了便利,例如搜索引擎(Zhao等人,2021)、推荐系统(Arul&Razia,2021;Xie等人,2021;Yu等人,2020)、智能问答(Zhang等人,2018)和决策分析(Hao等人,2021;Joiao等人,2020年)。
受这些知识图谱的启发,研究人员思考了如何在软件工程中构建知识图谱。代码的大数据为知识图谱构建提供了数据源,基于深度学习的方法为自动知识图谱构建(Wang等人,2020a)提供了帮助。
随着开源软件在过去几年的发展,越来越多的软件项目出现在GitHub、Gitlab和Bitbucket等主要代码托管平台上。为了利用这些源代码、API、文档等,研究人员在软件领域构建了各种知识图谱。Meng等人(2017)构建了用于自动分析的Android应用程序知识图谱。Wang等人(2020b)使用维基百科分类法构建软件开发知识图谱。受这些知识图谱的启发,我们思考了如何创建Python函数的知识图谱。
对于知识图谱搜索系统,我们可以挖掘更多关于我们想要什么的隐藏信息。Wang等人(2019)提出并实现了用于项目中自然语言查询的基于知识图谱的界面。它从知识库中提取元模型并构建与问题相关的推理子图,然后自动将自然语言问题转换为结构化查询语句并返回相关答案。这也为我们的代码语义搜索提供了灵感。
对于图数据库的选择,知识图谱通常使用Neo4j、GraphDB和其他图数据库来存储数据,并使用特定语句来检索数据。在本文中,我们选择Neo4j来存储数据,因为它支持丰富的语义标记描述,它读写数据更快,具有可读的查询语句,并且还容易表示半结构化数据。这为我们提供了构建代码知识图谱和代码语义搜索的可能性。
KG4Py:Python代码知识图谱和语义搜索的工具包如何构建Python的代码知识图谱,又该如何进行搜索呢? https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500976&idx=2&sn=c3fd09b482fe541e8c93d1b8ef5b3bed&chksm=f9e650b5ce91d9a3e0bb7312eed6feadeceb8949e786c13f59326805373ac324c7c9078250c2&token=1811512605&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500976&idx=2&sn=c3fd09b482fe541e8c93d1b8ef5b3bed&chksm=f9e650b5ce91d9a3e0bb7312eed6feadeceb8949e786c13f59326805373ac324c7c9078250c2&token=1811512605&lang=zh_CN#rd
02 模型介绍
2.1 代码知识图谱构建
在构建代码知识图谱之前,我们需要对Python文件进行代码解析。我们使用LibCST1(Python的具体语法树解析器和序列化程序库)来解析代码,而不是抽象语法树(AST)。AST在保留原始代码的语义方面做得很好,并且树的结构相对简单。但是,代码的许多语义很难理解和提取。如果只有AST,就不可能重新输出原始源代码。像JPEG一样,AST是有损的,它无法捕获我们留下的注释信息。具体语法树(CST)保留了足够的信息来重新输出准确的输入代码,但很难实现复杂的操作。LibCST在上述两种格式之间进行了折衷。与AST一样,LibCST将源代码解析为表示代码片段语义的节点。与CST一样,LibCST保留所有注释信息,并且可以准确地重新输出。AST、CST和LibCST之间代码分析的差异如图1所示。
 图1 AST、CST和LibCST之间代码分析的差异
图1 AST、CST和LibCST之间代码分析的差异
我们使用LibCST对Python文件进行静态代码分析,并确定每个文件中的“import”、“class”和“function”。对于每个函数,我们还需要确定其参数、变量和返回值。为了使搜索结果更准确,我们使用codeT5(Wang等人,2021)模型为每个函数生成描述,这类似于文本总结(Fang等人,2020;Lin等人,2022)。最后,我们将它们保存在JSON格式的文件中。我们的Pipeline如图2所示。
 图2 静态代码分析和功能摘要Pipeline
图2 静态代码分析和功能摘要Pipeline
我们从处理过的JSON格式文件中提取相关实体和属性,并使用它们构建代码知识图谱。
2.2 基于知识图谱的搜索系统
2.2.1 模型中的语义搜索
传统的搜索引擎只通过匹配关键词来检索答案,而语义搜索系统通过分割和理解句子来检索答案。在语义搜索之前,数据库中的问题和答案被嵌入到向量空间中。在搜索时,我们将分割和解析的问题嵌入到同一向量空间中,并计算向量之间的相似度,以显示具有高相似度的答案。接下来,我们介绍语义搜索模型的选择。
研究人员已经开始将单个句子输入BERT(Devlin等人,2018),并导出固定大小的句子嵌入。Bert模型在所有主要的自然语言处理(NLP)任务中都表现出了强大的作用。在语义相似度计算任务中也不例外。然而,BERT模型规定,在计算语义相似度时,需要同时将两个句子输入到模型中以进行信息交互,这导致了较大的计算成本。
因此,我们选择并微调Sentence-BERT(Reimers&Gurevych,2019)模型来执行代码语义搜索,如图3所示。简单概括地说,它借鉴了孪生网络模型的框架,将不同的句子输入到两个BERT模型中(但这两个BERT模型共享参数,也可以理解为相同的BERT模型),以获得每个句子的句子表示向量,并且所获得的最终句子表示向量可以用于语义相似度计算或无监督聚类任务。对于同样的10000个句子,我们只需要计算10000次就可以找到最相似的句子对,这大约需要5 s来完全计算它们,而BERT大约需要65 小时。
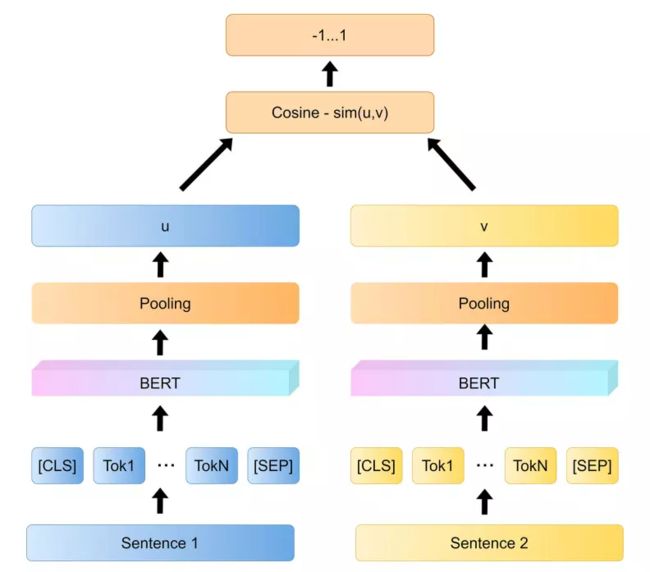 图3 Sentence-BERT模型
图3 Sentence-BERT模型
2.2.2 语义搜索模型中的编码器
我们使用最大值池策略(the maximum value pooling strategy),即通过BERT模型使句子中的所有单词向量最大化。最大向量被用作整个句子的句子向量。
对于Cross-encoders,它们通过充分的self-attention来连接问题和答案,因此它们比双编码器更准确。Cross-encoders需要花费大量时间来计算每个问题和答案之间的上下文关系,而双编码器通过单独编码节省了大量时间。此外,当问题和答案的数量很大时,Cross-encoders不会进行压缩。因此,我们使用它来解析查询语句。Cross-encoders的结构如图4所示
 图4 Cross-encoders结构
图4 Cross-encoders结构
我们使用双编码器分别对输入和候选标签执行self-attention,将它们映射到密集的向量空间,在最后将它们组合获得最终表示。Bi-encoders能够对编码的候选进行索引,并对每个输入比较这些表示,从而加快预测时间。时间从65小时(使用Cross-encoders)缩短至约5秒。因此,我们将其与无监督方法相结合,以训练无标签问答对。Bi-encoders的结构如图5所示。
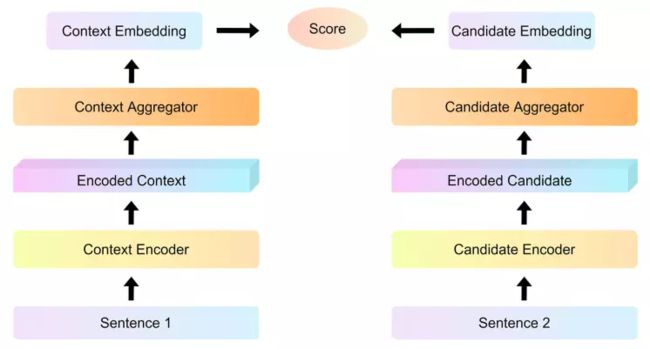 图5 Bi-encoders 结构
图5 Bi-encoders 结构
2.2.3 编码器分布
对于回归任务,例如不对称语义搜索,我们计算句子嵌入u、v和相应句子对的余弦相似度,然后将它们乘以可训练权重。我们使用均方误差(MSE)损失作为目标函数:
![]()
在非对称语义搜索中,用户提供一些关键字或问题之类的查询,但希望检索提供答案的长文本段落(Do&Nguyen,2021)。因此,我们使用无监督学习方法来解决非对称语义搜索任务,例如使用自然语言描述来搜索代码片段。这些方法的共同点是不需要标记的训练数据。相反,他们可以从文本本身学习语义上有意义的句子嵌入。Cross-encoders仅适用于重新排列一小组自然语言描述。为了从大量集合中检索合适的自然语言描述,我们必须使用双编码器。这些查询和描述被独立地编码为同一向量空间中的固定大小嵌入。然后可以通过计算向量之间的距离来找到相关的自然语言描述。因此,我们将双编码器与无监督方法相结合,训练无标签代码搜索领域的任务,使用Cross-encoders接收用户输入,并计算问题与自然语言描述之间的余弦相似度。
03 实验结果
 图6 代码知识图谱的部分展示
图6 代码知识图谱的部分展示
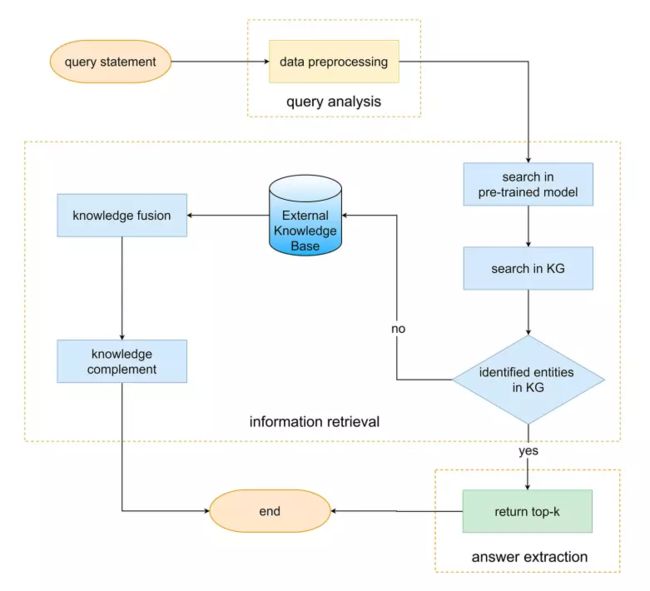 图7 搜索模型的流程图
图7 搜索模型的流程图
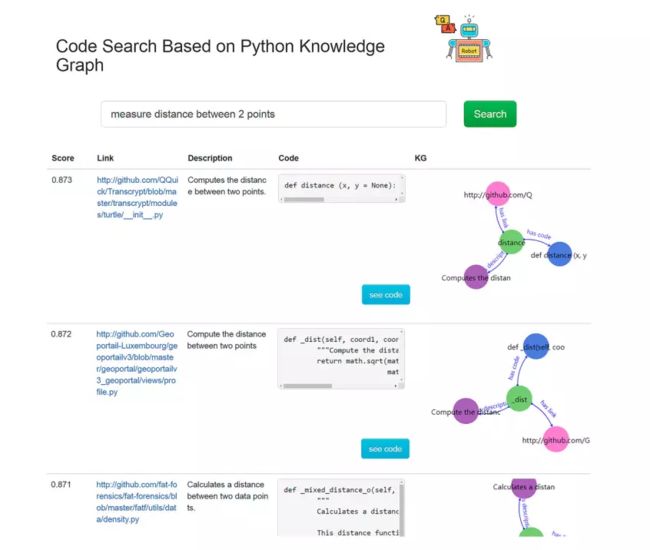 图8 知识图谱的搜索结果
图8 知识图谱的搜索结果
 表1 模型中搜索结果和用时(部分)
表1 模型中搜索结果和用时(部分)
04 总结
本文的主要工作是通过构建有关Python函数的知识图谱来对代码片段进行语义搜索。在代码分析阶段,我们在 GitHub 中发现了大量重复的代码片段,这不仅造成了资源的浪费,还增加了软件公司的开发成本。这些问题可以通过我们的工具包轻松解决,我们工具包的工业价值可以分为两部分:
-
对于个人开发人员,我们的工具包不仅可以用于搜索代码,还可以通过我们的代码知识图谱加深对代码片段的理解。
-
对于软件公司,我们的工具包可用于通过理解函数注释的语义来查找企业代码库中的类似代码片段,并推荐给开发人员(如果存在)。这样,不仅减少了开发人员工作的重复,而且降低了软件公司的开发成本。
未来,我们会将函数的数据流和控制流集成到代码知识图谱中,让用户对函数有更深入的了解。对于语义搜索,问题检索和匹配的速度仍有提高空间。我们将深入研究这些问题,希望以更简单的方式解析查询语句,同时减少搜索模型的检索时间。
精彩推荐
-
知识图谱问答领域综述
-
172篇 | COLING 2022论文集
-
CCKS2022 -《知识图谱发展报告(2022)》
-
融合图注意力机制与预训练语言模型的常识库补全
-
COLING 2022 | 角色感知的渐进式谣言判别框架
-
COLING 2022 | 将基于梯度相似度的自适应元学习方法用于小样本文本分类